Naka-pin na Tweet

Ren
272 posts
@FakeMaidenMaker
🧠 First Principle Thinking 🔨 Build in Public 🤖 AI 开发者 📈 量化策略研究者 持续分享 AI/科技/投资/创业 领域干货内容


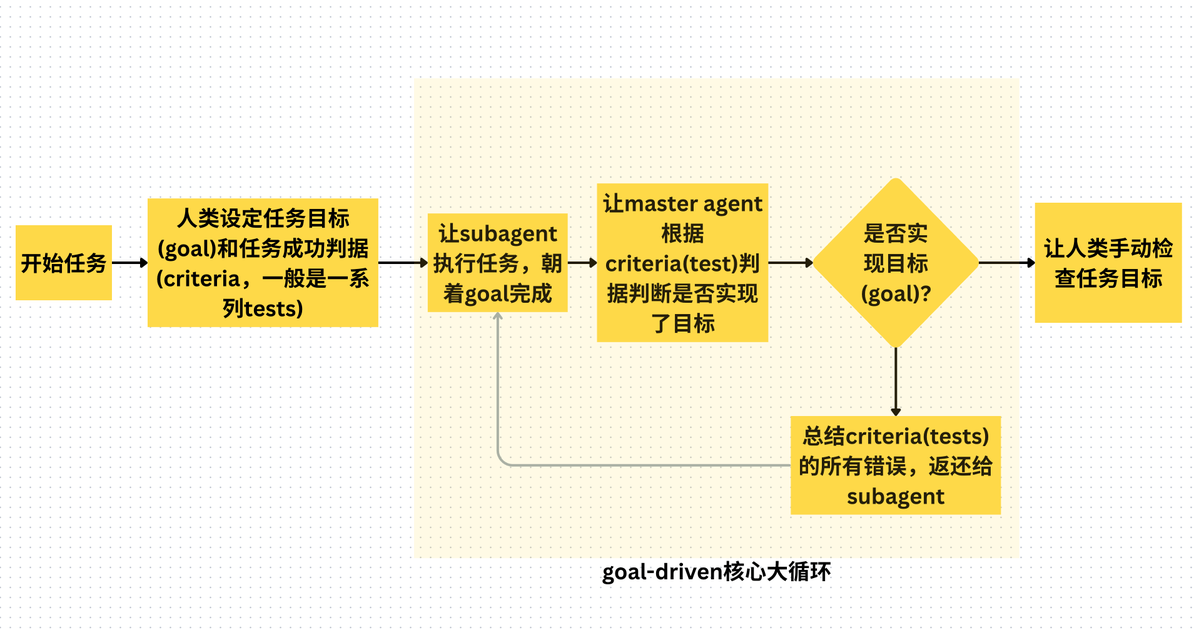
没有谁该 first,至少很长一段时间,AI 和人类在开发中的关系,是结对关系。谁也离不开谁。 哪种完全撒手让 AI 从头干到尾的,看起来很潮,实际上是执行人根本不知道自己想要什么,也根本不知道 AI 在干什么。因为 AI 干出什么,他们都会觉得超出预期。









感谢分享 这两点我有疑惑: 1/ 如果历史会话够长,Hermes 采用什么方式实现搜索,能比 OpenClaw 的压缩更快?而且能精确到减少 30-60% 的 Token 消耗。纯依靠大模型的缓存,肯定不是唯一解 2/ 自动生成 skill, 是否可以关掉?纯自动化会带来更多的 Token 消耗和后期的维护。如果不加以收敛,Skill 库会爆炸性膨胀。不知道 Hermes 对 Skill 生命周期怎么治理




