@minviable_org you can try the dockerfile but i'm not sure if maxq will be the same
i don't really see why not, it's supposed to be the same card under the hood
English
cheeker
128 posts
@realcheeker
ex fb ml ai fu ck u


⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency. #1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0. Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution. - 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels. - Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees. - Web + visual search reaches further: more sources, deeper follow-up. - Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels. - Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP. - Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395. GitHub: github.com/stepfun-ai/Ste… HuggingFace: huggingface.co/stepfun-ai/Ste… GGUF: huggingface.co/stepfun-ai/Ste… ModelScope: modelscope.cn/models/stepfun… API: platform.stepfun.ai Blog: static.stepfun.com/blog/step-3.7-…
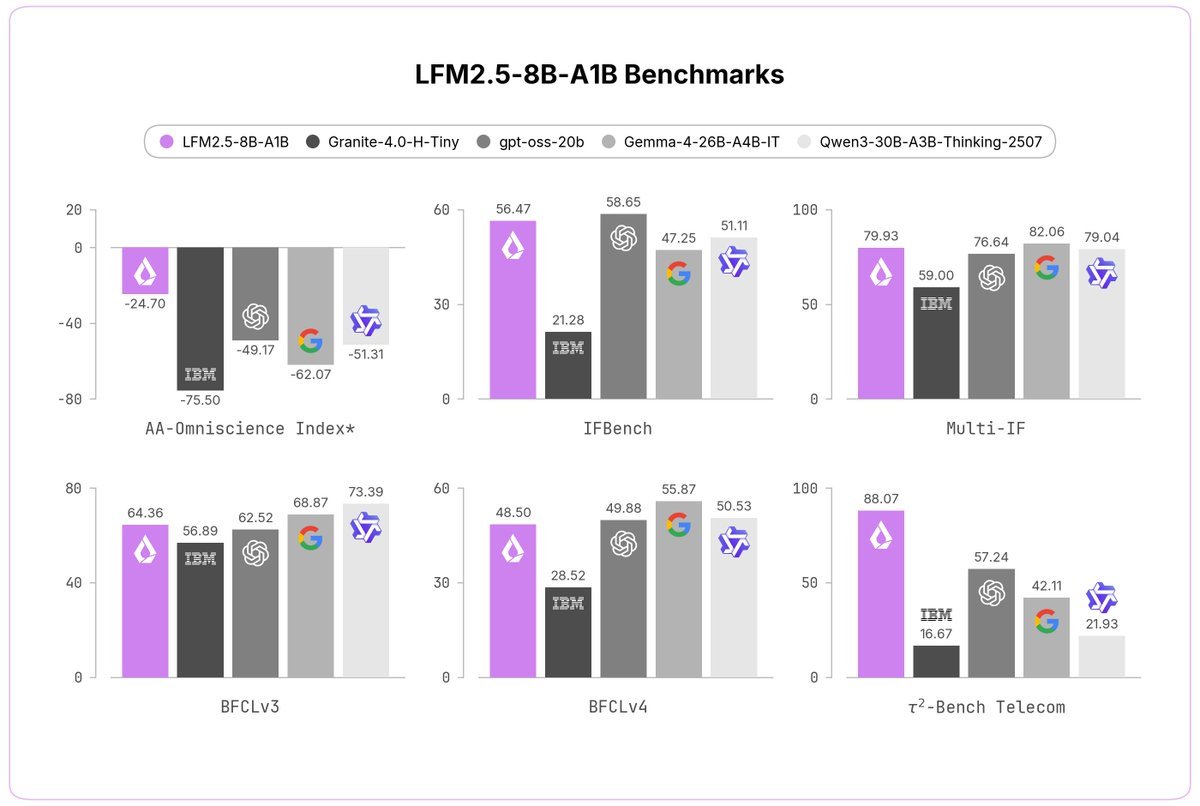
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases. > 8B MoE, 1.5B active > Expanded 128K context > LFM2.5 flagship hybrid MoE architecture > Trained on 38T tokens + large-scale RL > fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size > customizable on a single GPU for any specialized task > LFM2 open-weight license 🧵