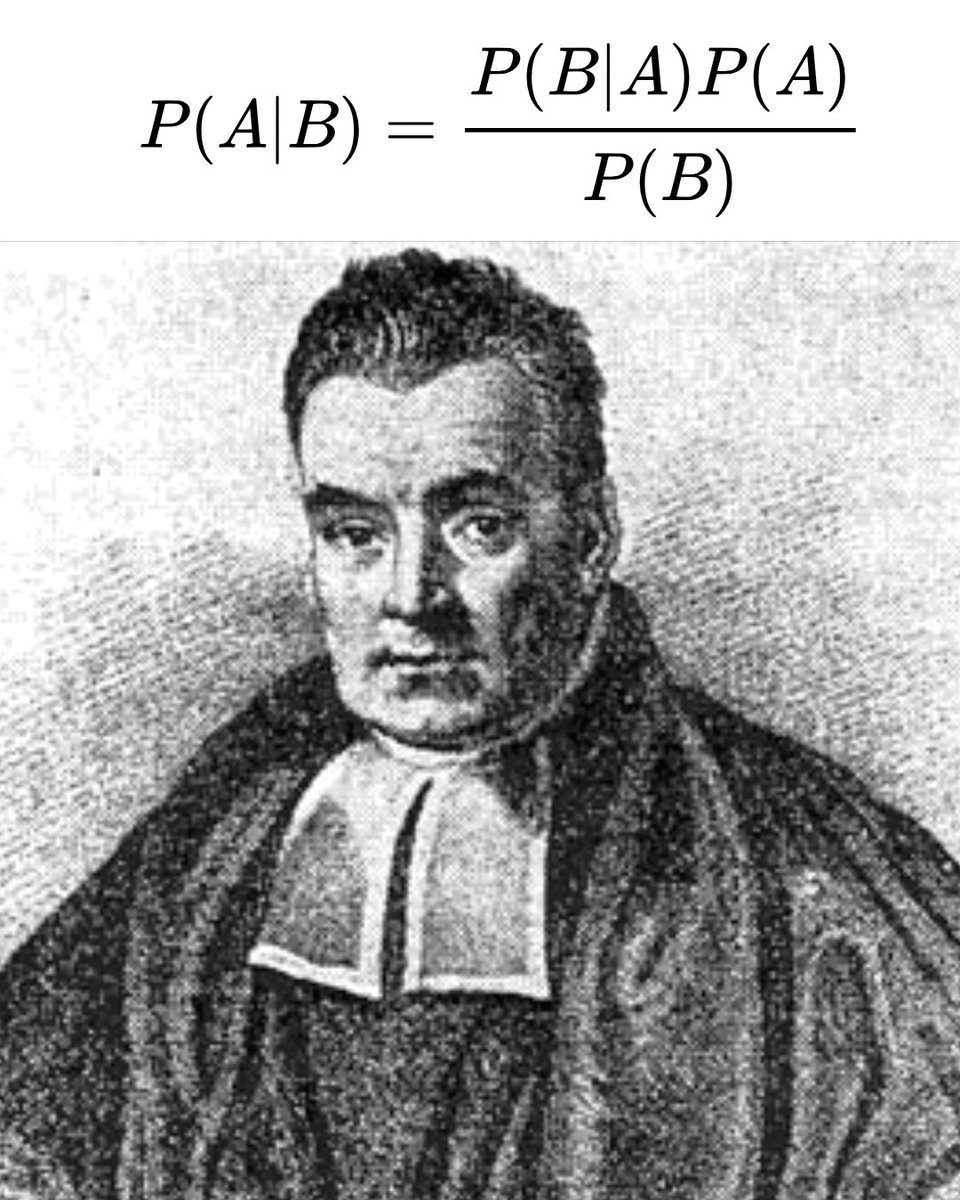Claude Code is about 500K lines of TypeScript. The actual API call is maybe 200 of them. Everything else is the harness. gist.github.com/Haseeb-Qureshi…
the most dangerous thing about claude:
it's the world's most convincing YES-MAN
so i built a "board of advisors" skill that makes 5 agents attack your idea from 5 different angles:
• one assumes your idea will fail and tries to prove it
• one strips away your assumptions and rebuilds the problem from scratch
• one hunts for the bigger opportunity you're too close to see
• one has zero context about you and responds like a complete stranger
• one only cares about what you actually do next
then...
1. all 5 responses get anonymized and peer-reviewed blind
2. a chairman agent reads everything and synthesizes the final verdict
after a few minutes, you get one recommendation you can *actually* trust.
free skill + full breakdown:
Holy shit.
Someone just leaked the Claude Code project template teams are quietly using.
This isn't prompting anymore.
This is AI engineering infrastructure. ⚡
The entire setup revolves around one file: CLAUDE.md
Every time Claude makes a mistake → you add a rule
Every time you repeat yourself → you add a workflow
Every time something breaks → you add a guardrail
Claude literally trains itself on your project.
And the structure is wild:
• CLAUDE.md → project memory & instructions
• skills/ → reusable AI workflows
• hooks/ → automated checks & guardrails
• docs/ → architecture decisions
• src/ → actual code modules
• tools/ → scripts + prompts
You're not chatting with AI anymore.
You're building an AI that knows your repo.
The craziest part?
You only configure this once.
After that Claude: – reviews code automatically
– refactors on command
– enforces architecture rules
– writes release notes
– runs workflows from skills
– remembers past mistakes
And it keeps getting smarter.
Most people:
open ChatGPT → write prompt → copy paste → repeat
This setup:
open terminal → run skill → code shipped
You're basically running AI teammates inside your repo.
This template is the difference between: • using Claude occasionally
• running Claude like infrastructure
Drop it in any project.
Your AI stops guessing — and starts operating.
BREAKING
Elon Musk endorsed my Top 26 Essential Papers for Mastering LLMs and Transformers
Implement those and you’ve captured ~90% of the alpha behind modern LLMs.
Everything else is garnish.
This list bridges the Transformer foundations
with the reasoning, MoE, and agentic shift
Recommended Reading Order
1. Attention Is All You Need (Vaswani et al., 2017)
> The original Transformer paper. Covers self-attention,
> multi-head attention, and the encoder-decoder structure
> (even though most modern LLMs are decoder-only.)
2. The Illustrated Transformer (Jay Alammar, 2018)
> Great intuition builder for understanding
> attention and tensor flow before diving into implementations
3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
> Encoder-side fundamentals, masked language modeling,
> and representation learning that still shape modern architectures
4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020)
> Established in-context learning as a real
> capability and shifted how prompting is understood
5. Scaling Laws for Neural Language Models (Kaplan et al., 2020)
> First clean empirical scaling framework for parameters, data, and compute
> Read alongside Chinchilla to understand why most models were undertrained
6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022)
> Demonstrated that token count matters more than
> parameter count for a fixed compute budget
7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
> The paper that triggered the open-weight era
> Introduced architectural defaults like RMSNorm, SwiGLU
> and RoPE as standard practice
8. RoFormer: Rotary Position Embedding (Su et al., 2021)
> Positional encoding that became the modern default for long-context LLMs
9. FlashAttention (Dao et al., 2022)
> Memory-efficient attention that enabled long context windows
> and high-throughput inference by optimizing GPU memory access.
10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020)
> Combines parametric models with external knowledge sources
> Foundational for grounded and enterprise systems
11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022)
> The modern post-training and alignment blueprint
> that instruction-tuned models follow
12. Direct Preference Optimization (DPO) (Rafailov et al., 2023)
> A simpler and more stable alternative to PPO-based RLHF
> Preference alignment via the loss function
13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
> Demonstrated that reasoning can be elicited through prompting
> alone and laid the groundwork for later reasoning-focused training
14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023)
> The foundation of agentic systems
> Combines reasoning traces with tool use and environment interaction
15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025)
> The R1 paper. Proved that large-scale reinforcement learning without
> supervised data can induce self-verification and structured reasoning behavior
16. Qwen3 Technical Report (Yang et al., 2025)
> A modern architecture lightweight overview
> Introduced unified MoE with Thinking Mode and Non-Thinking
> Mode to dynamically trade off cost and reasoning depth
17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017)
> The modern MoE ignition point
> Conditional computation at scale
18. Switch Transformers (Fedus et al., 2021)
> Simplified MoE routing using single-expert activation
> Key to stabilizing trillion-parameter training
19. Mixtral of Experts (Mistral AI, 2024)
> Open-weight MoE that proved sparse models can match dense quality
> while running at small-model inference cost
20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023)
> Practical technique for converting dense checkpoints into MoE models
> Critical for compute reuse and iterative scaling
21. The Platonic Representation Hypothesis (Huh et al., 2024)
> Evidence that scaled models converge toward shared
> internal representations across modalities
22. Textbooks Are All You Need (Gunasekar et al., 2023)
> Demonstrated that high-quality synthetic data allows
> small models to outperform much larger ones
23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024)
> The biggest leap in mechanistic interpretability
> Decomposes neural networks into millions of interpretable features
24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022)
> A masterclass in large-scale training
> orchestration across thousands of accelerators
25. GLaM: Generalist Language Model (Du et al., 2022)
> Validated MoE scaling economics with massive
> total parameters but small active parameter counts
26. The Smol Training Playbook (Hugging Face, 2025)
> Practical end-to-end handbook for efficiently training language models
Bonus Material
> T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
> Toolformer (Schick et al., 2023)
> GShard (Lepikhin et al., 2020)
> Adaptive Mixtures of Local Experts (Jacobs et al., 1991)
> Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994)
If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most
Time to lock-in, good luck!
LLM in the middle, rewrite the query, route to the right source, rerank & evaluate whether retrieved is actually good enough, and loop again if not. blog.bytebytego.com/p/how-agentic-…
Test first, two layers of eval, life in terminal,… plus human role is shifting to planning, evaluating, and steering. Slop and convergence are real concerns, and context remains unsolved. The vibe’ been changing, fast akashbajwa.co/p/the-future-o…
Claude Code can run entirely on your local GPU now.
Unsloth AI published the complete guide.
The setup itself is straightforward - llama.cpp serves Qwen3.5 or GLM-4.7-Flash, one environment variable redirects Claude Code to localhost.
But the guide is valuable because of what it explains beyond the setup:
Why local inference feels impossibly slow: Claude Code adds an attribution header that breaks KV caching. Every request recomputes the full context. The fix requires editing settings.json - export doesn't work.
Why Qwen3.5 outputs seem off: f16 KV cache degrades accuracy, and it's llama.cpp's default. Multiple reports confirm this. Use q8_0 or bf16 instead.
Why responses take forever: Thinking mode is great for reasoning but slow for agentic tasks. The guide shows how to disable it.
The proof it all works: Claude Code autonomously fine-tuning a model with Unsloth. Start to finish. No API dependency.
Fits on 24GB. RTX 4090, Mac unified memory.
3 OpenClaw tips that took me months to figure out:
1. Make it self-improve
Create a `.learnings/` folder with:
- `ERRORS.md` → Log every failure with context
- `LEARNINGS.md` → Log every correction you make
Add this to your `AGENTS.md`:
"After completing ANY task, check .learnings/ for relevant past errors. After ANY failure, log it immediately."
Your agent stops making the same mistake twice.
2. 100% fix rate for crashes
When OpenClaw breaks, don't debug manually. Point Claude Code at your files:
"My OpenClaw agent is [not responding / slow / erroring]. SSH into my machine, read the logs, and troubleshoot. Build a plan before taking action."
I've never written code. This works every time.
3. Make it opinionated
Edit your `SOUL.md`:
"- Take a stance. Never hedge with "you could do X or Y"
- Be concise. No filler phrases.
- When unsure, ask one clarifying question, then execute."
Default OpenClaw is polite but vague. Fix that.
Steal these. Your agent will thank you.
Damnn 😱
Most developers are using Claude Code wrong.
They open the terminal...
write a prompt...
and expect magic.
That’s not where the real power is.
Claude Code is actually a 4-layer AI engineering system:
1️⃣ CLAUDE.md → project memory
Architecture, rules, commands, conventions
2️⃣ Skills → reusable knowledge packs
Testing workflows, code review guides, deploy patterns
3️⃣ Hooks → deterministic guardrails
Security checks, enforced rules, automation
4️⃣ Agents → specialized sub-agents
Break complex tasks into parallel workflows
Once you structure these properly, something interesting happens:
Claude stops behaving like a chatbot.
It starts behaving like a real AI dev system.
Most engineers miss this because they jump straight to prompting.
But the difference between average output and production-level results usually comes down to setup.
If you're building with AI agents in 2026, learn the system — not just the prompt.
I made a Claude Code Starter Pack explaining everything.
If you want it:
Follow
Like + RT
Comment CLAUDE
I'll DM it to a few people.
Future AI dev workflows won't be prompt-first.
They’ll be system-first. 🚀
#AI#Claude#AIAgents#LLM#GenAI
Bayes’ theorem is probably the single most important thing any rational person can learn.
So many of our debates and disagreements that we shout about are because we don’t understand Bayes’ theorem or how human rationality often works.
Bayes’ theorem is named after the 18th-century Thomas Bayes, and essentially it’s a formula that asks: when you are presented with all of the evidence for something, how much should you believe it?
Bayes’ theorem teaches us that our beliefs are not fixed; they are probabilities. Our beliefs change as we weigh new evidence against our assumptions, or our priors. In other words, we all carry certain ideas about how the world works, and new evidence can challenge them.
For example, somebody might believe that smoking is safe, that stress causes mouth ulcers, or that human activity is unrelated to climate change. These are their priors, their starting points. They can be formed by our culture, our biases, or even incomplete information.
Now imagine a new study comes along that challenges one of your priors. A single study might not carry enough weight to overturn your existing beliefs. But as studies accumulate, eventually the scales may tip. At some point, your prior will become less and less plausible.
Bayes’ theorem argues that being rational is not about black and white. It’s not even about true or false. It’s about what is most reasonable based on the best available evidence. But for this to work, we need to be presented with as much high-quality data as possible. Without evidence—without belief-forming data—we are left only with our priors and biases. And those aren’t all that rational.