ทวีตที่ปักหมุด

🚀Announcing MuRGAt!
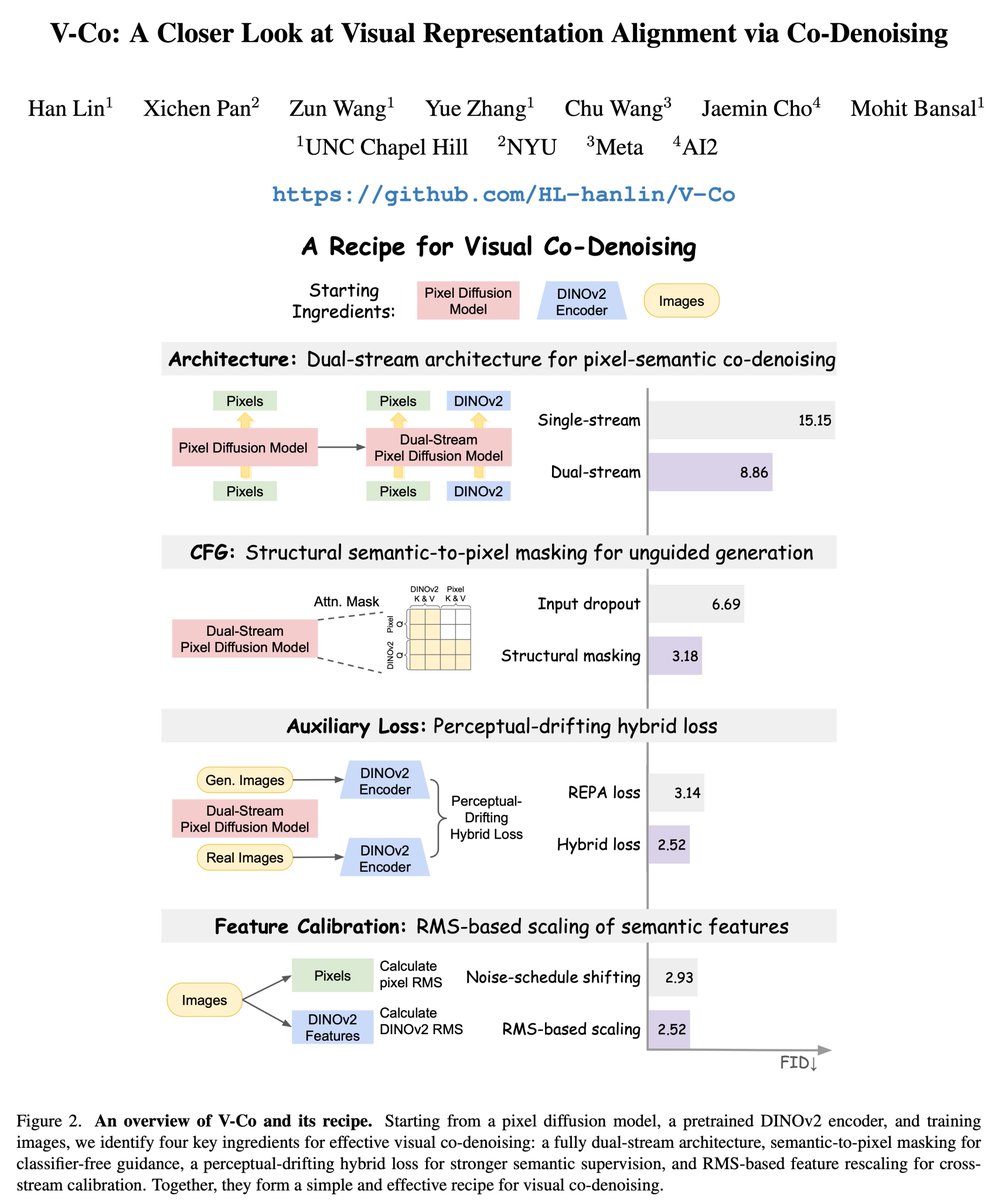
MLLMs are improving at reasoning over complex multimodal inputs, but does that translate to faithful grounding to multimodal sources (video, audio, charts, etc.)? We find that even strong MLLMs often hallucinate citations despite getting the answer correct!🤯
We introduce a benchmark for Fact-Level Multimodal Attribution featuring:
✅ High-quality Human Annotations for validation.
✅ MuRGAt-SCORE: A decomposed metric that highly correlates with human judgment.
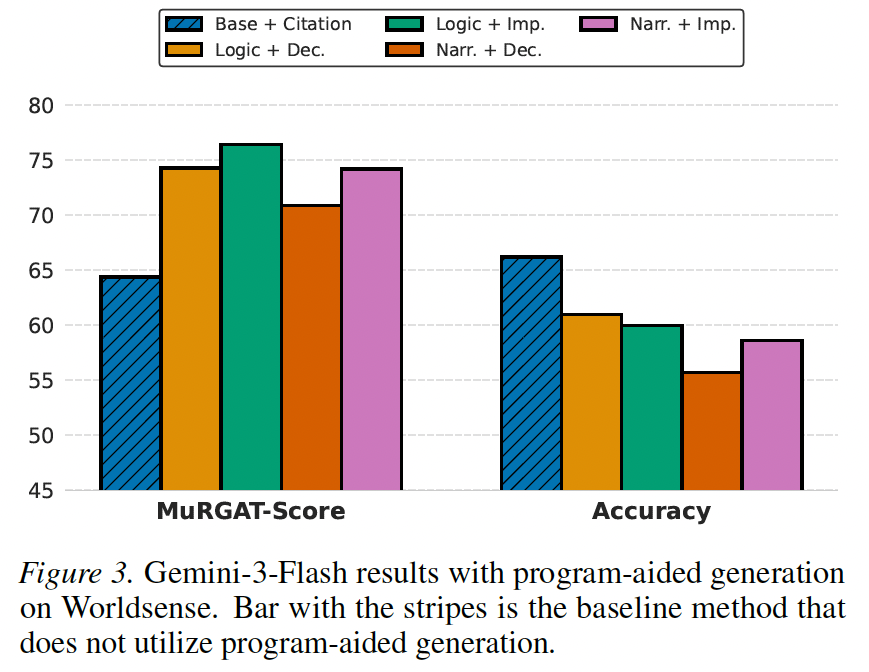
✅ Methods to improve citations, showing that Programmatic Grounding boosts attribution.
🧵👇

English