ทวีตที่ปักหมุด

대통령직속 국방혁신위원회 위원으로 활동하면서 사이버보안과 관련해 제가 지속적으로 제안했던 2가지가 있었습니다.
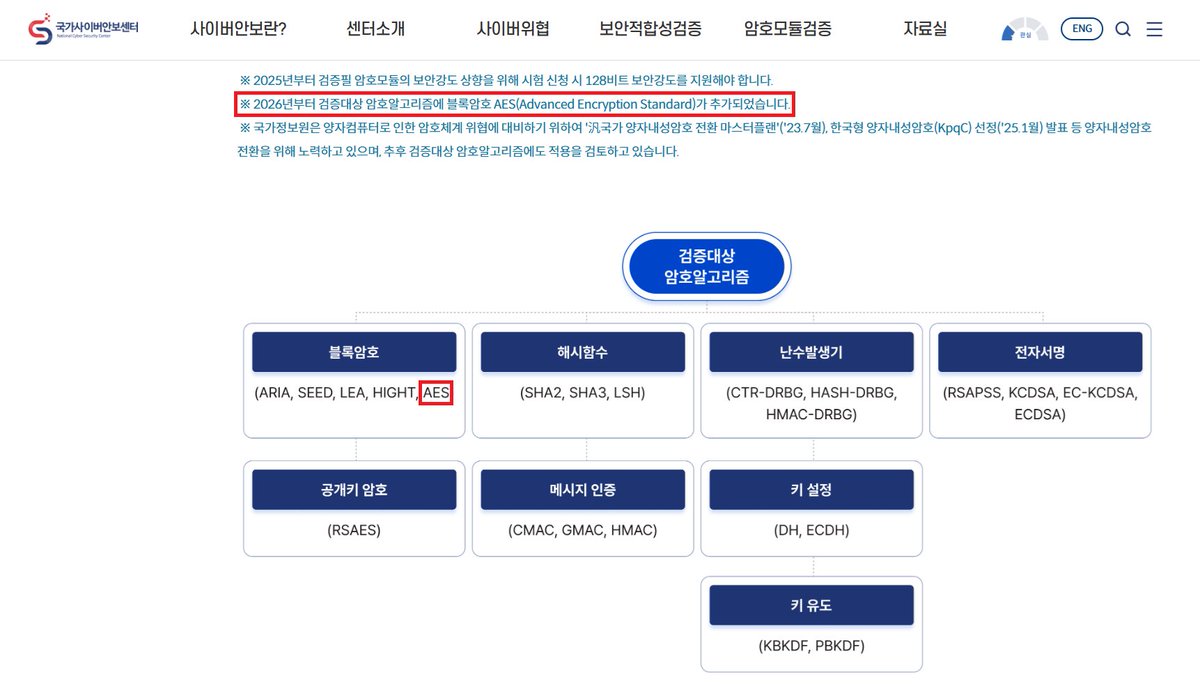
첫째는 망분리 제도를 데이터 중요도 중심의 선진국형 망분리 체계로 전환하자는 것이었고, 둘째는 K-CMVP 제도의 검증 대상에 AES 국제표준 암호를 포함하자는 것이었습니다.
Gangnam-gu, Republic of Korea 🇰🇷 한국어
Seungjoo Kim (김승주)
20.8K posts

@skim71
Professor of @CysecSchool at Korea Univ. / Adviser of CyKor (DEFCON CTF 2015 & 2018 Winner) / Black Hat Asia Review Board / (Former) Team Leader of KISA




PS. 참고로 SEED를 미국의 고비도 암호 수출규제 정책때문에 개발했다고들 아시는데 그건 아닙니다. (당시 제가 KISA 암호기술팀에 있었을때 추진했던 일이라...)
@tqbf It is. This bug is also fun: github.com/advisories/GHS… Did you know that South Korea invented their own block cipher and managed to get it to wolfSSL? Their cipher implementation of GCM mode is horribly broken. Kim Jung Un would love this!

The CIA attack against Samsung smart TVs was developed in cooperation with the MI5. Weeping Angel places TVs in a 'Fake-Off' mode, so the owner believes the TV is off. In this mode the TV records conversations in the room and sends them over the Internet to a covert CIA server.