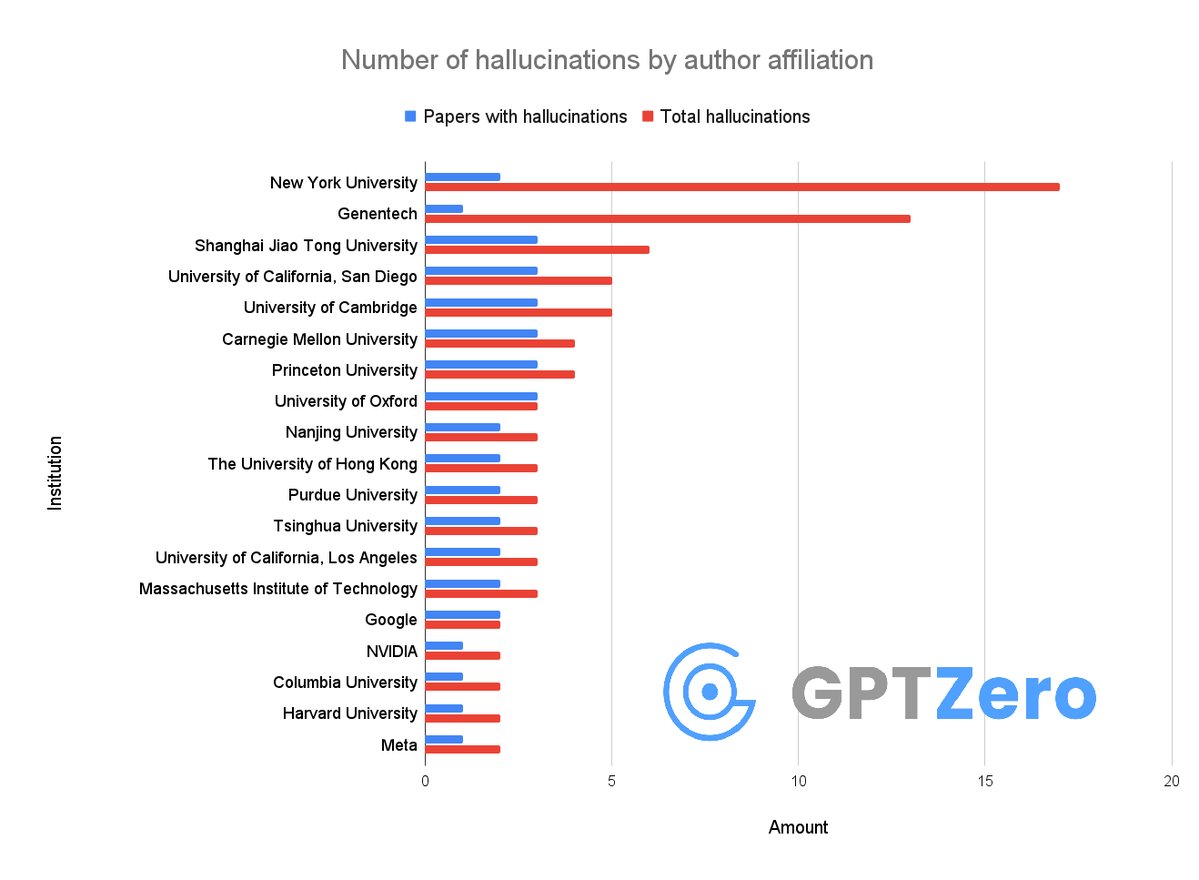
ทวีตที่ปักหมุด

Excited to share what I worked on during my time at Meta.
- We introduce a Triton-accelerated Transformer with *2-simplicial attention*—a tri-linear generalization of dot-product attention
- We show how to adapt RoPE to tri-linear forms
- We show 2-simplicial attention scales better under token constraints than dot product attention
It was fun collaborating with amazing folks including @dvsaisurya @_arohan_ and others

English