
Mark Lyons
1.4K posts

Mark Lyons
@mcl5tech
product @cloudera | prev product @aws @dremio @verticaunified • #data #analytics #design #tech for 🌍
Somerville, MA เข้าร่วม Ekim 2012
4.9K กำลังติดตาม898 ผู้ติดตาม

Here are the slides and recordings from our Boston DataFusion Meetup in September:
Youtube: youtu.be/wCAud478Dg8
Slides (pdf): drive.google.com/file/d/18KGH_w…
YouTube

English

Spent 18 months trying to find what's coming beyond chat, here are some emerging patterns..

English

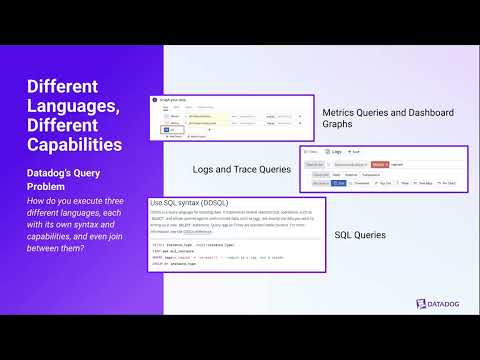
Have you ever wondered why existing database systems focus on either analytical or transactional performance?
Learn why this is the case and how a hybrid storage engine can deliver high performance for combined workloads:
cedardb.com/blog/colibri/
English

I'm working on a set of blog posts that compare the internals of Apache Iceberg, Delta Lake, Apache Hudi and Apache Paimon. No benchmarking, no judgments etc, just a comparison of internal mechanics.
English
Mark Lyons รีทวีตแล้ว


Firecracker is an incredibly cool piece of technology.
Built by AWS and open-sourced, it's essentially a virtual machine monitor that tries to be as lightweight as possible, providing the minimal OS functionality most apps need to run (particularly network and file I/O) and passing through much of the implementation to the host OS. At DBOS, we use Firecracker microVMs to serverlessly host user applications. We really like them because they're fast to start up and don't require many resources, but provide the high level of isolation and security our users need.
The AWS team that built Firecracker wrote a great paper about it--highly recommend checking it out if you want to learn more.

English
Mark Lyons รีทวีตแล้ว

Microsecond-accurate time is now available in EC2 US East. So many cool things this makes possible: aws.amazon.com/about-aws/what…
English

Public service announcement: two children in daycare at @BrightHorizons in Cambridge, MA costs $95,400/year.
This is after-tax money (ie about $130k in income would be needed to afford this).
Shame on this country.
Cc @reshmasaujani
English
@JoshuaSteinman I’ve been working on measuring credibility & expertise via Proof of Research (proof of work concept) any interest in discussing.
English

Request for Startup:
Batting average for public personae and organizations, preferably open and auditable.
Perhaps an open database linking individuals to predictions, and enabling a sort of “Rotten Tomatoes” style rating for accuracy of both predictions AND overall accuracy.
English
Anyone looking for a new SA opportunity DM me and I can intro you to Roger Frey! (Great team & Roger is fantastic!!) lnkd.in/edKZsu-b
English
Verifying myself: I am markclyons on Keybase.io. 2RdVlnBARFNGHkBQEWYYppwhlr0zvyetUhBV / keybase.io/markclyons/sig…

@mim_djo You're also using their dataset, which is optimized to heck and potentially extra cached. Not a fair analysis methinks
English
@mim_djo Was it newly generated data set or a dataset they already created?
English

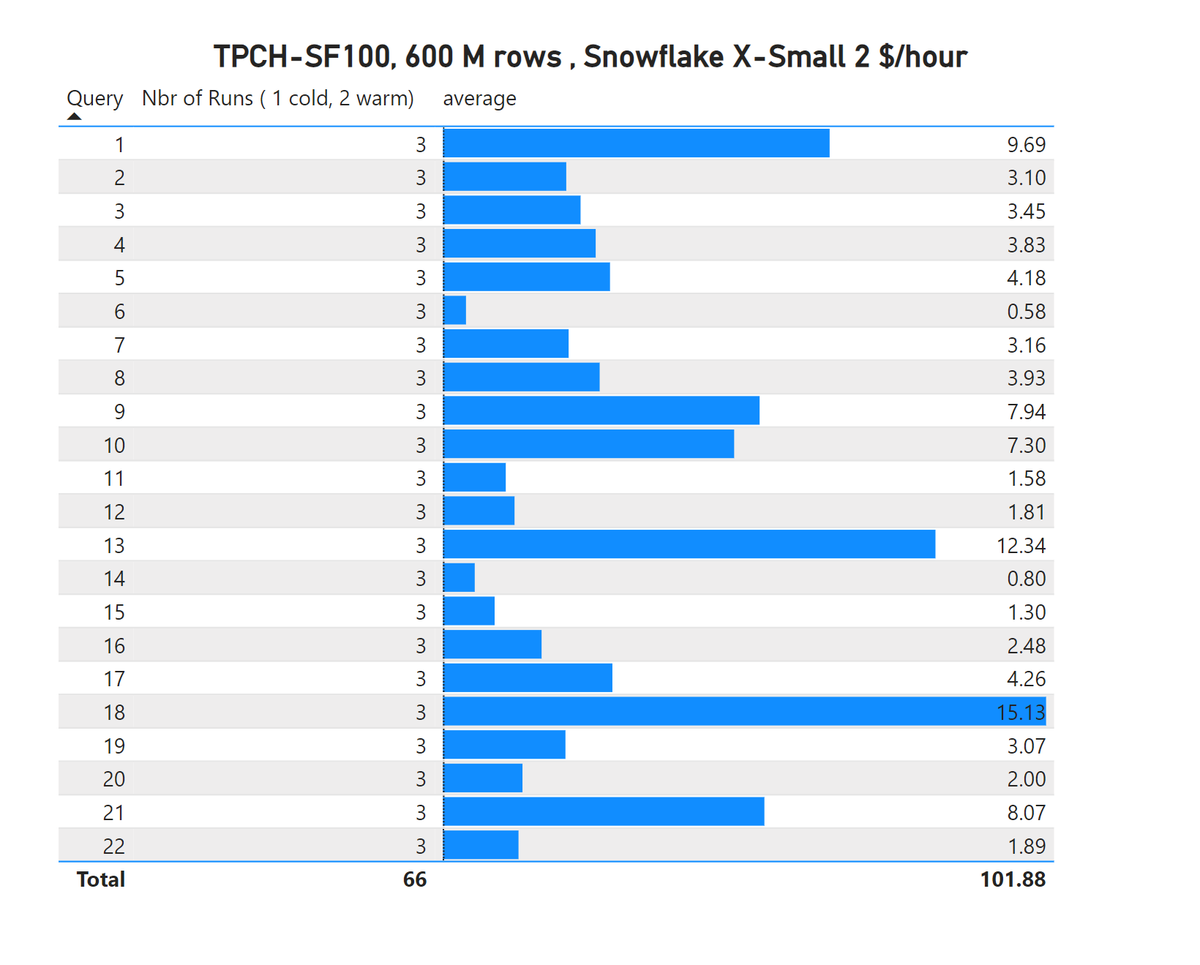
you think you have a basic understanding of OLAP database, then you run TPCH-SF100 ( that's 600 M rows) on #Snowflakedb using the smallest size, this is just wild !!! 102 second , I have no idea what they are doing !!!
English
Mark Lyons รีทวีตแล้ว
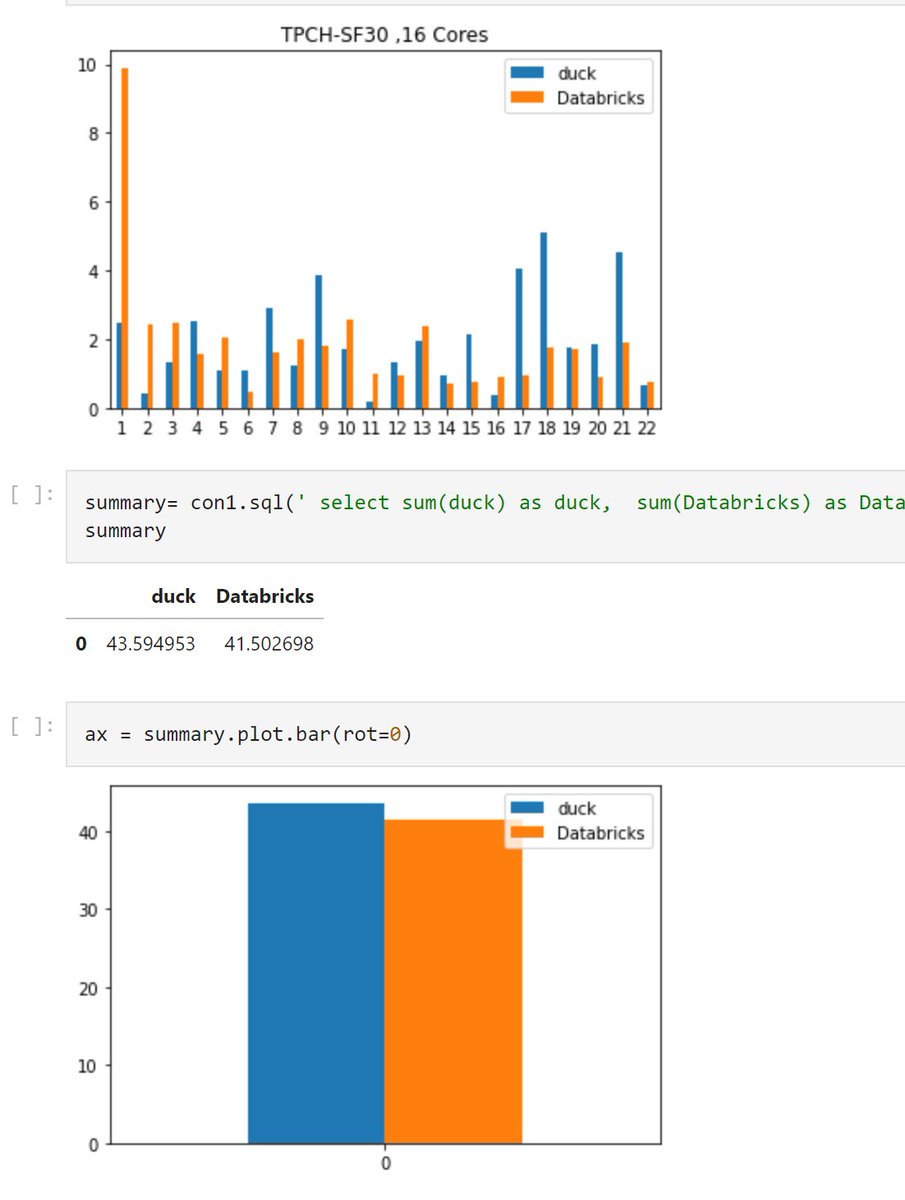
TPCH-SF30 ; 180 million rows
#AZURE D16DS_V5; 16 Cores, 64 GB RAM
#Databricks Photon 41 S
#DuckDB : 43 second
Query Parquet files from the VM SSD, no Azure storage involved
Databricks Software cost (not hardware) 4.4 $/Hour
github.com/djouallah/Test…
English

We raised a $25M Series A to propel us forward in our mission to transform #dataanalytics:
onehouse.ai/blog/announcin…
1yr ago we announced our company. We now doubled our team, built our product, and landed our first customers in production. Onwards!
#datalakehouse #apachehudi
English
English

Wowowo, @neondatabase.. You are telling me you've built a database that allows me to just branch off my production data at any time in the past and use it for testing/debugging/development? Thats way too cool.
English
Mark Lyons รีทวีตแล้ว

Join @dremio’s Tech advocacy & Eng team for the very first installment of the @ApacheIceberg Office Hours 📆 🚀
We will kick-off with a brief presentation on Copy-on-Write Vs Merge-on-Read strategies, followed up by Q&A on anything Iceberg related.
When: December 7th, 12 PM

Toronto, Ontario 🇨🇦 English
Mark Lyons รีทวีตแล้ว

Reminder, if you want to learn more about Apache Iceberg I have loads of resources plus a video series all curated in this article. -> dremio.com/subsurface/apa… #BigData #DataLake #DataLakehouse
English