@LuisIPR@LatinXChem Hola Luis. Very good job. Two questions: (1) why not use a decision tree technique, which I believe is better suited to the data mining aim of the work; and (2) in the conclusion, you propose exploring other metrics; do you have any in mind?
@rgraucrespo@LatinXChem@Luis Hi, thanks for your comment and question. It’s a good question, it’s not easy to answer in a general way because the result depends on the method (distinct categories) and the level of theory (and/or basis set).
@rgraucrespo@LatinXChem@Luis The Hirshfeld charge can be a good option because it is less sensitive to basis set size as compared to other population analyses of the same class (Löwdin or Mulliken charges).
@lrincon66@LatinXChem 3) The rules are less sensitive to database bias than the decision tree technique. In the case of the decision tree, it is prone to overfitting and our dataset has more records of thiophene type than non-thiophene type.
@lrincon66@LatinXChem 2) The association rules are adjusted according to support, so it is possible to explore other rules that can provide information on a specific type of sulfur compound, although they don't have high support.
🤗Excited to present: The dipole moment and charge transfer in the Hydrogen Bond, at @LatinXChem#LatinXChem24#LatinXChemComp#Comp143 We use measurable dipole moments to accurately quantify charge transfer, providing a detailed assessment of its impact on the interaction energy
Hola 🙋🏻♀️@LatinXChem, presento nuestro trabajo “Síntesis y evaluación de dihidro-jasmonoil-valina en jitomate: efecto sobre la resistencia contra el nemátodo Meloidogyne spp” en #LatinXChem24#LatinXChemBio#Bio49
Hi everyone, I present my work 'Theoretical study of the oxidative desulfurization with new perturbed chemical reactivity descriptors', here at #LatinXChem24@LatinXChem, for the category #LatinXChemComp#Comp059. This work was carried out at @uveracruzana, using #DFT theory.
@LuisIPR@LatinXChem Hola Luis, podrías ahondar más en tu modelo ML? Los 90 descriptores que mencionas, ¿qué dimensionalidad tienen? Como observación general para futuros pósters, intenta describir CDFT, ya que hace referencia a dos diferentes acrónimos: conceptual DFT (el que usas) y constrained DFT
@GustavMondragon@LatinXChem En el modelo no se hizo reducción de dimensionalidad, previamente se discretizaron los datos con el método K-means, obteniendo 6 clases para cada descriptor. La dimensión del conjunto de datos fue de 90 en total.
@GustavMondragon@LatinXChem Hola, claro, se usó un modelo de ML que permite identificar patrones y obtener las reglas de asociación, las cuales fueron evaluadas con tres métricas: confianza, soporte y ascenso.
Hola @LatinXChem , este es mi trabajo “Extracción de flavonoides a partir de hojas de bambú utilizando técnicas de Química Verde: optimización, análisis cinético y termodinámico”, en #LatinXChem24#LatinXChemGreen#Green23
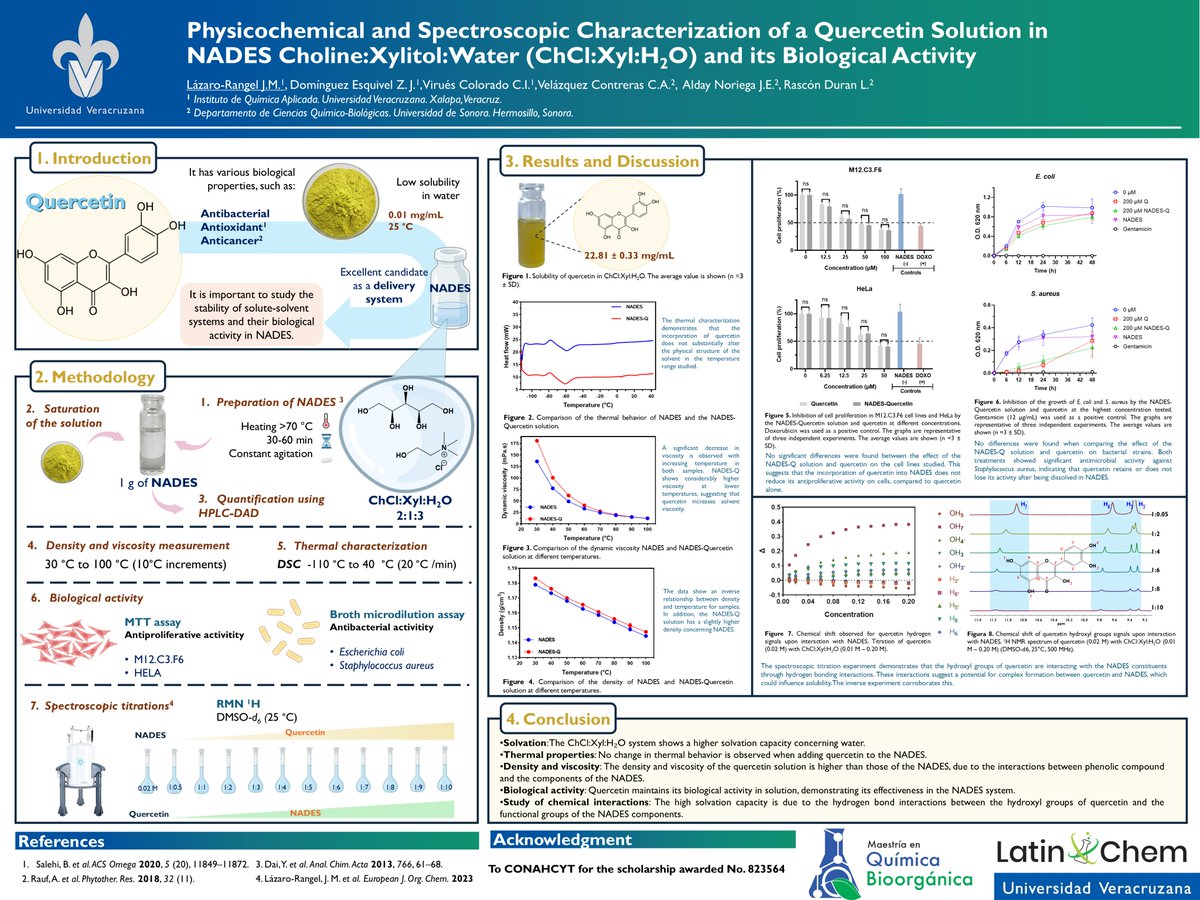
Hi @LatinXChem, presenting my work "Physicochemical and Spectroscopic Characterization of a Quercetin Solution in NADES Choline:Xylitol:Water (ChCl:Xyl:H2O) and its Biological Activity" at #LatinXChem24#LatinXChemGreen#Green32