
can't really stand the expression "load-bearing" any more, sorry
English
Thomas Wolf
5.2K posts

@Thom_Wolf
Co-founder at @HuggingFace - moonshots - angel




42 is the answer to everything. This is @EntireHQ’s answer to Git in the era of agents: fast, independent, distributed. Mirror your GitHub repos, let your agents clone and pull from the region(s) of your choice, and…we're open sourcing it. 🤖


3) Harnesses make a huge difference in cost-performance. The very simple Pi harness (@badlogicgames) got the same success rate as harnesses from the LLM vendors with Opus and GPT 5.5, but at 2x less cost! Seems to be mainly due to smaller inputs to the LLM.

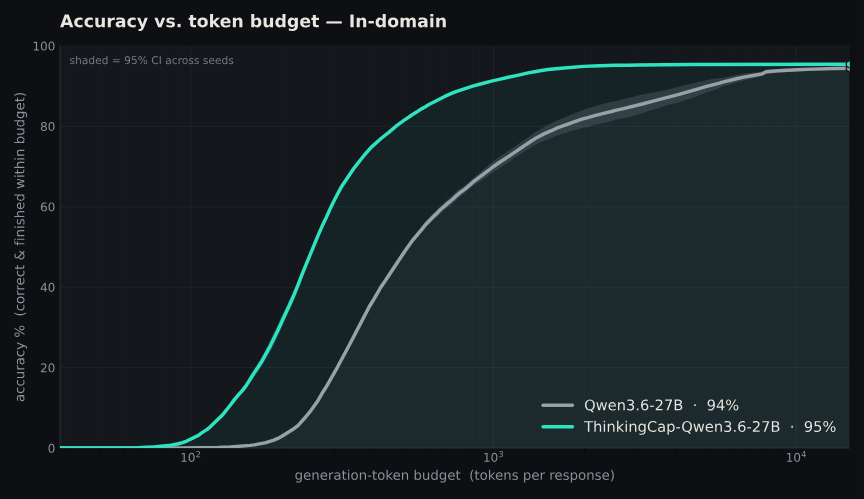
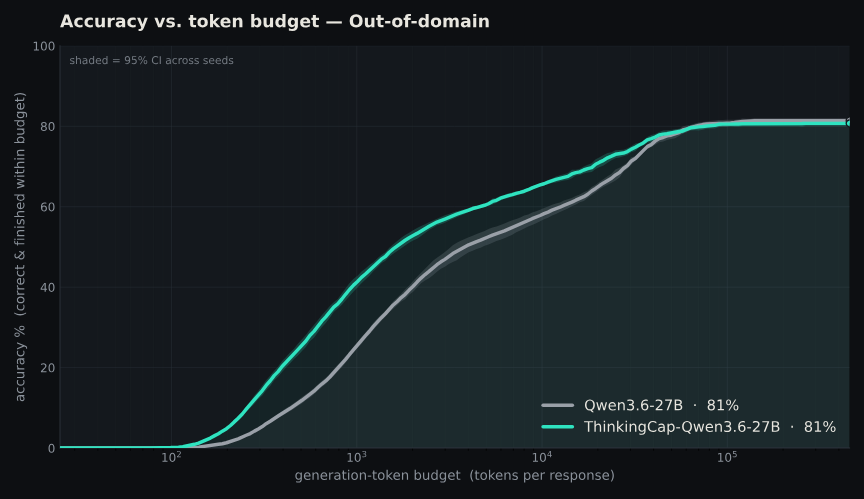
Today we’re announcing our “ThinkingCap” efficient model series with a 2× thinking token reduction on average in Qwen 3.6 27B, with up to 10x faster generation on individual examples.








