78iger
435 posts



Hey @RealRusty @EFIEBER_ANDRE das könnte euch vielleicht interessieren: m.youtube.com/watch?v=rFZL2w…
Deutsch
Hey @lmstudiodevs Can we have read access for the LLMs in the "working directories" folder for your VS Code sandbox? One level up from currently. This would be very helpful for small machines, allowing them to summarize one chat and read the results in the next chat.
English
@PhilosophyOfPhy Are you asking about the properties or the definition of time? A sequence of events interwoven flexibly in space sounds like a pretty good description, doesn't it? 🤔
English


@Karel_Datel @ai_for_success Momentan nicht. Nur mit "Übersetzen" Button.
Deutsch

@78iger @ai_for_success Jestliže tito moji odpověď psanou v češtině vidíte psanou německy, tak to je velký pokrok
Čeština

तो X ने ऑटोमैटिक ट्रांसलेशन लॉन्च कर दिया है।
क्या इसका मतलब है कि मैं हिंदी में लिख सकता हूँ और आपको फिर भी यह इंग्लिश में दिखेगा? मैं आमतौर पर हिंदी में नहीं लिखता, बस जिज्ञासा है।
आपको यह पोस्ट किस भाषा में दिख रही है?
हिन्दी

@78iger @ai_for_success Estou no Brasil e li em português. Você lê minha resposta em hindi ou inglês?
Português
@Raskornikov1 @ai_for_success Hier wurde es in Türkisch angezeigt. Ich kann es aber Übersetzen lassen. Grok hat vielleicht gerade viel zu tun? (geschrieben in deutsch)
Deutsch

@78iger @ai_for_success türkçe olarak okudum türkçe yazıyorum. sen hangi dilde okuyorsun bilmiyorum
Türkçe
Deutsch

Português
@Isinfir @ai_for_success Es gibt einen Button "Originalsprache anzeigen" 😉
Deutsch

@78iger @ai_for_success Du musst bedenken, wenn Deine Antwort so ubersetzt wird, dass das sprachliche "deutsch" nachher auch als hindi bei ihm angezeigt wirde, denkt er, dass Du in seiner Sprache geantwortet hast
Deutsch
@LesTurquie @ai_for_success Ihr Post wurde mir in Türkisch angezeigt. Übersetzung funktioniert aber. Grok muss wohl noch ein bisschen lernen.
Deutsch

@78iger @ai_for_success İkinizin konuşmasını da Türkçe okudum. Bu nası
Türkçe
@ai_for_success Cool, das hier wird mir zwar englisch angezeigt aber mit Überetzungsoption. 👍
Deutsch
@78iger I got the response back in German 👍 but yeah if it can detect main post language and auto translate that would be huge.
English


@RGVaerialphotos "Spaceballs" is on freeTV right now. That's a really tough choice. 😁
English

Starbase Weekly is live in 1.5 hours!
Tune in at noon Central. Here's a photo of Pad 2:

English
@karpathy I think I'll try something like that on the edge. Problem: Limited context, few tokens/s, outdated knowledge. Solution: Expand knowledge using minimal resources and create a kind of prompt injection for the next chat, repeat, and finally create a training set for fine-tuning.
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English


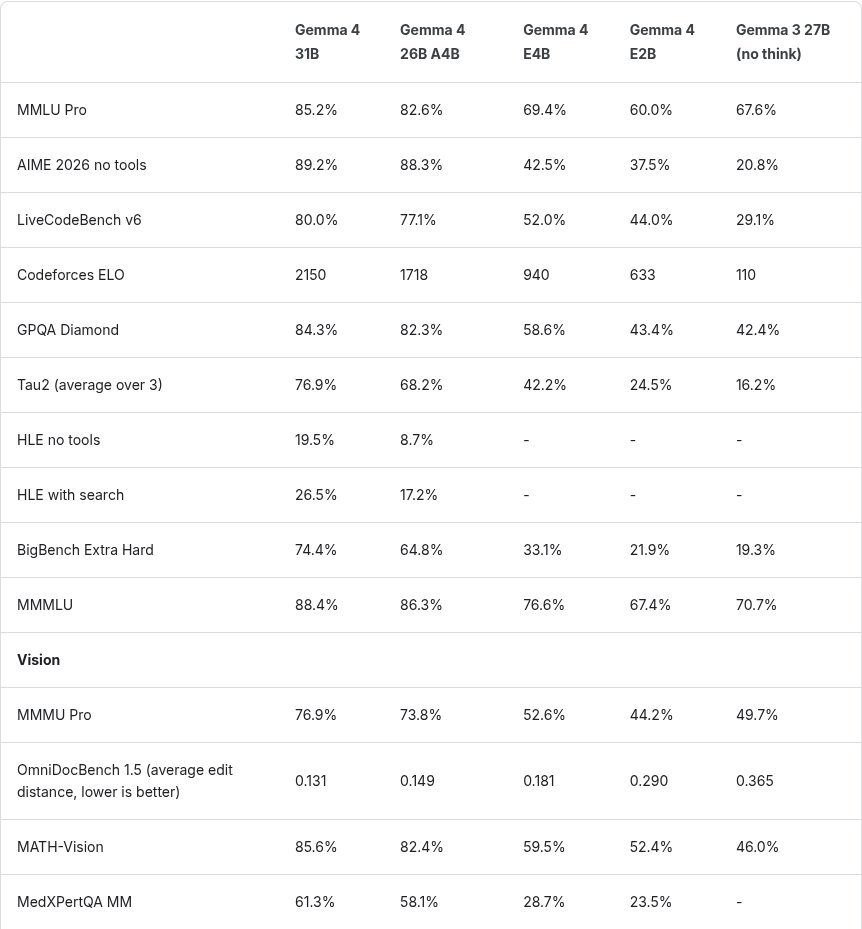
So we know Gemma 4 is good at tool calling, but what about web coding?
I threw 4 UI screenshots at three Gemma 4 models and said rebuild this, one shot, no hand-holding, just image in, code out.
Model lineup:
- E4B
- 26B A4B (MoE)
- 31B Dense
(skipped the E2B this round)
Let me know which one you think cooked the hardest
English
@kimmonismus Yes, using GLM 4.7 Flash, Qwen 3.5, and Gemma 4 has indeed resulted in a significant improvement in performance on local machines.
English

To explain why I consider Gemma 4 a bigger release than most people realize.
This is a big deal because models like Gemma 4 E4B can run directly on devices, bringing powerful AI (even a 2B model ~60% on MMLU Pro) to phones, laptops, and edge systems without relying on the cloud, making it faster, cheaper, and more private.
At the same time, their strong performance on everyday benchmarks shows that useful intelligence no longer requires massive infrastructure. We’re entering a phase where capable AI becomes ubiquitous, embedded into everyday devices rather than locked inside data centers.
And the jump from Gemma 3 to Gemma 4 further demonstrates how well such small models will perform in another 12 months. Today they have GPT-4o levels. In a year, perhaps GPT-5 levels. We will see.
English
@renderfiction @cryptostaker999 I tried it with the latest version of Firefox on win11. There are a lot of errors in the logs, but it works so far.
English

English
@renderfiction @cryptostaker999 Nice. Can we have laptimes or did I miss something? F- Zero style. 👍
English
I vibe coded it with Gemini using a free chat bot (no agent). I didn't use a template but the LLMs are just so good that you can get working mechanics quickly.
I use Three.js + Rapier, they work really well together.
Most vibe coders use 3D model generators but I have fun making stuff in Blender so I modeled everything by hand.
English