Jaskaran Singh รีทวีตแล้ว

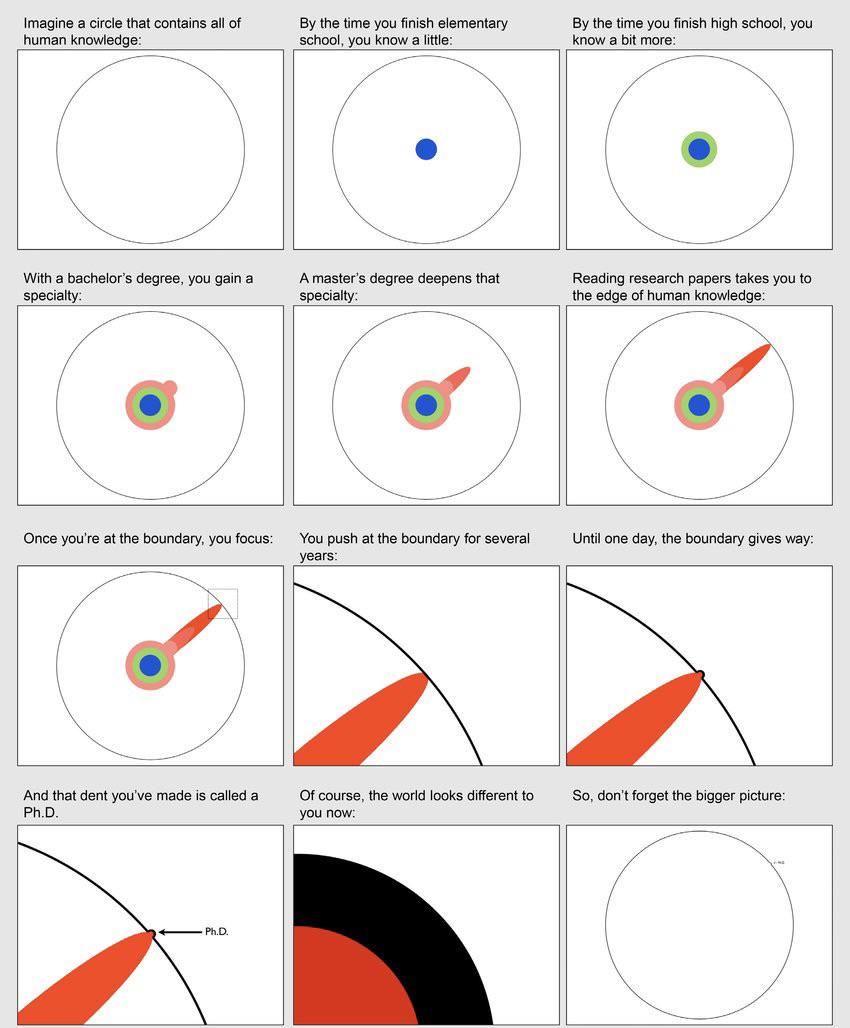
Terence Tao: "Previously, you needed a PhD to contribute to math research. Now a high school student can."
Dwarkesh asks the world's most famous mathematician: what's your advice for someone considering a career in math, especially in light of AI progress?
Tao is honest about uncertainty:
"We live in a time of change. A particularly unpredictable era. Things that we've taken for granted for centuries may not hold anymore. The way we do everything... not just mathematics... will change."
He admits his preference:
"In many ways, I would prefer a much more boring, quiet era where things are much the same as they were 10 or 20 years ago. But one just has to embrace this. There's going to be a lot of change. The things you study... some of them may become obsolete or revolutionized. But some things will be retained."
On new opportunities:
"Previously, you had to go through years and years of education and get a math PhD before you could contribute to the frontier of math research. But now it's quite possible at the high school level that you could get involved in a math project and actually make a real contribution... because of all these AI tools and Lean and everything else."
His advice:
"There will be a lot of non-traditional opportunities to learn. You need a very adaptable mindset. There'll be worth pursuing things just for curiosity and for playing around.
Still go through traditional education and learn math and science the old-fashioned way for a while... credentials will still be important. But you should also be open to very, very different ways of doing science. Some of which don't exist yet."
He concludes:
"It's a scary time. But also very exciting."
English