
Ashutosh
6.6K posts

Ashutosh
@voidmonk
Founder https://t.co/D3LZEpwW9n. B2B SaaS, DevOps, DadOps. Slow living 🦥
AU เข้าร่วม Ekim 2008
478 กำลังติดตาม790 ผู้ติดตาม


What’s the shortest book that had the biggest impact on you?
English
Been thinking about this lately. A lot of domain knowledge lives in people's heads. Hard to document it all. But, companies (like Meta is already planning) may (controversially) track employee keystrokes & mouse over a period to map workflows and create AI agent training datasets

English
AI hype is mind-boggling.
Agents, SaaS apocalypse, "new economy", "future abundance" etc. are just ploys by investors for ROI and by companies to justify job cuts.
Ronan Berder@hunvreus
Talking to smarter folks than me, I'm convinced many of the AI folks in my timeline are full of shit. Nobody is "running 20 agents over night" and building stuff for actual users. Maybe some are building internal tools or disposable software. Maybe. But building software people like using? That doesn't get hacked on day one or blow up after the 3rd user? Nope. I don't even understand what that's supposed to look like. Do you work out a 57 pages document that perfectly describes what you want to build and then summon 14 agents and have them run wild for 6 hours? And what comes out on the other end isn't a broken pile of shit? Nope. Not buying it. PS: it may also be that I have an IQ of 82 and can't figure it out.
English
@dhruvtwt_ @nvidia The listed 'kimi-k2-instruct' and 'kimi-k2-instruct-0905' seem to be old Kimi K2, not K2.5
English

Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: build.nvidia.com/models
– base_url = "integrate.api.nvidia.com/v1"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.

English
Intel has outdone AMD this time w/ Panther Lake. @FrameworkPuter laptop 13 Pro got 20+ hours battery life. I would have liked the option of non-touch display, and although the display is variable rate (30-120Hz) it's not close to the 1-120Hz panel in the Dell XPS 14 on 40+ hours!

English
@flowstated For small layout changes, won't it make more sense to just have a formatting toolbar than describing each change (waiting and spending tokens on trivial work)?
English

@dvassallo Honest question, how do you verify that all the analysis is 100% accurate or atleast within a negligible margin?
English

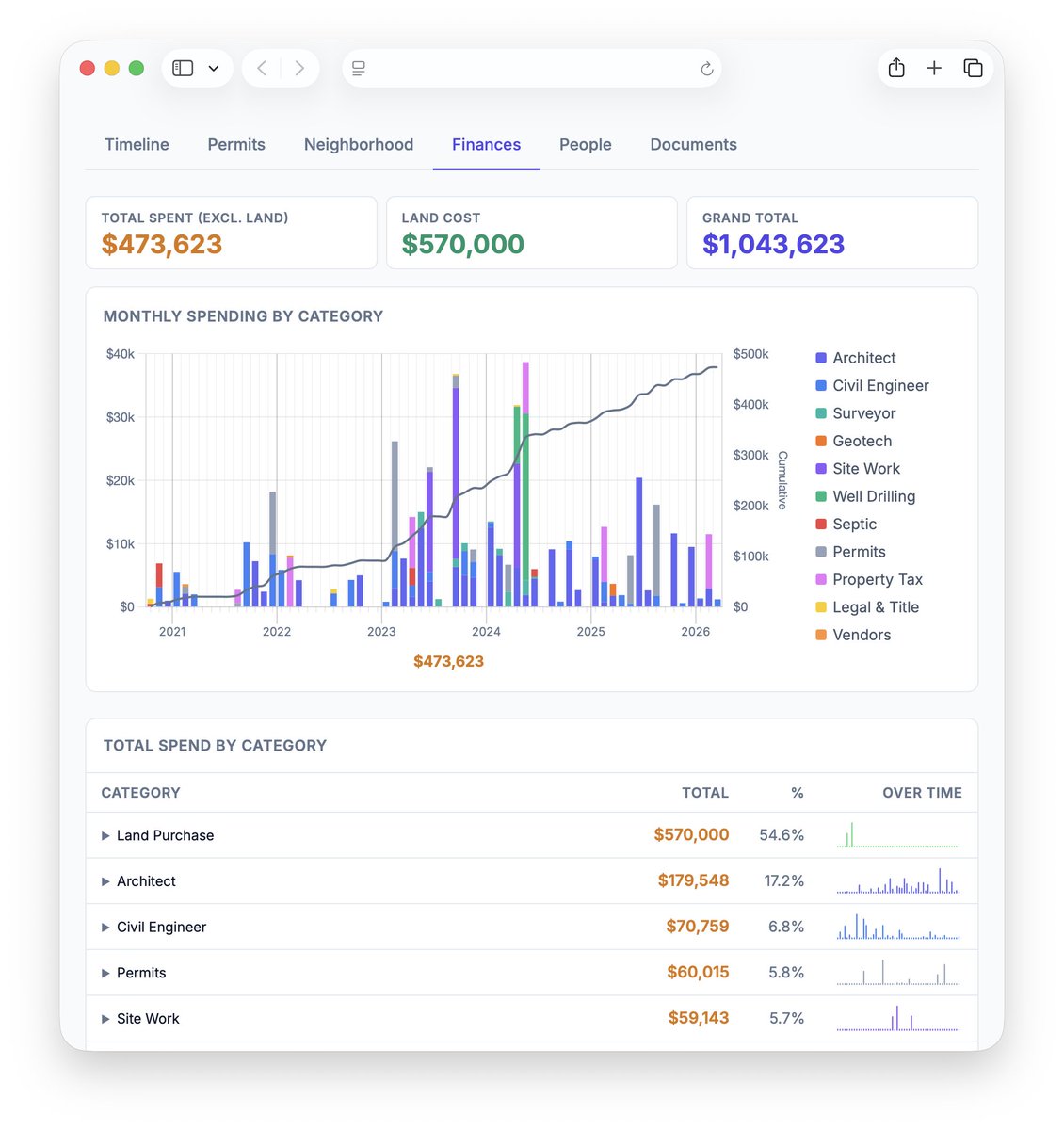
I've been in the process of building a custom home for 5 years. Bought the land in 2021. Got the building permit this year. Haven't started construction yet.
During those 5 years, I accumulated thousands of emails with dozens of architects, engineers, surveyors, contractors, government agencies, title companies, and others. Hundreds of PDFs I opened once and never found again.
My project management system was email search and my own memory.
I could always find individual emails when I needed them. What I couldn't do was see the project. How much money have we actually spent, and on what? Who are all the contractors we talked to, and how did we find each one? What happened with the easement, not one email about it, but the full arc across three years? Why did we stop using the original surveyor?
The answers were all in my inbox. But they were spread across hundreds of threads. No single email contained the story. The story only existed in the connections between them.
So I tried something. I pointed OpenClaw at my full email inbox and said: read all my emails in chronological order and figure out what happened with this project over the last 5 years. Build me a timeline. Find all the documents. Track the money. Map the people.
That's it. I didn't sort anything. I didn't classify anything. I didn't tell it which threads mattered. I just pointed at the inbox and let it work.
And it worked way better than I expected.
It found 1,850 emails across 450 threads involving 58 people at 35 organizations. From that, it produced 511 timeline events describing what actually happened over 5 years. Not "Daniel emailed the architect" but "Easement delay threatens grading permit" or "architect warns the entire permit depends on securing the neighbor's access agreement." Real project history in PM language.
It identified 690 documents and classified each one: invoice, permit, survey map, legal agreement, environmental report, estimate, and so on, and it linked them to the timeline events that referenced them.
It extracted 170 finance records from email bodies and PDF attachments. Invoices, payments, estimates, and receipts with amounts, dates, and payees pulled from messy documents.
It mapped out 58 contacts with their roles, their organizations, and how they related to the project over time.
All interlinked. Click a timeline event, see the emails that produced it and the documents attached. Click a payment, trace it back to the invoice and the email thread. Click a person, see every event they were involved in.
It built a dashboard on top of it and for the first time in 5 years, I could actually see the whole project. The full arc. Every dollar. Every person. Every decision. Stitched together from raw correspondence into something I can sit down and browse.
The key insight for me was realizing this is basically an ETL process: Extract, Transform, and Load. The emails are the source data. The agent does the extraction from emails and loading into a database. But the really powerful part is the Transform: the LLM reads the raw correspondence with enough context to do intelligent enrichment across hundreds of threads spanning months and years.
And by enrichment I don't mean summarization. I mean it actually reconstructed the narrative of the project.
It traced how we almost hired the wrong well driller. We originally hired one company, paid a deposit, and were ready to go. Then the architect heard from someone in his network that they weren't reliable. We pivoted to a different driller who came recommended through a chain of referrals the agent traced back to its origin. The new company came out, drilled 140 feet, hit an artesian well with water pressure above ground level, and finished in two weeks. The original deposit got refunded. The agent reconstructed that entire sequence from first contact to final invoice, across dozens of emails and multiple contractors, and presented it as one coherent story.
It reconstructed the full permit saga. Four separate permits with the county, each with its own cycle of applications, reviews, correction letters, resubmissions, and approvals. Years of back and forth. The agent built the complete timeline for each permit and linked every document and payment to the right stage.
It tracked the money flow end to end. Not just "we paid the architect X." It found every invoice, matched them to the work described in the email threads, categorized the spending, and produced a financial history of the entire project broken down by architect, engineer, surveyor, contractor, county fees, and everything else.
It mapped out relationships between people that I had half-forgotten. Which engineer referred which surveyor. Which contractor's crew member later became a separate vendor. Which county reviewer handled which permit. All of it was in the email, I just never had the time to stitch it together myself.
One of the most fun things it did was writing honest personality profiles for each contact based purely on their communication style. How responsive they are. How they handle pushback. Whether they tend to over-promise. Whether they're the kind of person who answers at 11pm or takes five days to reply. Reading an AI's unfiltered take on the people you've been doing business with for years, based on nothing but their emails, is surprisingly entertaining and uncomfortably accurate.
The thing that surprised me most is how much structure was already hiding in the email. I didn't add information. The agent found what was already there. The timeline, the document graph, the money flows, the cast of characters. It was all latent in the correspondence. Five years of decisions and negotiations and payments, all recorded in email, just never connected.
I think a lot of people are sitting on projects like this without realizing it. Your renovation emails are a project database waiting to be assembled. Your legal correspondence is a case file. Your immigration threads are an application history. The raw material has been accumulating for months or years. It's rich, timestamped, and complete. It's just in a format designed for messaging, not for understanding.
Point an agent at it. Let it read everything. Let it do the transform. The whole story was in my inbox the entire time. I just needed something that could read all of it at once.

English
@Cryptinflux Absolutely, even VS Code and Claude Code support devcontainers.json. Not so sure about Codex, Cursor, OpenCode etc.
English

@voidmonk DevContainers + AI agents is a powerful combo. The isolation piece is genuinely underrated for codegen work.
English
Using GitHub Codespaces lately has highlighted the benefits of DevContainers, specially for AI agent/codegen work in an isolated environment, although Copilot is crap. Makes you wonder if local tooling and IDEs (and even people) may no longer be necessary to produce software.
English
Unlikely for AI to take all jobs. Imo, companies don't care about 'no jobs, no income, no spending' problem as long as their profits keep rising for now. When costs collapse and demand slow, they'll want governments to take care of the problem through UBI etc.
Govind@Govindtwtt
Everyone says “AI will take all the jobs.” If that happens… how does this future actually work? No jobs → no income → no spending. So who buys things? Who pays rent? Who keeps the economy moving? What am I missing here?
English
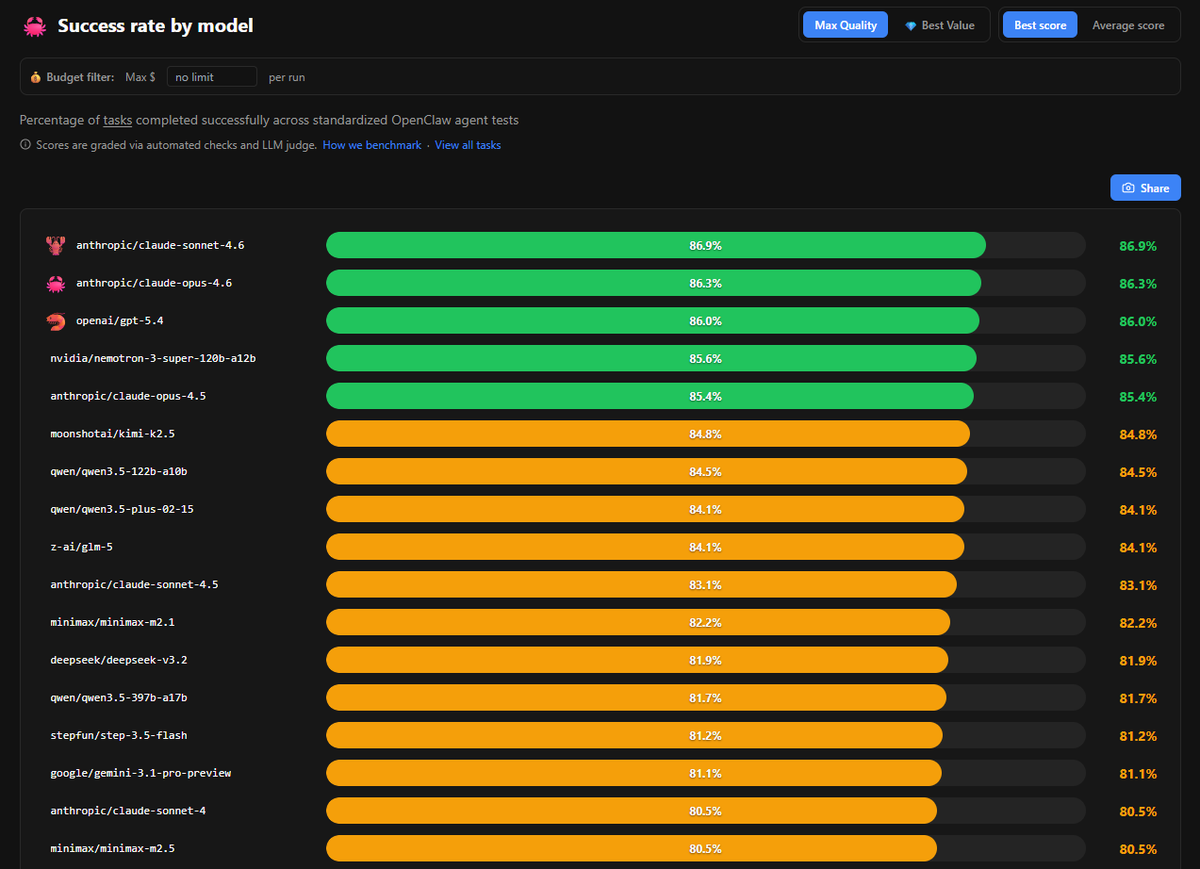
Open and local models are the real deal. Closed models from OpenAI, Anthropic etc. have a markup for R&D and investors, making them quite expensive comparatively, besides other issues like data privacy and network latency.
DHH@dhh
Kimi K2.5 on @opencode Zen is hilariously cheap. I bought $20 worth of tokens two weeks ago, and I still have $10.89 left! After 3M tokens! If there's a bubble in AI, it's pricing a million tokens at $25 (and beyond).
English
"AI increased workload and worker burnout"
Berkeley study of ~200 employees: hbr.org/2026/02/ai-doe…
Upwork survey of 2500 workers: upwork.com/research/ai-en…
DHR Global survey of 1500 workers: dhrglobal.com/insights/workf…
Wellhub survey of 5000+ workers: wellhub.com/en-us/blog/pre…
English
TIL about htmz on HN: "a masterclass in simplicity. It's gotta be the all time code golf winner." A minimalist HTML microframework for AJAX navigation: leanrada.com/htmz/
English
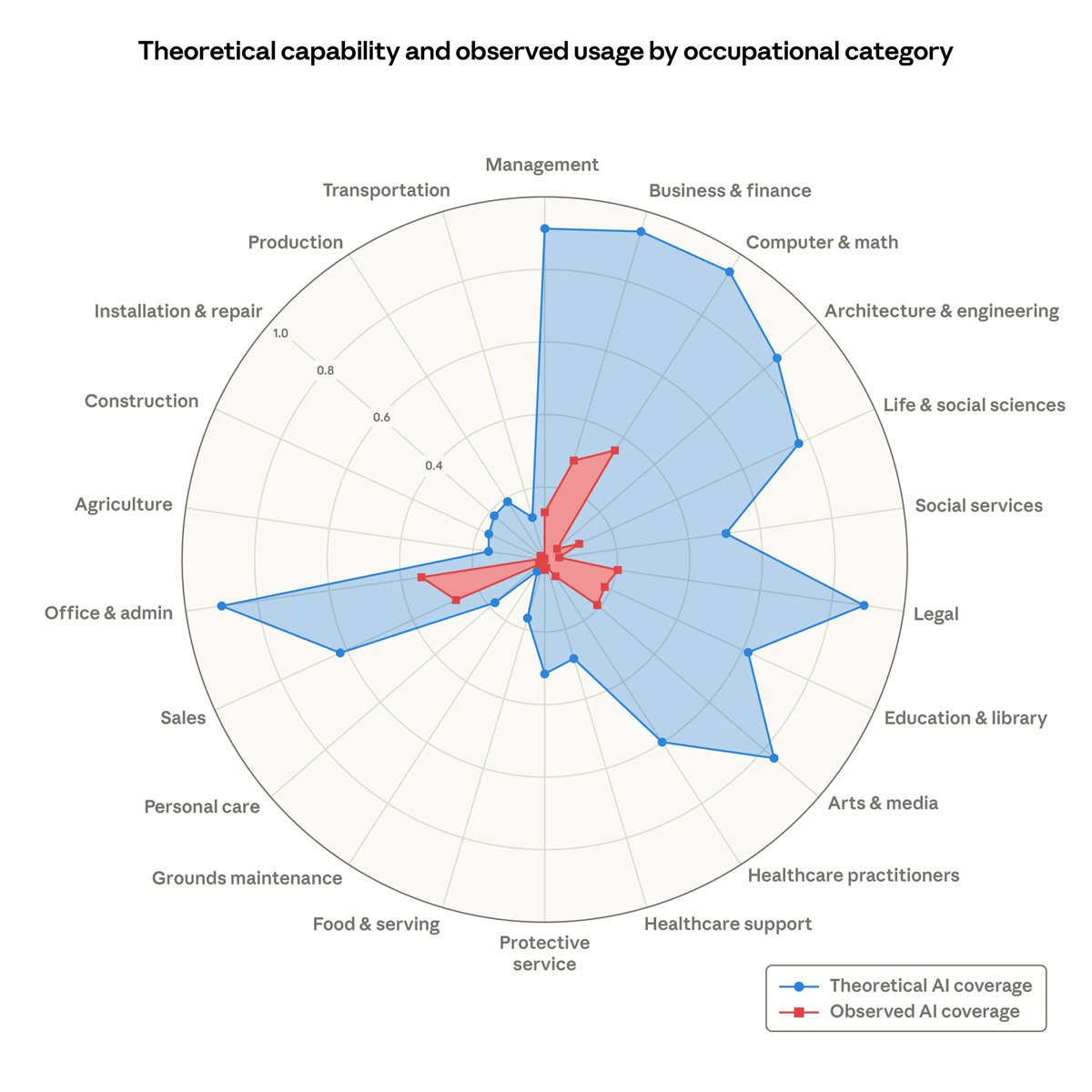
Labor market impacts of AI (source: Anthropic report): anthropic.com/research/labor…
Ironically, the one's not severely impacted by AI alone will be automated and replaced with robots and AI.
English
New Google Workspace CLI is so useful, not having to deal with their vast API directly, and also a better way for AI agents to interact.
While CLI/TUI are regaining popularity, simple well-documented APIs for some tools may suffice with a few curl calls.
github.com/googleworkspac…
English