
English
Jonathan Edwards
924 posts
@JonNichEdwards
A student of causal inference

Want to know about the mechanisms by which a treatment affects an outcome? This paper develops tools for testing hypotheses about mechanisms under weak assumptions. Check it out! New paper by @jondr44 and Kwon: restud.com/testing-mechan… #REStud #EconX #EconTwitter




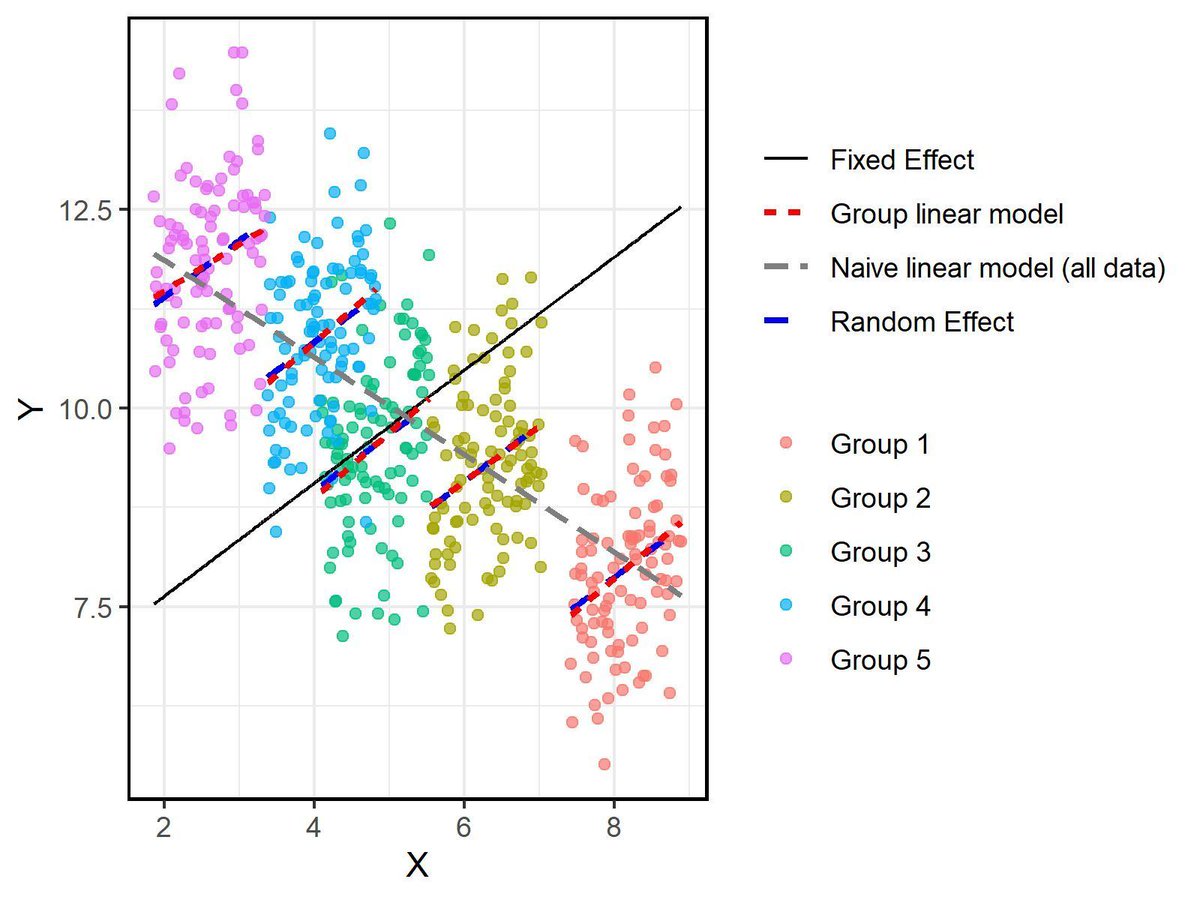



@DongNguyeb imo it is misleading to state the problem here as being about collapsible/noncollapsible. The issue is the model, whether it is linear or whether it is nonlinear and consistent, unbiased etc... the bias in multicollapsibility is about estimating E[Y|D] by
@DongNguyeb This whole statement is too vague to be sure what you are trying to say, but basically there is nothing special about collapsible measures except that they are collapsible. One measure might be meaningful in one instance not in the other, in the end the most meaningful "measure"