
Mapped Memgraph's dependency structure as 3 graphs: CMake, Ninja, and Conan. Useful split for finding architecture coupling, rebuild chokepoints, and third-party package risk in a large C++ codebase.
memgraph.com/blog/understan…
English
Marko Budiselić
381 posts
@mbudiselicbuda
Computer scientist, software engineer and entrepreneur.
We built the Graph of public skills -> skillinsight.io From a non-technical standpoint, Agent Skills are the procedural memory you keep in your head on how to solve a particular problem, which can be very valuable, whether you are aware of that or not. You are constantly adapting and changing that procedural memory since the task is usually not fully deterministic, hence it cannot be a script. Parallel to that, skills have caused some controversy for being a security vulnerability and hallucinated LLM brain fog, but more on that in the future. Staying on the positive side of things and ignoring the negatives for now, agent skills could hold all the operational knowledge, allowing agents to operate semi-autonomously or autonomously to solve the particular operational problem. An example of that would be compiling a Memgraph Rust query module, which is not an easy task since you need the environment, the Memgraph query module API dependency, and knowledge of how to actually do it. Most advanced LLMs, like Codex or Opus, succeed at this after many tries and failures. This is why we build skills for compiling and deploying C++, Rust, and Python query modules that let LLMs practically single-shot the whole process. Back to the topic of the graph of skills, what is the actuall problem here? So if you have hundreds or thousands of skills in your organisation, the question is: how are you going to maintain them, how will they learn and evolve, and how will agents access them? If the tool's API changes, so should the skills, which causes a cascade of events across the files. Then the question becomes: how are those connected and correlated? This is what graphs as a structure are built for, and this is what we in Memgraph are trying to solve from different angles. The graph of skills will serve as our test bench for running the evolution, traceability, and access to the skills, while improving @memgraphdb as the graph database that serves as a real-time context engine for AI.


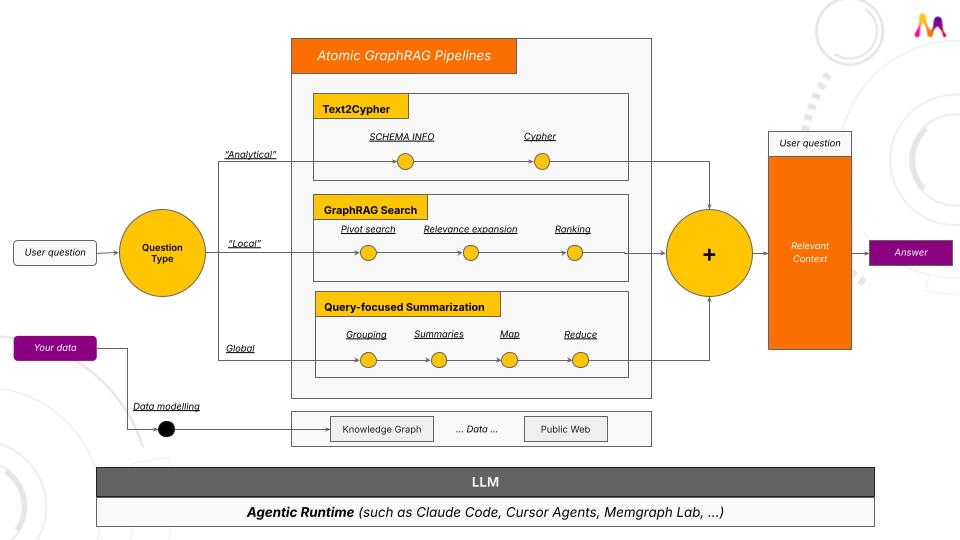



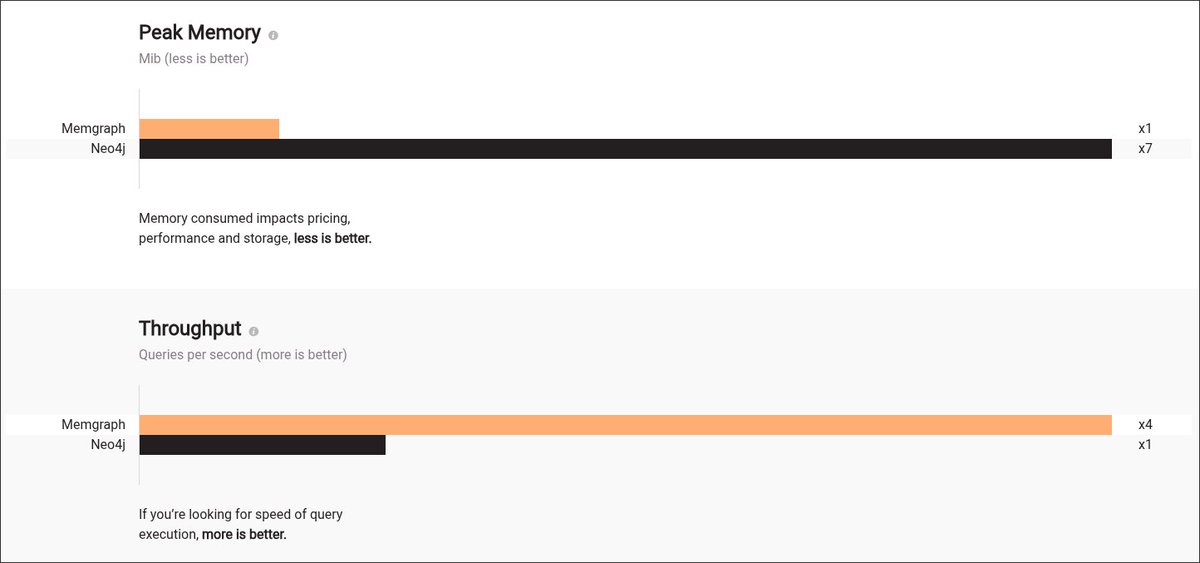
Knowledge graphs are infinitely better than vector search for building the memory of AI agents. With five lines of code, you can build a knowledge graph with your data. When you see the results, you'll never go back to vector-mediocrity-land. Here is a quick video:

