ทวีตที่ปักหมุด

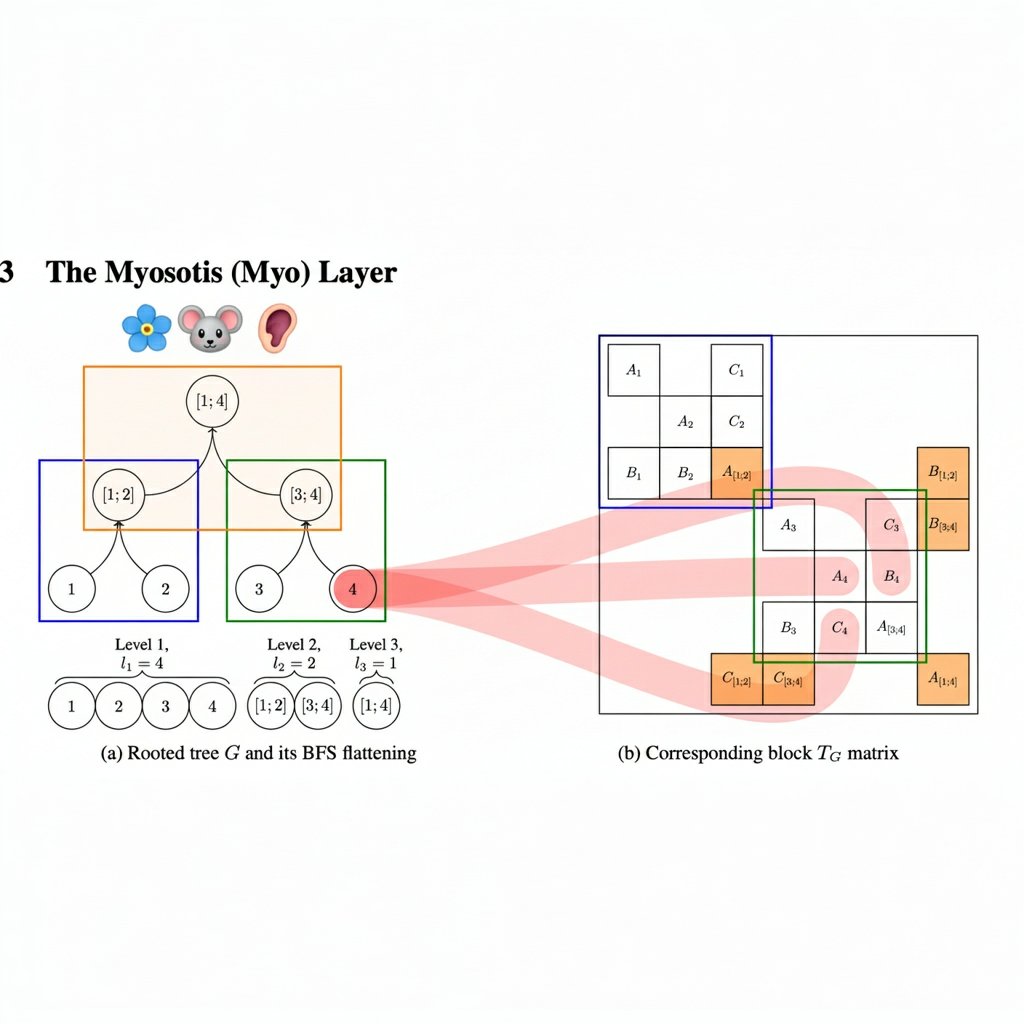
An interlude about structure computation, SSM and attention. Myosotis: arxiv.org/abs/2509.20503
I hope to tell more in this line of work later. See poster at SPIGM workshop.
English
Evgenii Egorov
1.7K posts


Transformers are Bayesian Networks arxiv.org/abs/2603.17063



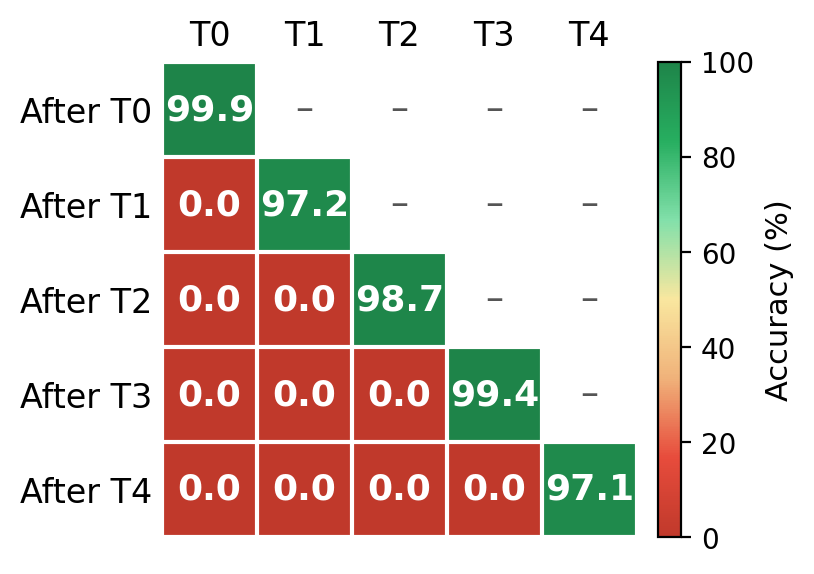

Large Ithkuil model when






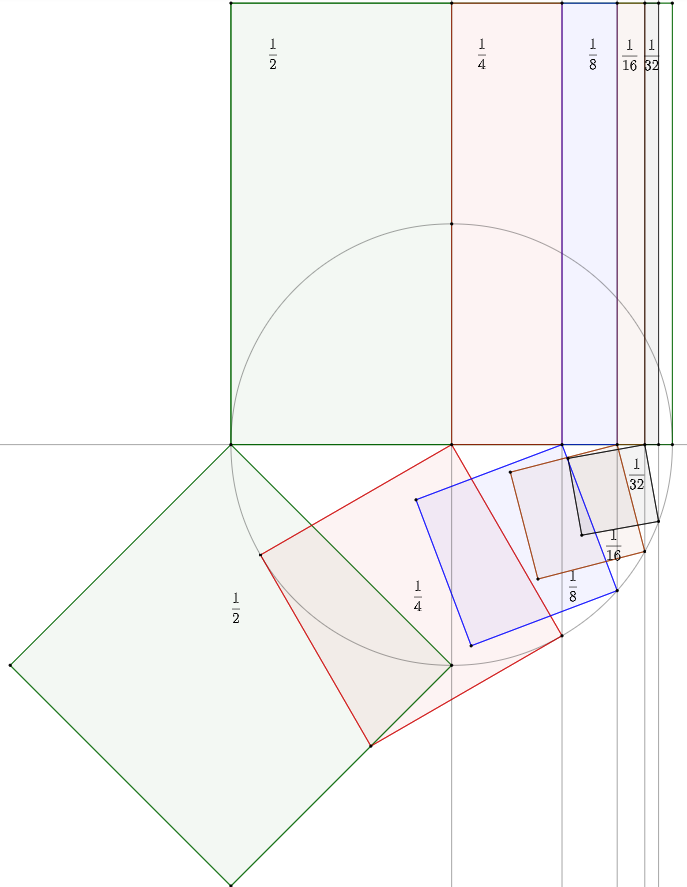



European academia 2010-2026


