Post

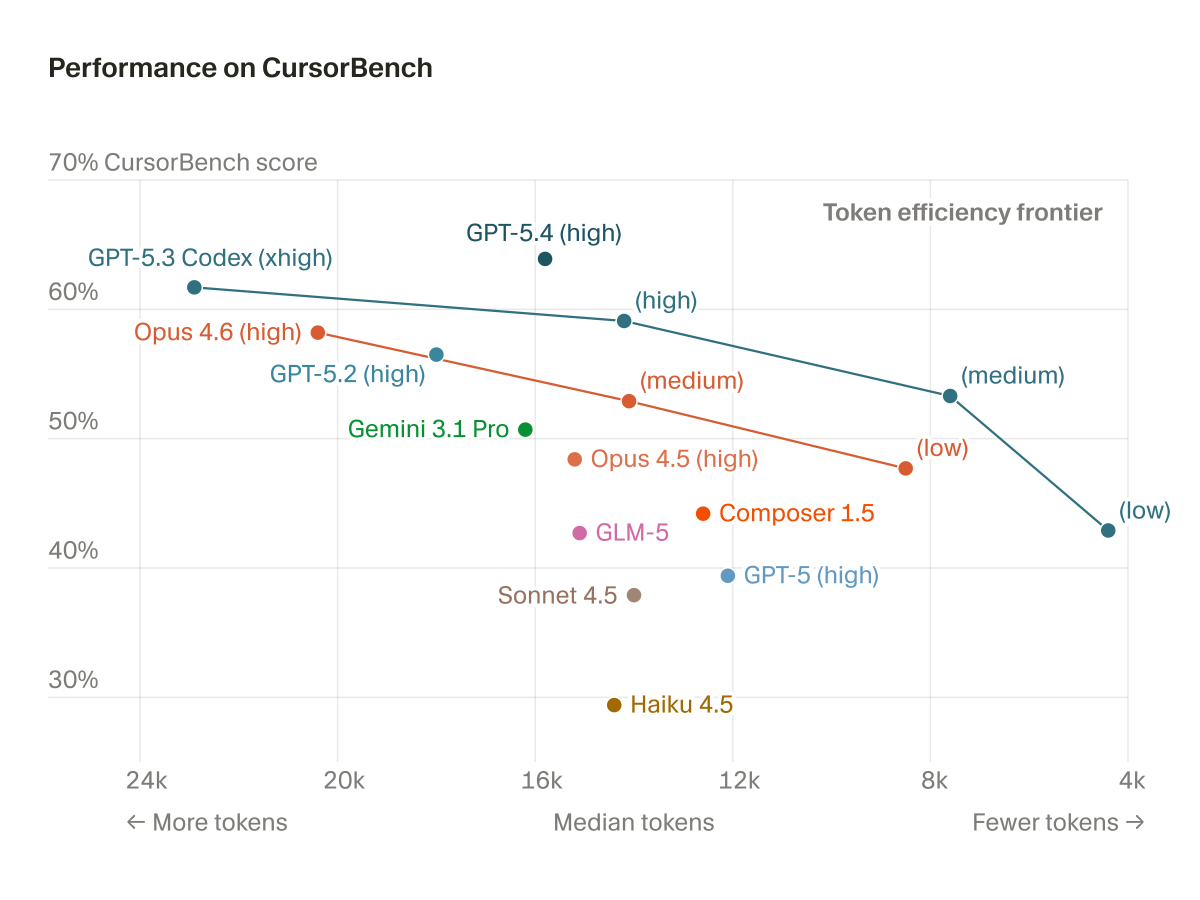

@cursor_ai cursor, i love you, but having <-- more tokens - median tokens - less tokens --> is a bizarre graph
English


@cursor_ai Coding != planning
Would be cool to see a similar report but focused on planing mode or even on creating architecture
Cc @benln
English

@cursor_ai I’d love to see more open weight models on here to see how they compare. Any chance we can get Qwen / Kimi on here?
English

@cursor_ai 5.4 high is just at another level
no wonder why its my fav model
English

@cursor_ai Combining offline benchmarks with real usage evals gives a much clearer picture of model performance. Public benchmarks alone no longer reflect how models behave in real coding workflows.
English

@cursor_ai Intelligence vs efficiency is the right framing. A model that reasons brilliantly but burns through tokens isn't practical for real workflows.
English

@cursor_ai Measuring efficiency alongside intelligence is key. Standard benchmarks don’t always capture how these models actually perform in a real agentic workflow.
English


@cursor_ai Here's the graph with the same data, but plotted against the actual output cost for each (Composer 1.5 output from Cursor docs is $17.5). Although this doesn't account for >200K Opus 4.6/>272K GPT 5.4/Gemini 3.1 >200K.
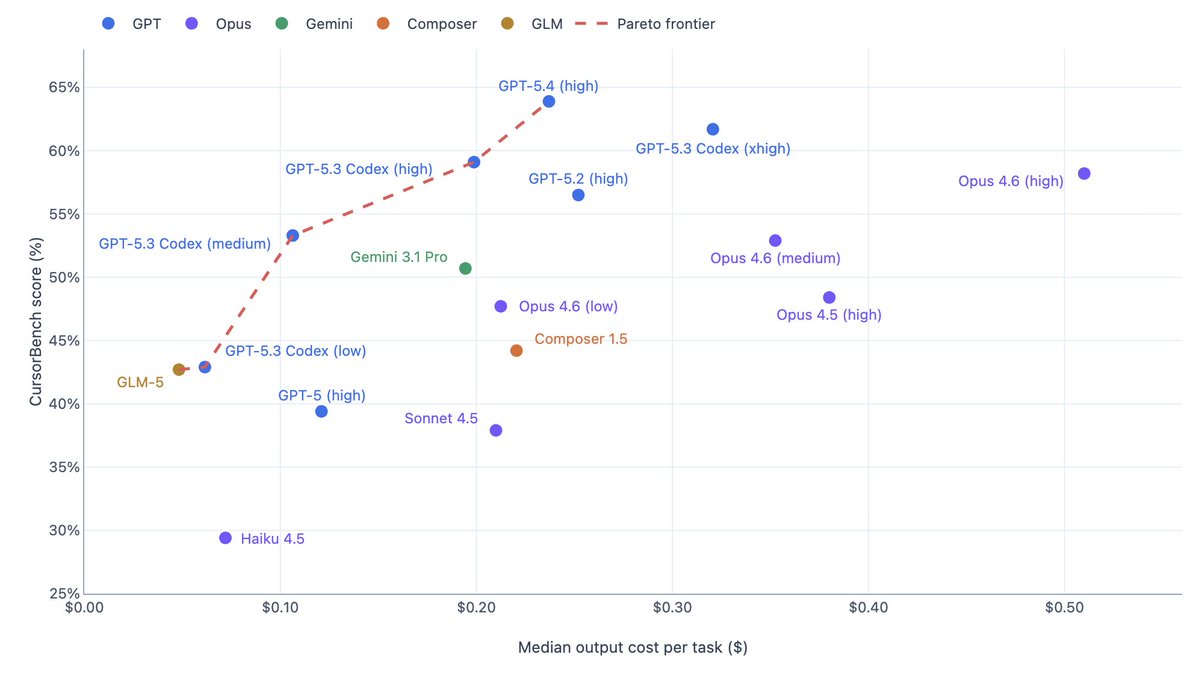
English

@cursor_ai Token pricing varies wildly across the models, so I plotted my long-horizon evals against $ cost. Frontier shifts big time
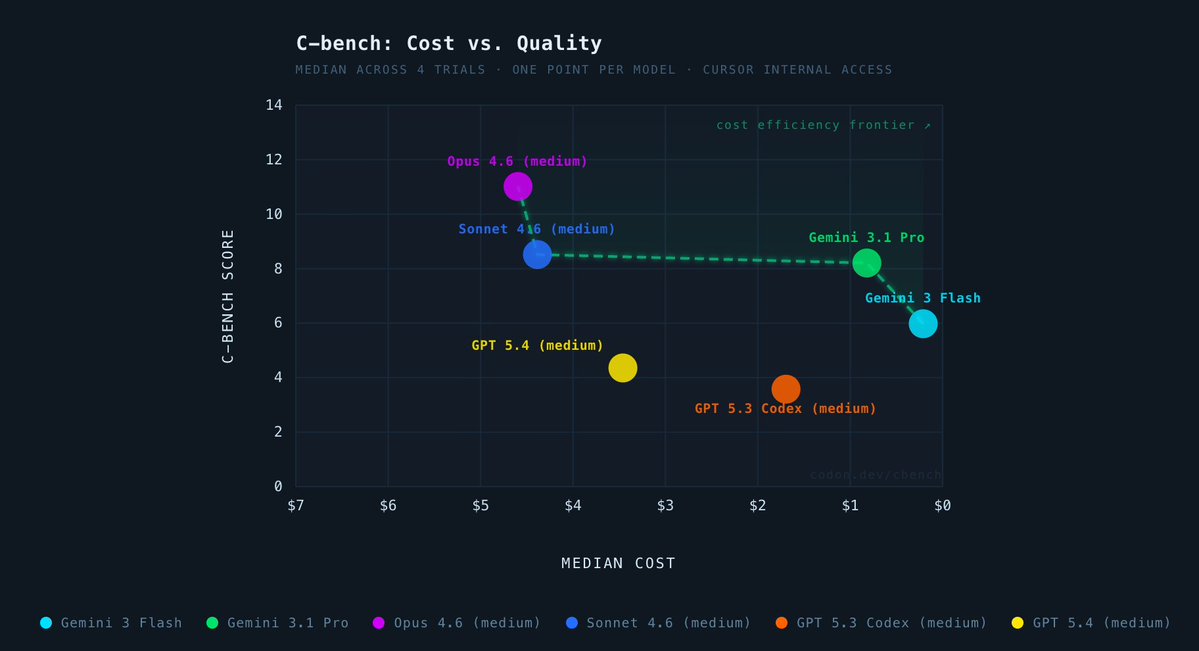
English

@cursor_ai been waiting a while for this. finally getting some numbers behind cursor engs tweeting "btw i only use 5.4 now" 😂 pretty interesting!
English


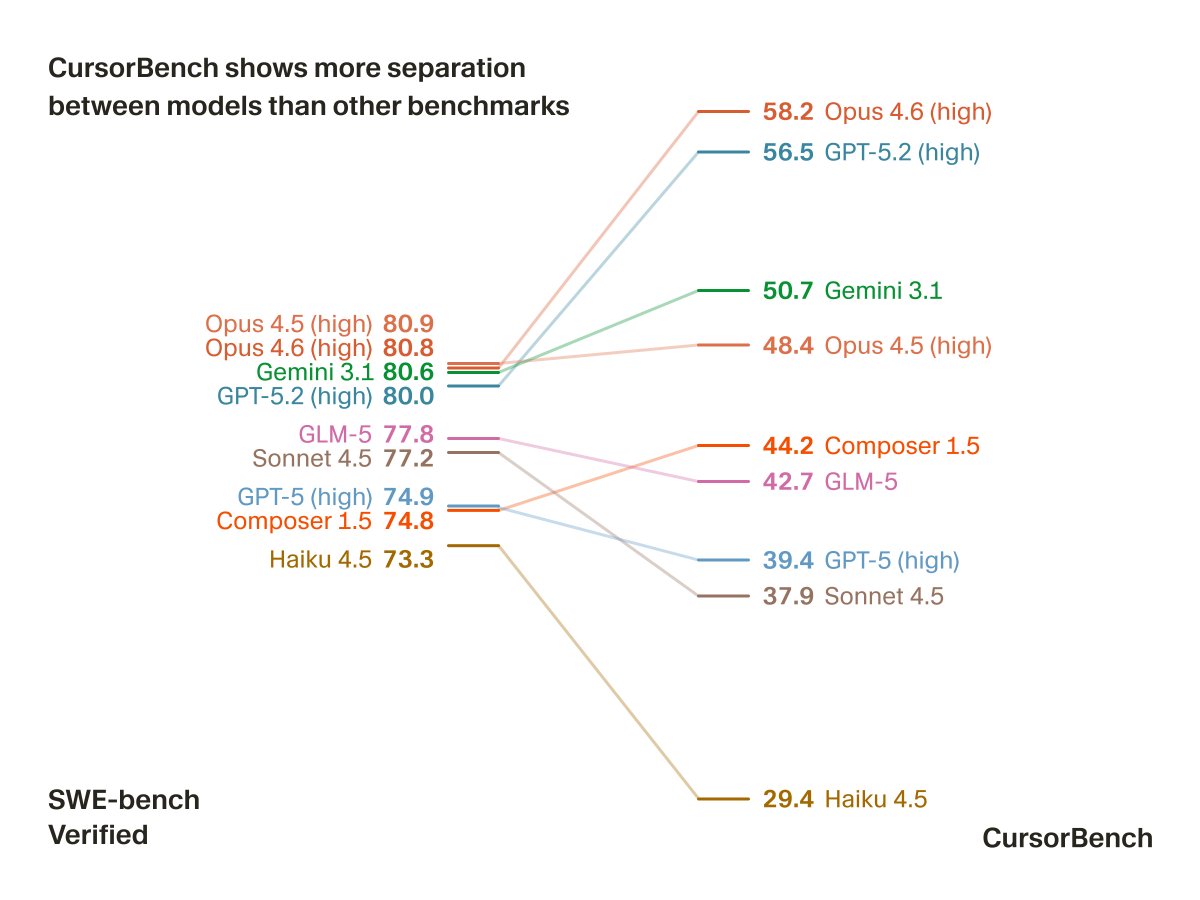
cursor building their own benchmark because public ones are too saturated to differentiate models is the right call. on SWE-bench, the top models all cluster between 73 and 81, basically useless for picking the best tool. CursorBench spreads them from 29 to 58, which is actually actionable.
the token efficiency axis is the part i find most interesting. Opus 4.6 sitting on the efficiency frontier means it's delivering top tier performance without the token cost of some of the GPT-5 variants. that's a meaningful distinction when you're running thousands of completions a day.
generic benchmarks were designed before agentic coding existed. this is what evaluation looks like when it's built around how models actually get used.
English

@cursor_ai @aye_aye_kaplan According to the graph, GPT-5.4 is better than 5.3 Codex High while using fewer tokens.
That resonates well with my experience.
English



It’s time to dance! Get it on tournament action with Bonus Bets from FanDuel.
English


@cursor_ai Benchmarking intelligence and efficiency separately is the right call — a model that gets the answer right but burns 10x the tokens is a very different tool than one that's fast but sloppy. Curious how this correlates with real user satisfaction in practice.
English

@cursor_ai This graph loses credibility when codex and got5.4 are above Opus
English


Interesting direction.
Benchmarking models on agentic coding tasks instead of just raw outputs could better reflect how tools like Cursor are actually used in real workflows.
The real winners won’t just be the most intelligent models they’ll be the ones that balance reasoning, speed, and cost efficiency.

English

@cursor_ai The workflow shift matters more than the demo.
English

@cursor_ai efficiency axis is the sleeper metric here. been running agents 24/7 and the token cost difference between models matters way more than benchmark gaps when youre burning through millions of tokens a week
English


@cursor_ai surprised to see opus 4.5 so much lower than open 4.6, my experience with it has been that it was at best as good as 4.5 if not worse, while using more tokens
English

Not surprised. Ive been trying auto lately and letting it roll. Composer 1.5 is fine for most things for my codebases. I bring out the big guns 5.3 codex for planning. I dont use @AnthropicAI anymore because they were so oblivious to rule of law and government usage of AI and similar tech since Obama era even lawful use that it is egregious so much that I am not using their models until their status is restored and they educate themselves or decide to not work with government. Its that simple.
English

@cursor_ai Every benchmark chart turns into marketing collateral in 48 hours. Show retention by model in production, then we can talk about “intelligence.”
English

@cursor_ai 5.4 high is very good - Opus is not far behind but tend to make mistakes that turns into regressions unless you smoke test behind.
5.4 is doing test in its changes automatically and or proposed test plan, only downside at least for me it’s react and front end stuff.
English

@cursor_ai @davidgomes thanks for sharing, but I find it odd thar sonnet is performing that badly?🤔
English

@cursor_ai Impressive frontier push — GPT-5.4 (high) hits strong Pareto balance with notably better token efficiency than 5.3 Codex while keeping high CursorBench score. Real agentic eval + online signals make this leaderboard more trustworthy than saturated public benches. Solid work.
English

@cursor_ai good eval but what is that graph lmao could've simply done low to high 😭
English


Free Cone Day is here! Come celebrate with us at a DQ location on today by getting a FREE small vanilla cone 🍦
English

@cursor_ai Neat, but in the real world speed matters... we need more axes 😅
@claudeai opus has been our top model for the past few months, and that hasn't changed.
5.3 codex for deep reasoning, composer or haiku for fast tasks
English

@cursor_ai Efficiency vs intelligence isn’t a tradeoff to pick — it’s a routing decision. The chart is most useful when you read it as a routing table: which model for planning, which for generation, which for review. The benchmark is the input to the router, not the metric to optimize.
English