ทวีตที่ปักหมุด

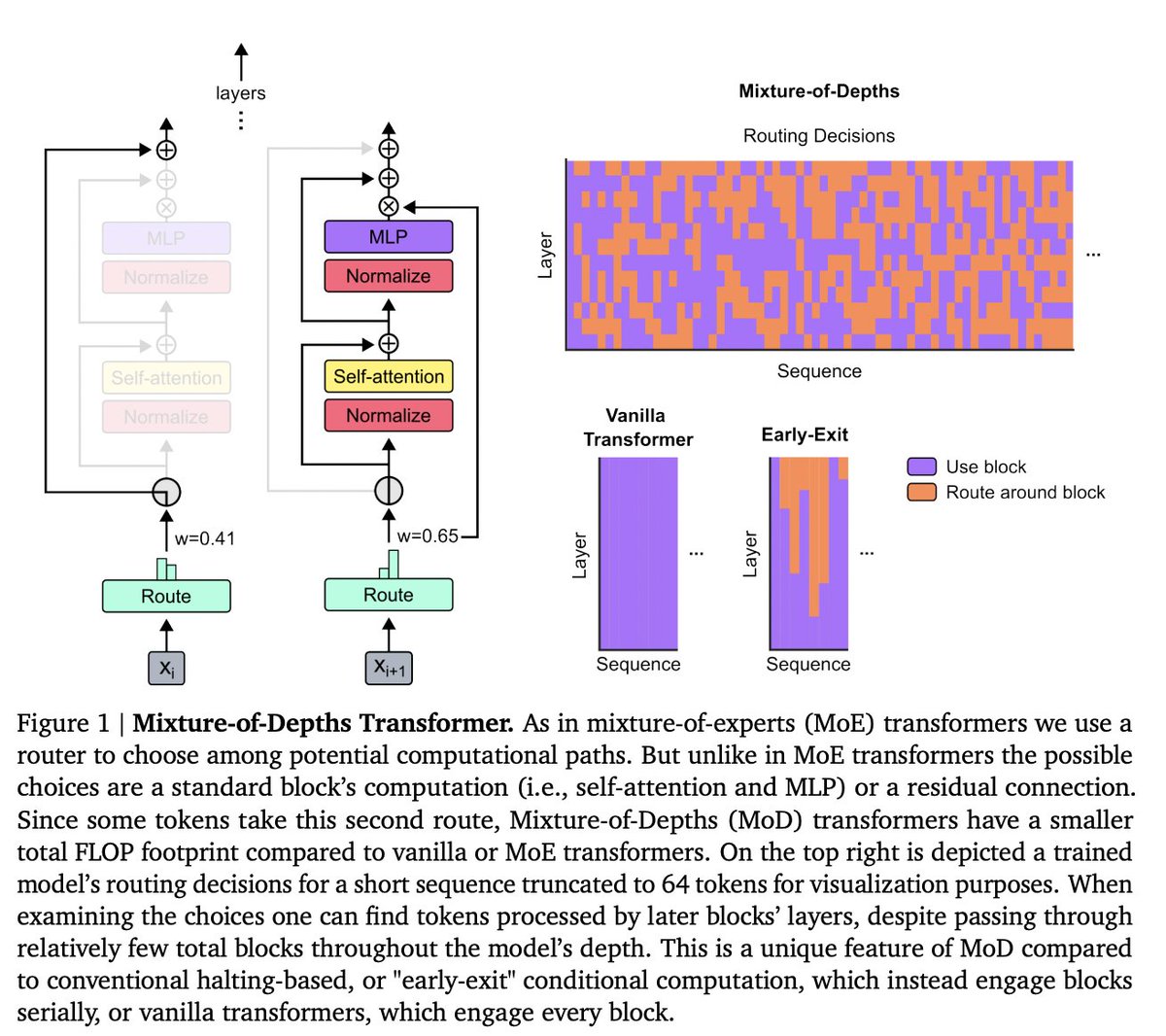
Transformers can be made sparse across their depth. When trained isoFLOP, we can match or exceed the performance of vanilla models, while saving inference FLOPs
arxiv.org/abs/2404.02258
English
Adam Santoro
1.2K posts
@santoroAI
Research Scientist in artificial intelligence at DeepMind


It's such an honor to work on Project Astra with such an amazing team from across Gemini and Google DeepMind! While the #GoogleIO keynote was happening we had a last minute idea of watching the keynote with Project Astra. Check it out!









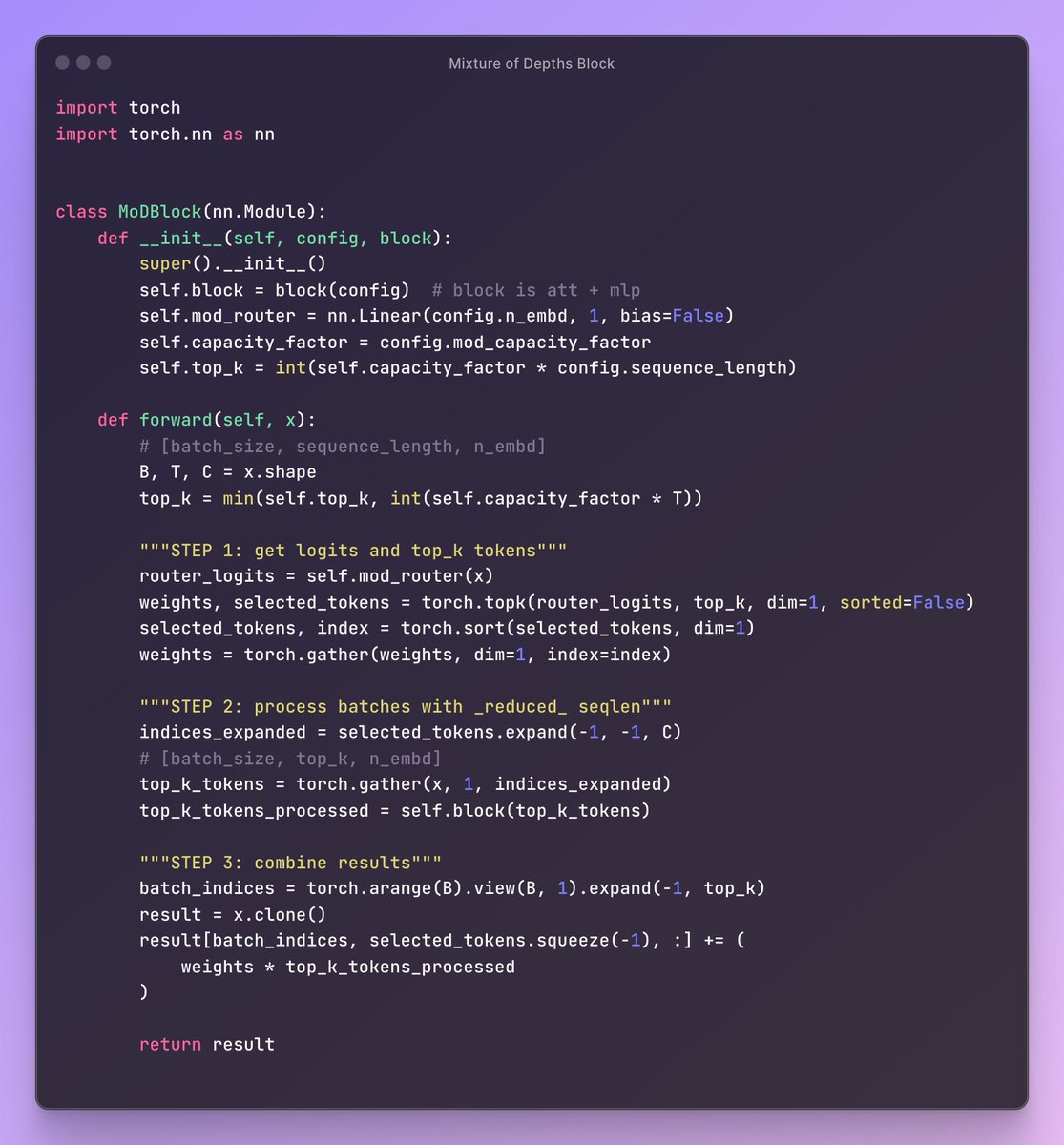
Why Google Deepmind's Mixture-of-Depths paper, and more generally dynamic compute methods, matter: Most of the compute is WASTED because not all tokens are equally hard to predict


