پن کیا گیا ٹویٹ

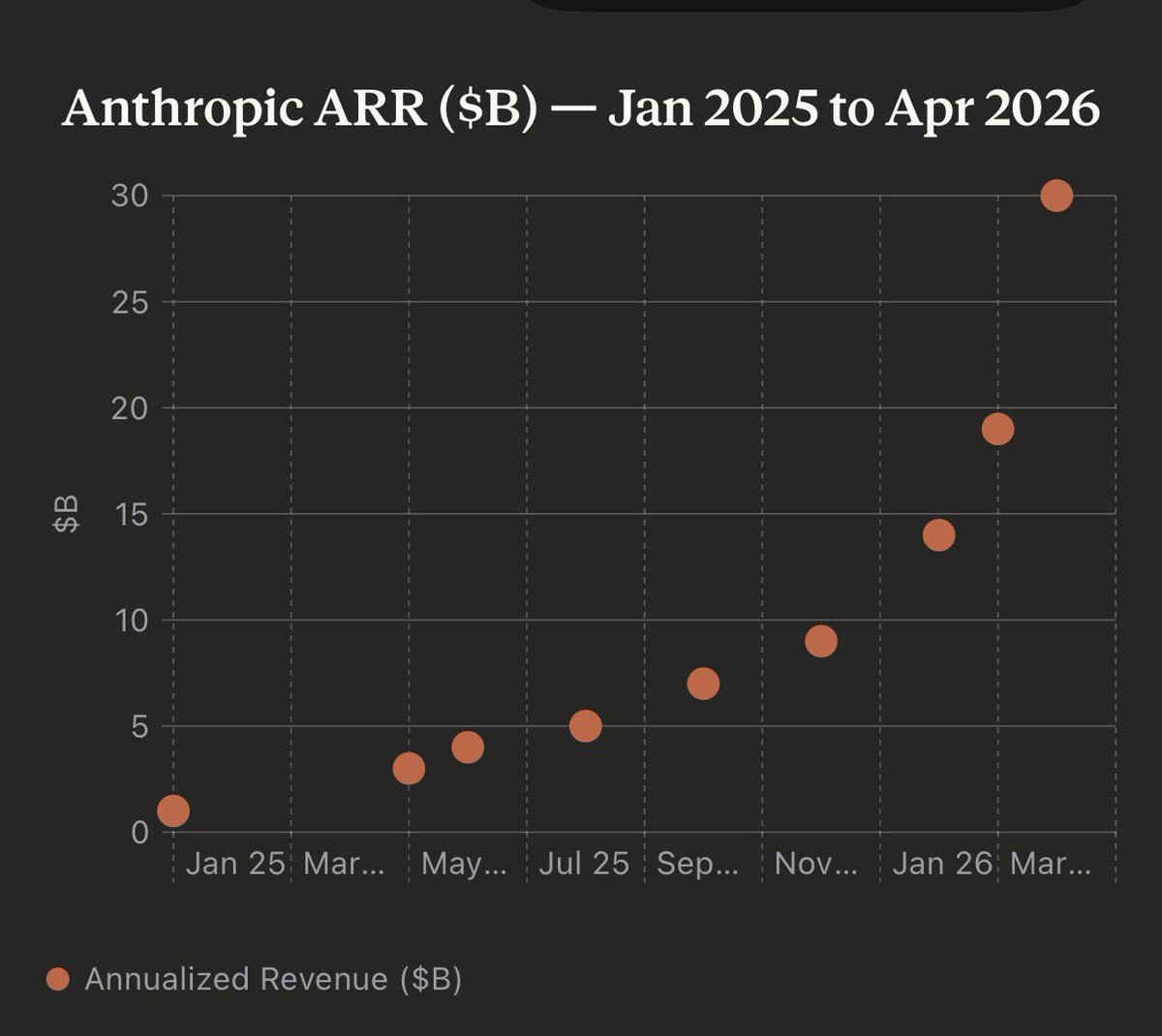
Spider benchmark says text-to-SQL is 86% accurate.
Spider 2.0, which uses real enterprise schemas, says 6%.
That is not a rounding error. That is the difference between a demo and production.
Most AI data tools are optimized for the demo.
English