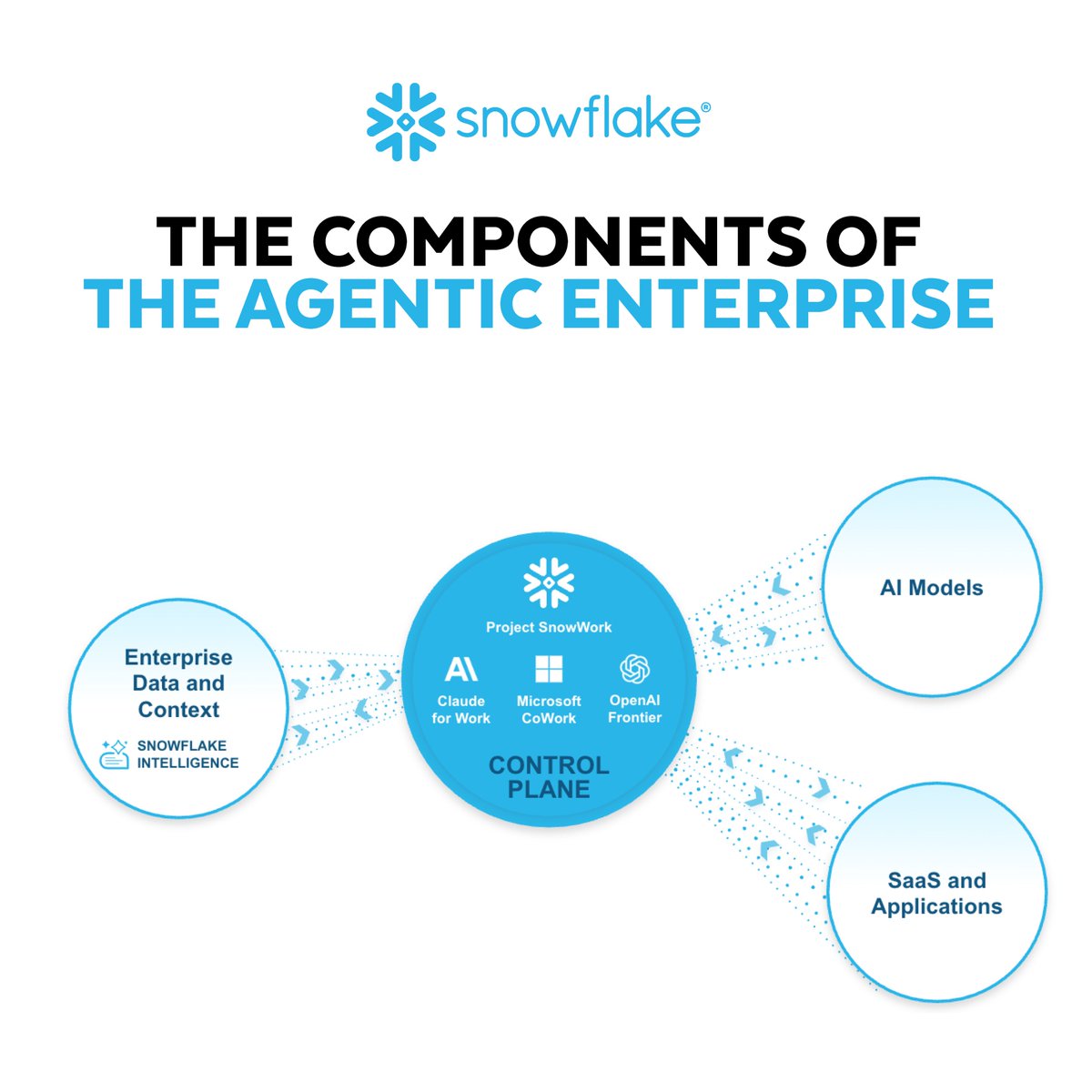
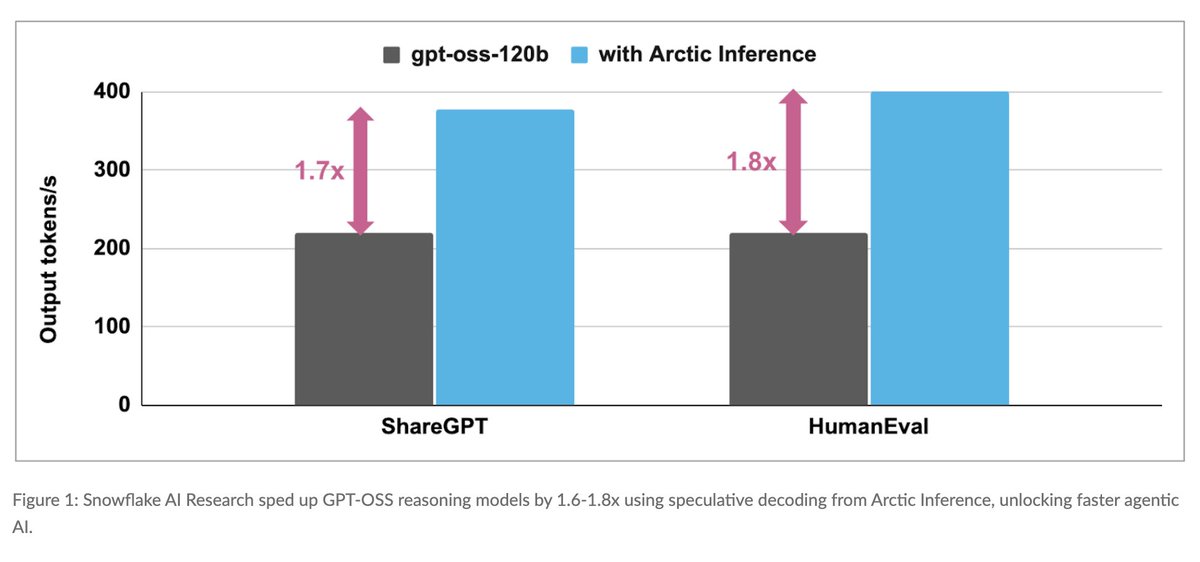
We’re seeing a clear shift in how teams build with AI, moving from isolated assistance to deeply integrated, agentic workflows.
With @Snowflake's latest updates to Cortex Code, we’re making that shift tangible.
❄️Cortex Code is now generally available in Snowsight, with a persistent AI coding agent embedded directly in the data workflow.
💻Cortex Code CLI now supports Windows, expanding access for developers working across different environments.
🤖Agent Teams enable coordination of complex, multi-step tasks by running work in parallel.
The result: faster iteration, tighter feedback loops, and the ability to take on significantly more ambitious data and AI workloads, without adding complexity.
Read more in the blog post below:
snowflake.com/en/blog/cortex…
English