giodegas
14.2K posts

giodegas รีทวีตแล้ว

giodegas รีทวีตแล้ว

SnapBot isn’t just a legged robot: it’s a shape-shifting machine
via @IlirAliu_
#Robotics #ArtificialIntelligence #MachineLearning #AI #DeepLearning
cc: @kuriharan @miketamir @theadamgabriel
English
giodegas รีทวีตแล้ว

Yesterday, we released MedGemma a open medical vision-language model for Healthcare! Built on @GoogleDeepMind Gemma 3 it advances medical understanding across images and text, significantly outperforming generalist models of similar size. MedGemma is one of the best open model under 50B!
How MedGemma Was Trained:
1️⃣ Fine-tuned Gemma 3 vision-encoder (SigLIP) on over 33 million medical image-text pairs (radiology, dermatology, pathology, etc.) to create the specialized MedSigLIP, including some general data to prevent catastrophic forgetting.
2️⃣ Further pre-trained Gemma 3 Base by mixing in the medical image data (using the new MedSigLIP encoder) to ensure the text and vision components could work together effectively.
3️⃣ Distilling knowledge from a larger "teacher" model, using a mix of general and medical text-based question-answering datasets.
4️⃣ Reinforcement Learning similar to Gemma 3 on medical imaging and text data, RL led to better generalization than standard supervised fine-tuning for these multimodal tasks.
Insights:
- 💡 Outperforms Gemma 3 on medical tasks by 15-18% improvements in chest X-ray classification.
- 🏆 Competes with, and sometimes surpasses, much larger models like GPT-4o.
- 🥇 Sets a new state-of-the-art for MIMIC-CXR report generation.
- 🩺 Reduces errors in EHR information retrieval by 50% after fine-tuning.
- 🧠 The 27B model outperforms human physicians in a simulated agent task.
- 🤗 Openly released to accelerate development in healthcare AI.
- 🔬 Reinforcement Learning was found to be better for multimodal generalization.

English
@sole24ore @FabioTamburini2 Direttore, ho ascoltato la sua intervista su Radio24 sul programma di credito fiscale #SuperBonus110 . Se le può interessare, abbiamo appena pubblicato un articolo scientifico che dimostra come renderlo immune da imbrogli mdpi.com/2076-3417/14/2…
Italiano
giodegas รีทวีตแล้ว


giodegas รีทวีตแล้ว

Musk’s DOGE involved in what appears to be a foreign espionage operation and data theft. They also have death threatened US federal whistleblowers and disabled security systems, deliberately allowing Russian IPs to access sensitive US federal government systems.
npr.org/2025/04/15/nx-…



English
giodegas รีทวีตแล้ว

The Art of Replication: Lifelike Avatars with Personalized Conversational Style mdpi.com/3222352 #mdpirobotics via @RoboticsMDPI
English
giodegas รีทวีตแล้ว

I'm designing a modular and easily repairable open-source Linux smartwatch. This system is based on the open-source SiP I've designed and will be able to run custom firmware in a Linux and Android environment




English
giodegas รีทวีตแล้ว

Graph-powered RAG system LightRAG, proposed in this paper, builds knowledge graphs on-the-fly to fix RAG's context blindness
Original Problem 🔍:
Current Retrieval-Augmented Generation (RAG) systems struggle with flat data representations and lack contextual awareness, leading to fragmented answers that fail to capture complex interdependencies between topics.
-----
Solution in this Paper 🛠️:
• LightRAG introduces graph-based text indexing with dual-level retrieval paradigm
• Uses LLMs to extract entities and relationships from text chunks
• Implements dual-level retrieval: low-level for specific entities and high-level for broader themes
• Features incremental update algorithm for seamless integration of new data
• Combines graph structures with vector representations for efficient entity retrieval
-----
Key Insights from this Paper 💡:
• Graph structures excel at representing complex interdependencies between entities
• Dual-level retrieval enhances both specific and abstract information gathering
• Incremental updates eliminate need for complete index rebuilding
• Vector-based entity retrieval reduces overhead compared to community-based traversal
• Original text can be omitted without significant performance loss
-----
Results 📊:
• Outperforms baselines across all datasets, especially in Legal domain (82.54% win rate)
• Shows superior diversity metrics (89.02% in Legal dataset)
• Demonstrates better comprehensiveness (80.95% vs baselines' ~20%)
• Achieves significant efficiency gains with reduced API calls and token usage
• Maintains performance while handling incremental updates

English
giodegas รีทวีตแล้ว
Knowledge graphs meet vector stores.
RAG framework achieves 97% accuracy on domain questions by mixing structured and unstructured knowledge
Original Problem 🔍:
LLMs excel in general NLP tasks but struggle with domain-specific queries, facing issues like hallucinations, knowledge cut-offs, and lack of attribution.
-----
Solution in this Paper 🛠️:
• SMART-SLIC framework integrates Retrieval Augmented Generation (RAG) with domain-specific Knowledge Graph (KG) and Vector Store (VS)
• Uses nonnegative tensor factorization for dataset creation and dimension reduction
• Implements a ReAct agent for general inquiries and NER for document-specific questions
• Incorporates citation mechanisms for information attribution
-----
Key Insights from this Paper 💡:
• Domain-specific KG and VS improve LLM accuracy without extensive fine-tuning
• Tensor factorization with automatic model determination enhances topic classification
• Chain-of-thought prompting with LLM agents boosts reasoning capabilities
• Integration of structured (KG) and unstructured (VS) information enhances response quality
-----
Results 📊:
• Document-specific questions: SMART-SLIC achieved 97% accuracy vs 20% for GPT-4 without RAG
• Topic-based questions: SMART-SLIC answered 92% correctly vs 27.77% for GPT-4 without RAG
• SMART-SLIC attempted 100% of questions, while GPT-4 without RAG abstained from 40-64% of questions
• SMART-SLIC provided accurate DOI citations for complex queries, which GPT-4 without RAG couldn't do

English
giodegas รีทวีตแล้ว
RAGCache slashes LLM response times by remembering previously retrieved document states across multiple user queries
Stop computing twice: RAGCache remembers document states to make RAG lightning quick
Original Problem 🎯:
RAG systems face performance bottlenecks due to long sequence generation when injecting retrieved documents into requests. This causes high computation and memory costs, as retrieved documents can add 1000+ tokens to a 100-token request.
-----
Solution in this Paper 🔧:
• RAGCache introduces a multilevel dynamic caching system that caches intermediate states of retrieved documents across multiple requests
• Uses a knowledge tree structure to organize cached states in GPU and host memory hierarchy
• Implements prefix-aware Greedy-Dual-Size-Frequency (PGDSF) replacement policy considering document order, size, frequency and recency
• Features dynamic speculative pipelining to overlap retrieval and inference steps
• Includes cache-aware request scheduling to improve hit rates under high load
-----
Key Insights 💡:
• A small fraction of documents (3%) accounts for majority (60%) of retrieval requests
• Caching intermediate states can reduce prefill latency by up to 11.5x
• Document order sensitivity in RAG requires special handling in caching
• GPU-host memory hierarchy can be effectively leveraged for caching
• Vector retrieval and LLM inference can be overlapped for better latency
-----
Results 📊:
• Reduces time to first token (TTFT) by up to 4x compared to vLLM with Faiss
• Improves throughput by up to 2.1x over vLLM with Faiss
• Achieves up to 3.5x lower TTFT compared to SGLang
• Delivers up to 1.8x higher throughput than SGLang
• Maintains performance gains across different models and retrieval settings

English
giodegas รีทวีตแล้ว

3DTopia AI: This text-to-3D model can create an entire film scene in just minutes!
3D AI is progressing faster than ever!
I truly believe AI Powered 3D will become the ultimate tool for AI filmmaking. We’ll finally have full creative controls without consistency issues.
We’re not quite there yet, but we’re getting closer every day.
English
giodegas รีทวีตแล้ว

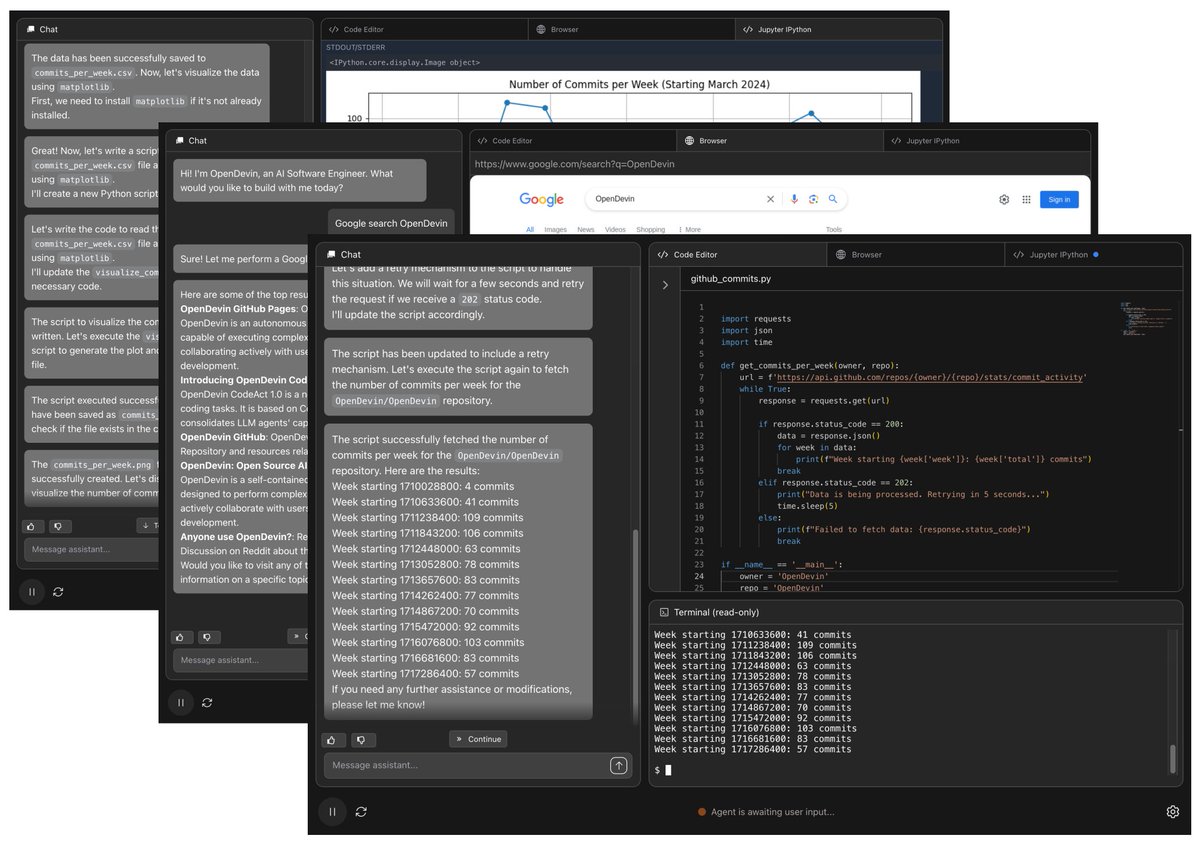
OpenHands (formerly OpenDevin) is currently the top trending repo on Github.
It's a Devin clone that aims to make coding fully AI-powered.
Have you given it a try?
English
giodegas รีทวีตแล้ว
MASSIVE 🤯
First dedicated transformer ASIC (Application-Specific Integrated Circuit) just dropped
Custom chip burns transformer architecture directly into silicon, making AI models run 10x faster than GPUs
What is Sohu 👨🔧 ?
- Hardware architecture specifically optimized for transformer neural networks
- Processes AI models 10x faster and cheaper than GPUs
- Achieves >500,000 tokens/second throughput
⚡ Technical Capabilities
- Multicast speculative decoding
- Single core architecture
- Real-time content generation
- Parallel processing of hundreds of responses
- Beam search and MCTS (Monte Carlo Tree Search) decoding
- Supports MoE (Mixture of Experts) and transformer variants
🎯 Practical Applications
- Real-time voice agents processing thousands of words in milliseconds
- Advanced code completion with tree search
- Parallel comparison of hundreds of model responses
- Real-time content generation at scale
🔬 Core Specifications
- 144 GB HBM3E memory per chip
- Expansible to 100T parameter models
- Fully open-source software stack
- Outperforms NVIDIA 8xH100 and 8xB200 in LLaMA 70B throughput
Think of it as custom-built highways for AI instead of regular roads used by other computers

English
giodegas รีทวีตแล้ว


giodegas รีทวีตแล้ว
AI is making big moves in the 3D industry!
@meshcapade just launched their Text-to-3D Movement tool, which lets us customize character shapes and animate them using simple text prompts.
No more tedious rigging, mapping, or frame-by-frame animation!
English
giodegas รีทวีตแล้ว

Physical Intelligence's π₀, a general-purpose robot foundation model that combines Internet-scale vision-language pretraining with robot interaction data to execute tasks.
They aim "to develop foundation models that can control any robot to perform any task"
Autonomous demos:
English