
Wisnu Saputra
2.2K posts

Wisnu Saputra
@wsme_dev
Product Engineer | Building @quickcap_mac
Sumali Aralık 2017
618 Sinusundan92 Mga Tagasunod

@davidsunarna Lebih tertarik bagaiamana cara mendapatkan harley 👀
Indonesia

Kira2 kalau gua hari ini bahas biaya perawatan harley pada tertarik ga? Berapa ganti olinya, harga part2nya, seberapa sering rusak. 🤣 Gua tulis pake tangan gak pake AI kayak si bocah bader 🫵
Indonesia
Wisnu Saputra nag-retweet

Holy shit.
New Google Stitch is scary
Designers, I think we're cooked
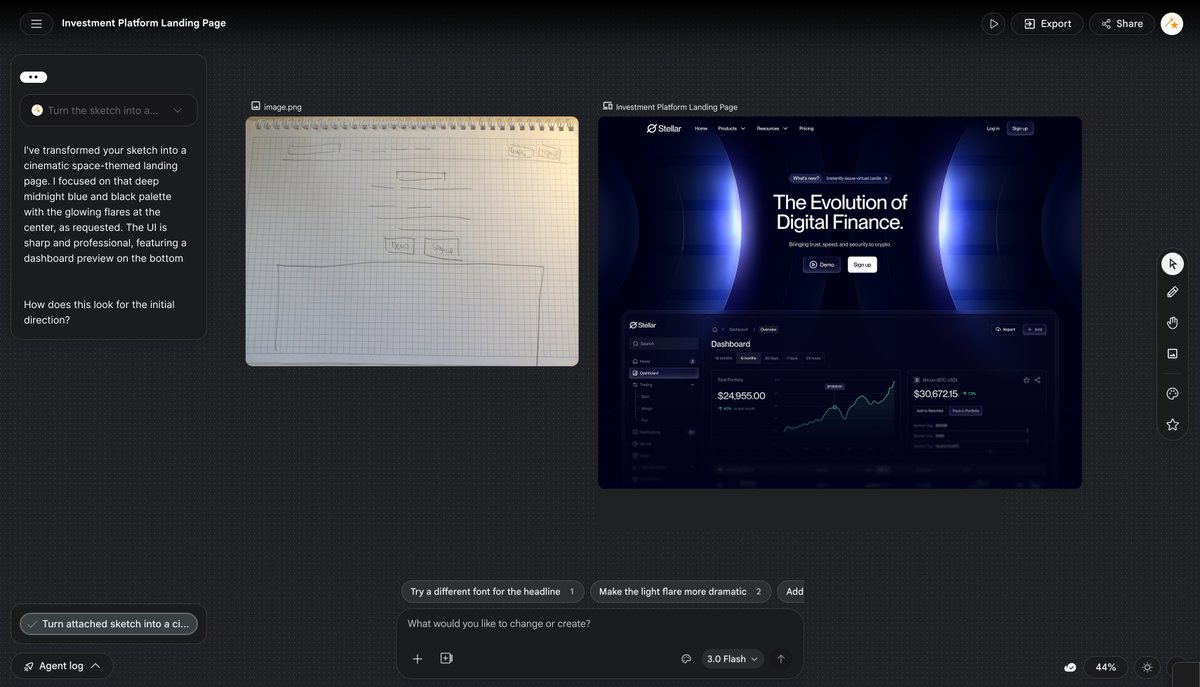
Stitch by Google@stitchbygoogle
Meet the new Stitch, your vibe design partner. Here are 5 major upgrades to help you create, iterate and collaborate: 🎨 AI-Native Canvas 🧠 Smarter Design Agent 🎙️ Voice ⚡️ Instant Prototypes 📐 Design Systems and DESIGN.md Rolling out now. Details and product walkthrough video in 🧵
English

Ya Allah lancarkanlah submissionku 🤞

Imre Nagi@imrenagi
Ngesetup app store connect buat app rilis pertama kali painful juga ya. 😂
Indonesia

Racikan sendiri, Pak. Embed terminal juga di situ, tapi ga untuk penggunaan yang ekstensif.


Didik | Factorio Planner 🏭@did1k
@ariaghora nge-vibe code pakai apa sekarang?
Indonesia

Just try Composer 2:
→ for new apps, it makes WAY cleaner and smarter code than Opus and Codex
→ makes reducers, respects clean code
→ respects the UI and features I ask for perfectly
It's a good model. Really.

Cursor@cursor_ai
Composer 2 is now available in Cursor.
English
Wisnu Saputra nag-retweet

@rhmi_fii Kalau udah yakin mau pake linux langsung hapus windows atau device baru
Tapi kalau masih coba” cukup pake WSL untuk adaptasi dulu
Indonesia

@F2aldi Seenggaknya dalam satu devisi ada atasan atau orang yang testing sih harusnya
Indonesia

Vibe code ga mslah. Asalkan sistemnya bener.
Hrusnya dipertanyakan juga.
UI gaji developernya berapa?
UI hiring Designer gak?
Sehingga mreka sampek skip buat testing, desain vibe code juga?
Itu harusnya jadi pertanyaan kita.
Apa jangan2 hiring junior? Ga ada seniornya?
endruw@andrew4ranting
not just ts ui, tpi masih banyak lgi web-web UI baru yg vibe coded 🥀🥀🥀 certificate.ui.ac.id Ipis.ui.ac.id padahal design website lama UI itu classy parah, sekarang udah jadi AI slop kayak gini. Sangat disayangkan
Indonesia

Ngoding sekarang pake uang, dan sistemnya berasa gacha gitu
Kadang modelnya lagi bagus ya bagus, kalau lagi jelek ya jelek.
Harga subscription juga pengaruh, berasa pay to win 🫠
Indonesia

Temen-temen kalau lagi mabok kecubung jangan pegang HP.
PTKP terendah di indonesia itu 54.000.000
artinya minimal penghasilan setahun dibawah itu gak kena pajak.
jadi banyak orang yang gajinya dibawah itu ☺️☺️☺️
Tekarok 007@tekarok007
Dari List panjang gini isinya bisa dirangkum "Bayar Pajak", Itu doang dah. Tapi lupa, bisa punya semua banyak list itu yah karena "Pajak" itu. Punya mobil kalau pemerintah tidak bangun jalan raya, yah bentaran hancur mobilmu kena hantam batu dan lumpur. Juga pajak itu buat bangun fasilitas, sehingga kamu tidak kayak hidup di tengah hutan. Sedang menurut data yang bayar pajak di Indonesia cuma 8 juta saja dari 280 juta penduduk, ironis banget yah. Artinya apa itu? Banyak yang cuma ngaku-ngaku dirinya bayar pajak, padahal cuma habisin pajak dengan makan subsidi dari duit negara setiap hari.
Indonesia
@_mandaputtra @mechnclgrl Haha, pada dasarnya kita terbuat dari tanah mustahil menandingi cahaya
Mungkin di surga nanti baru terwujud
Indonesia

@wsme_dev @mechnclgrl Wkwkw, ya sambil ngajari pakai ChatGPT berarti nu 🤣
Indonesia

@rudrank Wow.. Is this the right time to switch subscriptions to Minimax?
English

Wow MiniMax M2.7 is out already I did not get a chance to write a blog post
TL;DR feels much nicer to use than M2.5
Pushes back on features/plans like GPT/Codex models which is something I was really looking forward to

English
@mechnclgrl "Mas, kenapa kok kita gabisa lebih cepat dari cahaya?"
dan segala pertanyaan teori relativitas lainnya.
Indonesia
Wadoo xiaomi join war
Artificial Analysis@ArtificialAnlys
Xiaomi has released MiMo-V2-Pro, which scores 49 on the Artificial Analysis Intelligence Index, placing it between Kimi K2.5 and GLM-5 @Xiaomi's MiMo-V2-Pro is a new reasoning model and a significant upgrade over their prior open weights release, MiMo-V2-Flash (309B total / 15B active, MIT license), which scores 41 on the Intelligence Index. Xiaomi has not yet released the weights of this model and it is currently only available via Xiaomi's first-party API. Key takeaways: ➤ MiMo-V2-Pro scores 49 on the Artificial Analysis Intelligence Index behind GLM-5 (Reasoning, 50). It is ahead of Kimi K2.5 (Reasoning, 47) and Qwen3.5 397B A17B (Reasoning, 45). On the overall leaderboard, it places #10, just behind GPT-5.2 Codex (xhigh, 49) and ahead of Grok 4.20 Beta (Reasoning, 48) ➤ Leading Elo of 1426 on GDPval-AA (Agentic Real-World Work Tasks), ahead of peer models: On GDPval-AA, MiMo-V2-Pro places ahead of GLM-5 (Reasoning, 1406), Kimi K2.5 (Reasoning, 1283), and Qwen3.5 397B A17B (Reasoning, 1209). GPT-5.4 (xhigh) and Claude Sonnet 4.6 (Adaptive Reasoning, max effort) have an Elo of 1667 and 1633 respectively ➤ Competitive AA-Omniscience Index driven by low hallucination: MiMo-V2-Pro scores +5, ahead of GLM-5 (Reasoning, +2), Kimi K2.5 (Reasoning, -8), and Qwen3.5 397B A17B (Reasoning, -30). For context, Claude Opus 4.6 (Adaptive Reasoning, max effort, +14) and Gemini 3.1 Pro Preview (+33) remain ahead ➤ MiMo-V2-Pro is more token efficient than peers. It used 77M output tokens to run the Artificial Analysis Intelligence Index, significantly less than GLM-5 (Reasoning, 109M) and Kimi K2.5 (Reasoning, 89M) ➤ MiMo-V2-Pro costs $348 to run the Artificial Analysis Intelligence Index at $1/$3 per 1M input/output tokens. This is less expensive than GLM-5 despite scoring only 1 point lower on the Intelligence Index. For comparison, GPT-5.2 (xhigh) cost $2,304 and Claude Opus 4.6 (Adaptive Reasoning, max effort) cost $2,486 Key model information: ➤ Context window: 1M tokens ➤ Pricing: $1/$3 per 1M input/output tokens, for 256K token input and $2/$6 per 1M input/output tokens for 1M token input ➤ Availability: Xiaomi first-party API only ➤ Modality: Text input and output only (no multimodality)
Filipino
Saking susahnya lapor pajak bagi orang awam, sampe ada yang buka jasa
Btw, kalau mau agak effort ke KPP ada anak magang bisa bantu laporin juga secara gratis
Ahli Pembukuan 📚@AkuntanMilenial
"Yok bisa sampe nihil yookk" 😌
Indonesia