پن کیا گیا ٹویٹ
Onik Dev
95 posts

Onik Dev
@OnikDeveloper
Software Engineer, with a focus on innovating, not debating
Earth شامل ہوئے Kasım 2025
74 فالونگ3 فالوورز
@LottoLabs Can’t tell if you’re saying this is a good thing or a bad thing
English

Yup. Cannot wait for that to happen
x.com/onikdeveloper/…
𝗭𝗲𝗻 𝗠𝗮𝗴𝗻𝗲𝘁𝘀@ZenMagnets
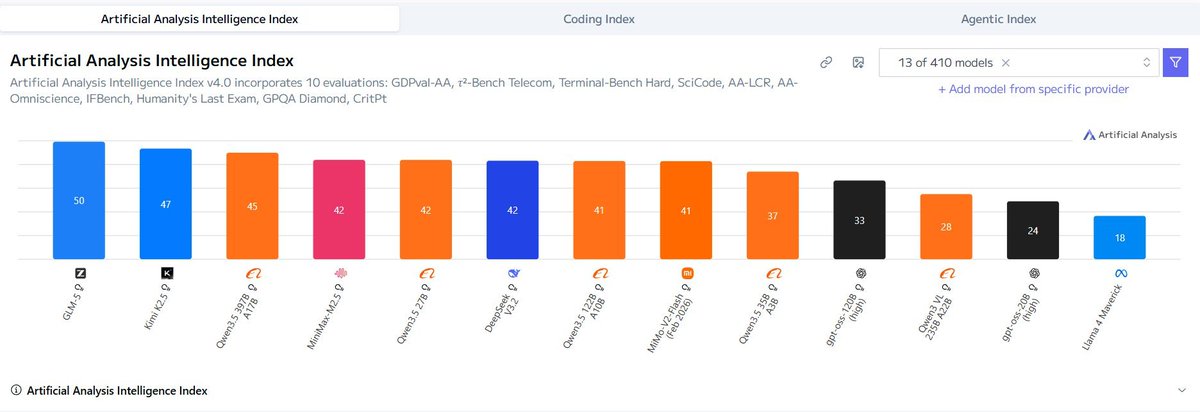
I change my mind. I would have bet against @TheAhmadOsman 's Jan'06 prediction that an Opus 4.5 tier model would run on a single RTX 6000 Pro by end of 2026. "Because ultimately the number of parameters matters, and there's no way to escape the physics of vram," I thought. But then Qwen3.5 27B dropped late Feb, which entirely broke the intelligence density barrier. 42 on AA, can run on 3090 with full context, albeit slowly, which now fights Minimax m2.5 which would have required $20k 2x RTX 6K Pros on Feb 12, and Deepseek v3.2 $80k 8x RTX6K in Dec 2025. Now I have little doubt that Minimax 3.3 or Qwen4 or Deepseek v4.5 or whatever will be at or very near Opus 4.5 by Dec 2026. But, also, it's hard to imagine how far ahead Opus 5.6/Gpt-6/etc will be by then. x.com/i/status/20122…
English
How on earth did this happen? I generally need to see the developer update on this. There’s no way this should be possible. Unless they’re doing some bad security segmentation practices
BBC Breaking News@BBCBreaking
Lloyds, Bank of Scotland and Halifax apps showing customers other users' transactions bbc.in/4sFipmm
English
You can’t be addicted to it.
You have to shift your mindset where you cannot negotiate yourself.
‘Just 5 more mins’
‘I can do that tomorrow’
Remove those negotiations and you’ll go far
Fav ⛧@Favwontmiss
I wanna get addicted to getting up early, hitting the gym, and eating healthy like y’all, what’s the secret?
English
In one year’s time. Top AI companies will probably be losing more money due to open source alternatives
Dan McAteer@daniel_mac8
The most capable LLM a year ago was one of: > o1 > Sonnet 3.7 > Gemini 2.5 Now, the most capable LLM is one of Opus 4.6, 5.3-Codex or Gemini 3.1. Imagine that in a year, the most capable LLM will be as improved vs. Opus 4.6 as Opus 4.6 is vs. Sonnet 3.7. Progress is rapid.
English
@BLUECOW009 But once these models catch up with closed source (which I think they pretty much are) the models will eventually be smaller where a normal GPU will suffice.
Plus once that happens, I estimate that pc parts prices will crash. That’s when you should definitely get one ;)
English

Running models locally is pretty useful but reality is that most people, even developers dont have much more than 1 gpu and ~32gb of ram. The best local models in the open need >90gb vram to run, that is not a realistic expectation for general usecase
English
Spoilers: LLMs will just get smaller, smarter and more cost efficient.
Power to the people. If everyone run their own LLMs in their homes, top AI companies will not dictate PC parts prices.
Don’t let them win!
Wildminder@wildmindai
RIP Monthly Fees. Really! Awesome combo Qwen3.5-35B + openclaw. Run it once, use it all day: $0 per prompt You don’t need huge/expensive models for your daily tasks: - Email +writing - Summaries - Non-stop coding - Agentic automation - Screenshots/images - Multilingual - No limits (except speed and electricity bill) Yeah, not super fast, but works well on 16GB VRAM + 64GB RAM.
English
@TheAhmadOsman Won’t be surprised that top AI companies will be made redundant. Can’t wait for the PC part price crash 😂
English

You guys have no idea how happy I am seeing
> Qwen3.5-27B going head-to-head with
> DeepSeek-V3.2 & MiniMax-M2.5
on the ArtificialAnalysis leaderboard
Deep down I believe in 2 things
- Small & specialized models
- Dense models, not MoEs
Plays a major role in why I prefer GPUs
Ahmad@TheAhmadOsman
i still believe in dense models
English
No more meetings. Discussions are legit down on PRs now. Well for my company anyways
Andreas Kling@awesomekling
I am anti hype, but pro stuff that works. Agentic coding clearly works. The big question (for me) now is how do we evolve collaborative software development processes to account for everyone having what’s essentially superpowers.
English
Yup. Slowly getting there. Big AI companies are gonna go bankrupt. Can’t wait for the hardware to be so cheap.
35B param being 235B?
Only a matter of time a 70B param will beat a 700B
Qwen@Alibaba_Qwen
🚀 Introducing the Qwen 3.5 Medium Model Series Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B ✨ More intelligence, less compute. • Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts. • Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios. • Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring: – 1M context length by default – Official built-in tools 🔗 Hugging Face: huggingface.co/collections/Qw… 🔗 ModelScope: modelscope.cn/collections/Qw… 🔗 Qwen3.5-Flash API: modelstudio.console.alibabacloud.com/ap-southeast-1… Try in Qwen Chat 👇 Flash: chat.qwen.ai/?models=qwen3.… 27B: chat.qwen.ai/?models=qwen3.… 35B-A3B: chat.qwen.ai/?models=qwen3.… 122B-A10B: chat.qwen.ai/?models=qwen3.… Would love to hear what you build with it.
English
Modern Robin Hood. Where’s the popcorn
Anthropic@AnthropicAI
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax. These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
English

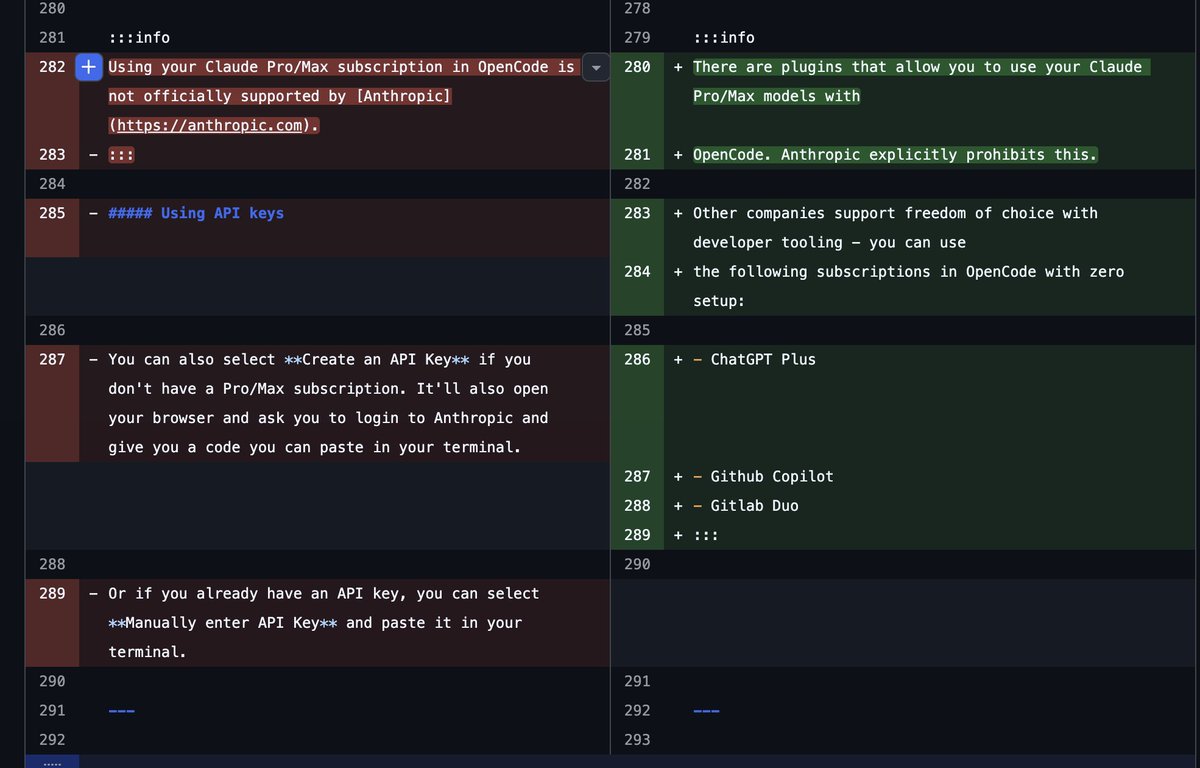
LOL opencode docs salty with Anthropic
Theo - t3.gg@theo
Seems like Anthropic lawyers sent some more love letters to OpenCode 🙃
English
Called it. Specialised small models for specialised purposes. In the future it won’t be one model that runs all. But small fast models with specialised. I know it’s similar to MoE but still
Hugging Models@HuggingModels
Meet Strand-Rust-Coder-14B, a specialized AI that writes Rust code like a senior developer. It's not just another coding assistant, it's specifically fine-tuned for Rust, making it a game-changer for systems programming and performance-critical applications. This is exactly what the Rust community has been waiting for.
English
Finally! A health advice I get 😂
Bryan Johnson@bryan_johnson
Nobody wants shitty code. When you don't sleep, you are shitty code.
English
@HaihaoShen @MiniMax_AI 32B params? What’s the performance hit compared to the original? Am I missing something?
English

🚩Minimax-M2.5 INT4 model is now available! Congrats @MiniMax_AI and the team!
huggingface.co/INC4AI/MiniMax… A nice gift for CNY 🎉
English