ทวีตที่ปักหมุด

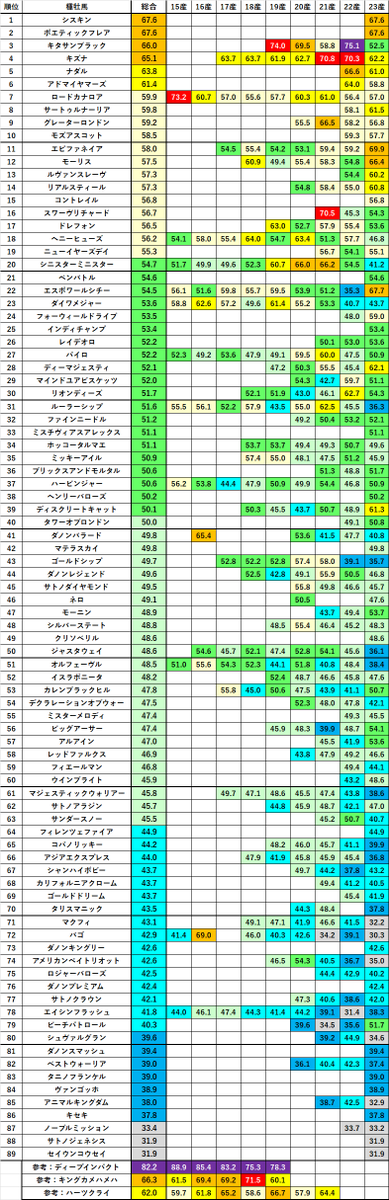
【種牡馬通信簿(2025年末版)】
恒例のやつ
・コントレイルはどう評価すればよいの?
・ナダル2年目はどうよ?
・エピファネイアって23産が大活躍しているけど買いなの?
その疑問に答えが出るかも!?
詳しくはブログにて。ひとまず結論の表だけ置いておきます。
ameblo.jp/xenogs2491/ent…
日本語
バッタ
6.9K posts

@drosshopper01
シルクを中心に、キャロット、ウインで一口馬主やってます。ブログもやってたりします。 過去東サラ、ノルマンディ、グリーン








あ、そういえばセレクトセールのリストに、それシルクのだろ!!って文句つける儀式まだやってなかった。

ついに、、、あとはデータを集めるだけ。