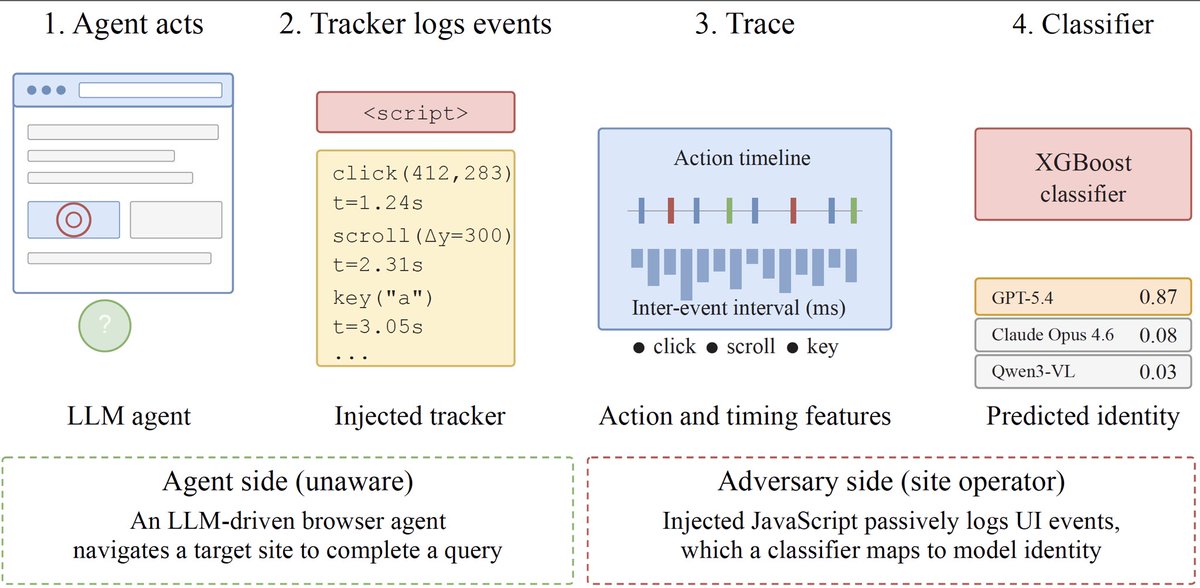
How do you benchmark something smarter than yourself? In light of the recent math benchmarks all getting dangerously close to saturation, we at @OxfordTVG are glad to announce Benchmarking Beyond Comprehension (written with @Microsoft). Coolest result: we successfully got GPT-3.5 to judge GPT-5.2-high on hard math topics. In the paper we study the Post-Comprehension Regime, i.e. the setting where coming up with hard enough questions and checking the correctness of the answers are infeasible (or very expensive). In theory, you can get around this by having the LLMs do this job, but then you get an infinite regression problem (how can you trust an LLM to check if an LLM-generated answer is correct?) The solution is an adversarial protocol: - Alice (e.g. GPT-5.2) comes up with a question-answer pair - Bob (e.g. DeepSeek) can either a) Accuse Alice’s question of being ill-posed b) Spot a mistake in Bob’s question c) Answer the question directly - Alice checks Bob’s answer and looks for mistakes - A human judge evaluates specific claims of mistakes The trick is that checking a specific claim of a specific mistake is much easier than coming up with a question or checking an entire answer. This means that humans can still do it even if they don’t understand the question as a whole. And since the game is adversarial, we can compute Elo scores! (Technically we use a bipartite Bradley-Terry model, but whatever) Two cool results: - The resulting Elos are strongly correlated with existing math benchmarks (i.e. the protocol is actually measuring math competence) - When we replace human judges (all of whom had a Master's or PhD in CS/Math) with weak models like GPT-3.5, the rankings do not meaningfully change, even when the models participating in the game are much stronger Basically, we show a pretty scalable form of weak-to-strong benchmarking. Which is cool! Paper here: arxiv.org/abs/2602.14307 Huge thanks to Jialin Yu, @iperboreo_ , @DebOishi, Jiawei Li, Yibo Yang, @EbeyAbraham, @sunandosengupta, Eric Sommerlade, @wooldridgemike, and Philip Torr for their help!