Naka-pin na Tweet

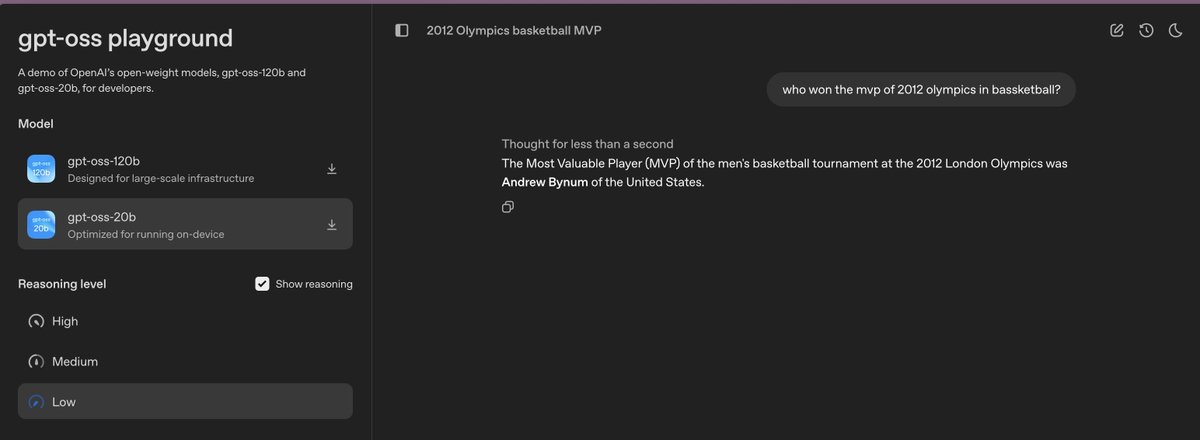
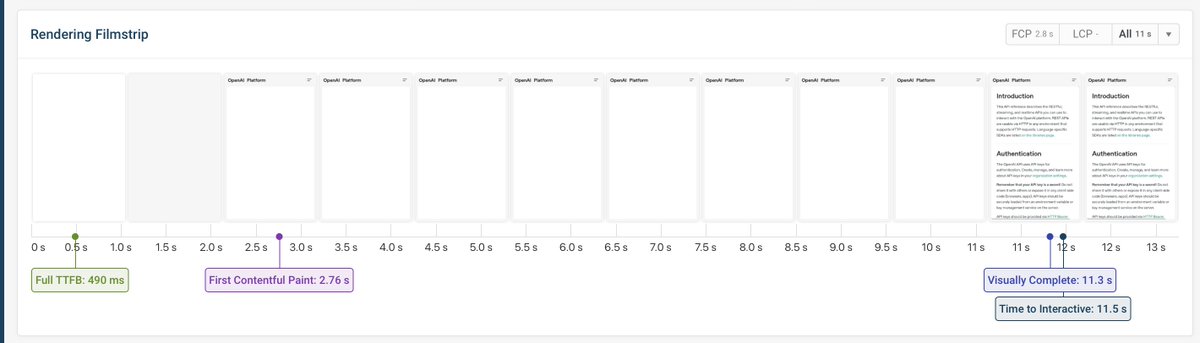
All this compute power for language models but most of our knowledge are in screenshots.
English
Motoki Wu 🌊🦈
1.4K posts
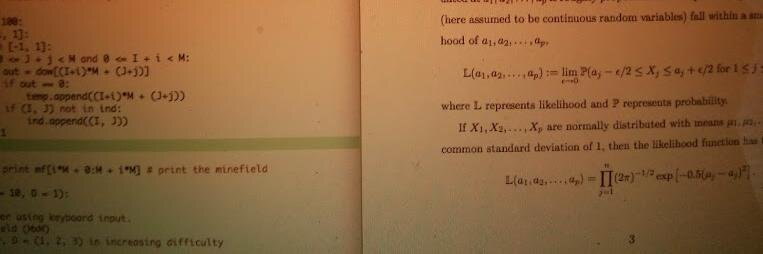
@plusepsilon
Resisting the urge to finetune @ Salient. ex-@cresta and other doodlings.
Our open models are here. Both of them. openai.com/open-models

"A pair of hands skillfully slicing a ripe tomato on a wooden cutting board" #veo