ทวีตที่ปักหมุด

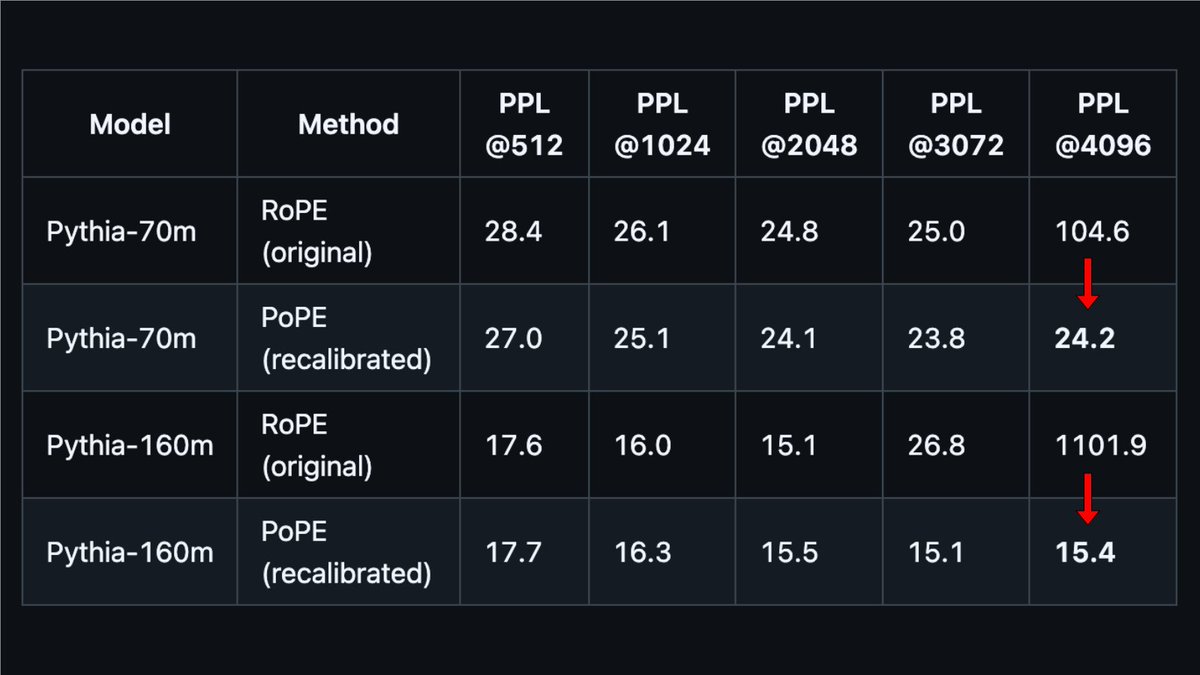
Our new paper shows that RoPE—the positional encoding used in most modern LLMs like Qwen, Gemma, DeepSeek—has a fundamental flaw: it entangles "what" (content) and "where" (position) information.
Our fix (PoPE) is simple but powerful. Paper: arxiv.org/abs/2509.10534
English