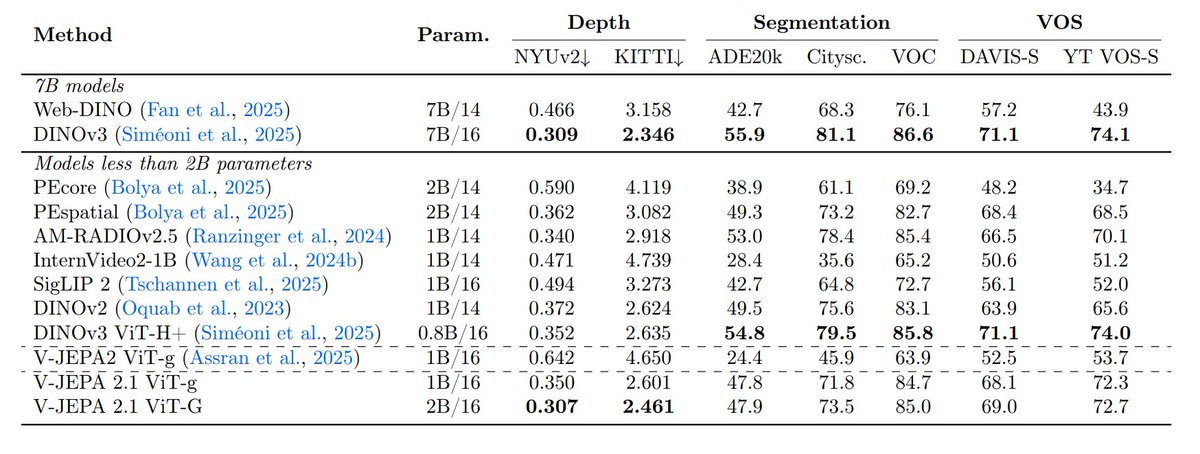
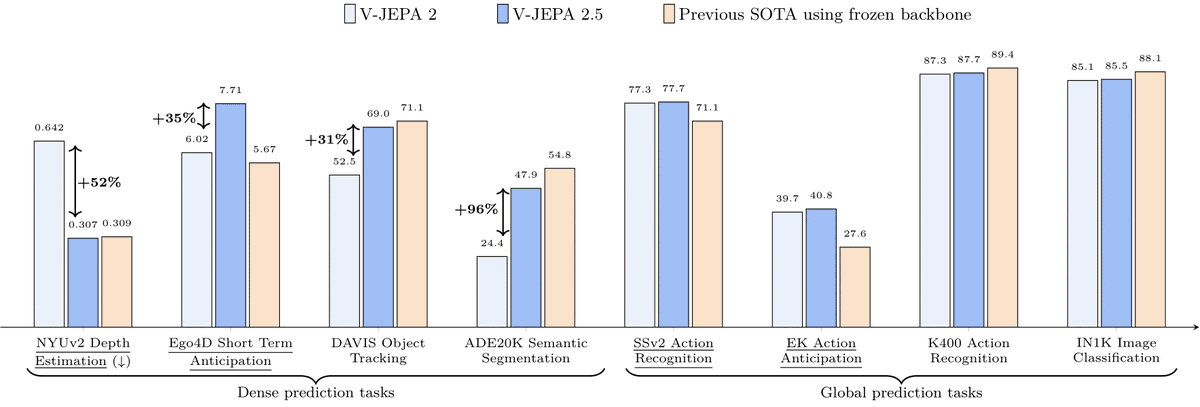
A new paper from @ylecun and others – V-JEPA 2.1
It changes the recipe of V-JEPA so the model learns both:
• Global semantics – what is happening in the scene
• Dense spatio-temporal structure – where things are and how they move
The idea is to supervise not just masked tokens but the visible ones too
There are 4 key ingredients for V-JEPA 2.1:
- Dense prediction loss on both masked and visible tokens
- Deep self-supervision across intermediate layers
- Modality-specific tokenizers (2D for images, 3D for videos) within a shared encoder
- Model + data scaling
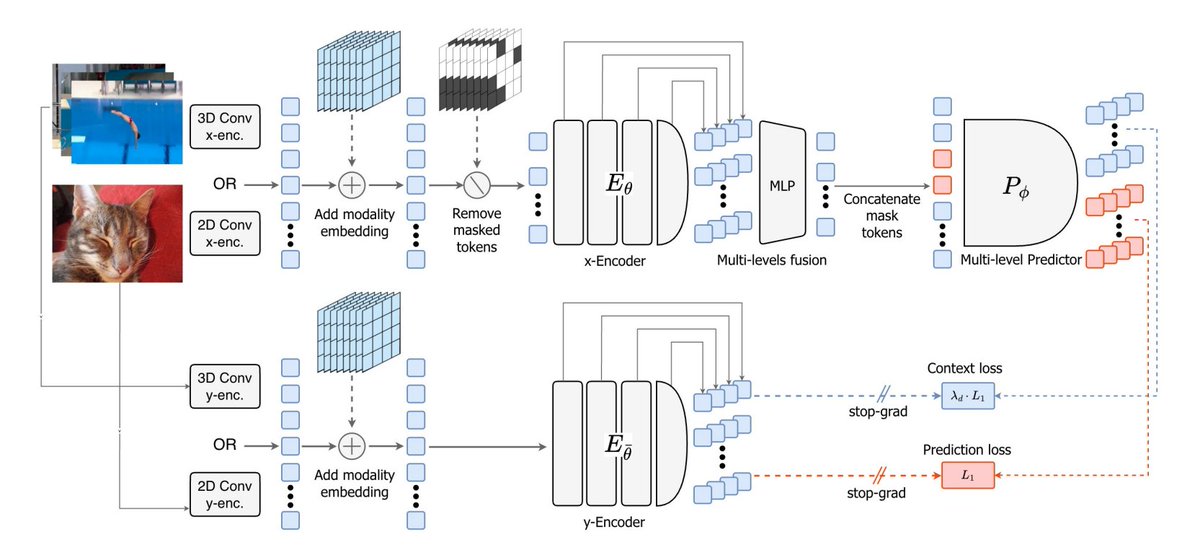
The workflow turns into: masked image/video → encode visible tokens → predict latent representations for both masked and visible tokens → supervise at multiple layers
Here are the details:
English