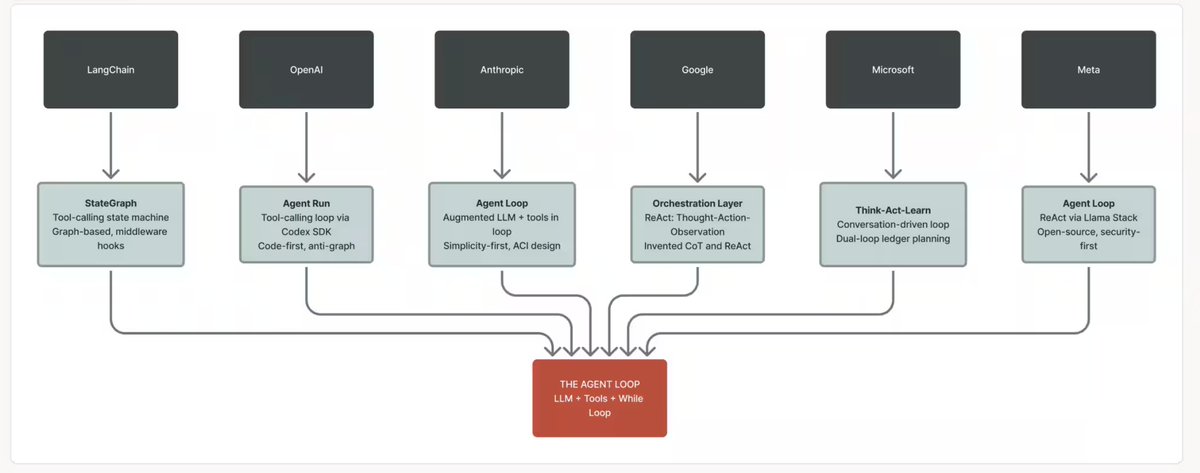
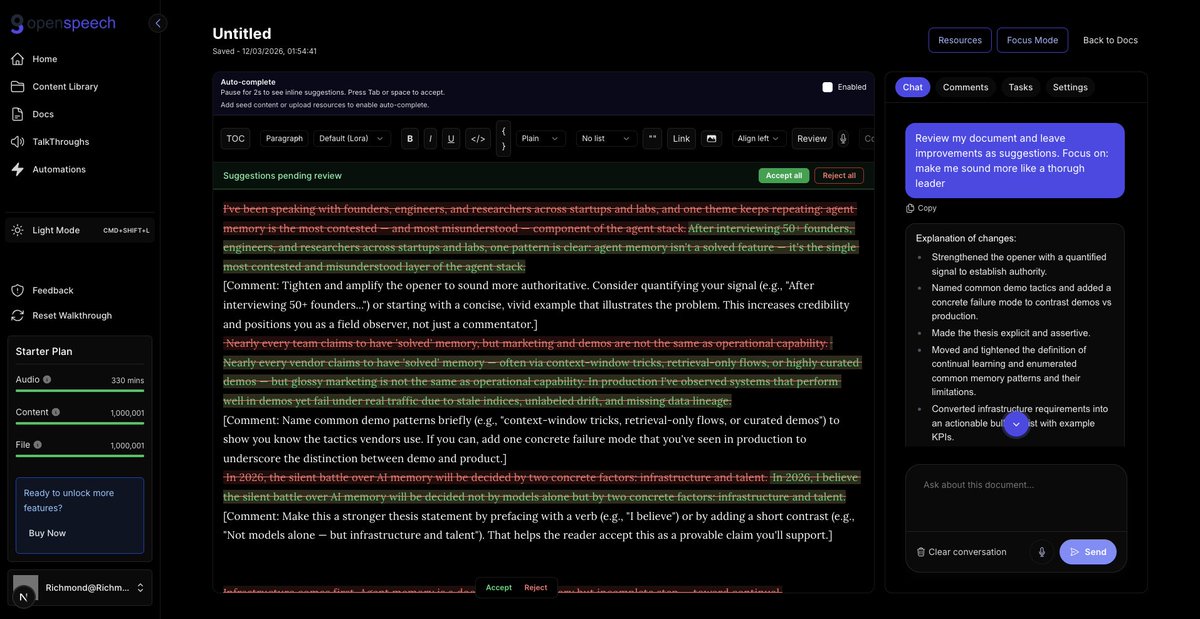
Richmond Alake ری ٹویٹ کیا

Oracle x @DeepLearningAI is live! 🥳
Most agents look impressive until they have to work across sessions, use the right data securely, and adapt to new information. That's where memory matters.
In this course, we show developers how to move from stateless agents to memory-aware agents using prompt, context, and memory engineering patterns—with practical implementation steps along the way.
Get hands-on here: social.ora.cl/6013B6nwWS
English