پن کیا گیا ٹویٹ
D C 🌱
4.1K posts


D C 🌱
@danielpcox
Aspiring Cheerful Rationalist, Googler. Opinions are my own. Retweet means "Interesting 🤔".
شامل ہوئے Mayıs 2009
354 فالونگ126 فالوورز
D C 🌱 ری ٹویٹ کیا

- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
English
D C 🌱 ری ٹویٹ کیا

D C 🌱 ری ٹویٹ کیا
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanoc…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

English
D C 🌱 ری ٹویٹ کیا

D C 🌱 ری ٹویٹ کیا

Software development is undergoing a renaissance in front of our eyes.
If you haven't used the tools recently, you likely are underestimating what you're missing. Since December, there's been a step function improvement in what tools like Codex can do. Some great engineers at OpenAI yesterday told me that their job has fundamentally changed since December. Prior to then, they could use Codex for unit tests; now it writes essentially all the code and does a great deal of their operations and debugging. Not everyone has yet made that leap, but it's usually because of factors besides the capability of the model.
Every company faces the same opportunity now, and navigating it well — just like with cloud computing or the Internet — requires careful thought. This post shares how OpenAI is currently approaching retooling our teams towards agentic software development. We're still learning and iterating, but here's how we're thinking about it right now:
As a first step, by March 31st, we're aiming that:
(1) For any technical task, the tool of first resort for humans is interacting with an agent rather than using an editor or terminal.
(2) The default way humans utilize agents is explicitly evaluated as safe, but also productive enough that most workflows do not need additional permissions.
In order to get there, here's what we recommended to the team a few weeks ago:
1. Take the time to try out the tools. The tools do sell themselves — many people have had amazing experiences with 5.2 in Codex, after having churned from codex web a few months ago. But many people are also so busy they haven't had a chance to try Codex yet or got stuck thinking "is there any way it could do X" rather than just trying.
- Designate an "agents captain" for your team — the primary person responsible for thinking about how agents can be brought into the teams' workflow.
- Share experiences or questions in a few designated internal channels
- Take a day for a company-wide Codex hackathon
2. Create skills and AGENTS[.md].
- Create and maintain an AGENTS[.md] for any project you work on; update the AGENTS[.md] whenever the agent does something wrong or struggles with a task.
- Write skills for anything that you get Codex to do, and commit it to the skills directory in a shared repository
3. Inventory and make accessible any internal tools.
- Maintain a list of tools that your team relies on, and make sure someone takes point on making it agent-accessible (such as via a CLI or MCP server).
4. Structure codebases to be agent-first. With the models changing so fast, this is still somewhat untrodden ground, and will require some exploration.
- Write tests which are quick to run, and create high-quality interfaces between components.
5. Say no to slop. Managing AI generated code at scale is an emerging problem, and will require new processes and conventions to keep code quality high
- Ensure that some human is accountable for any code that gets merged. As a code reviewer, maintain at least the same bar as you would for human-written code, and make sure the author understands what they're submitting.
6. Work on basic infra. There's a lot of room for everyone to build basic infrastructure, which can be guided by internal user feedback. The core tools are getting a lot better and more usable, but there's a lot of infrastructure that currently go around the tools, such as observability, tracking not just the committed code but the agent trajectories that led to them, and central management of the tools that agents are able to use.
Overall, adopting tools like Codex is not just a technical but also a deep cultural change, with a lot of downstream implications to figure out. We encourage every manager to drive this with their team, and to think through other action items — for example, per item 5 above, what else can prevent a lot of "functionally-correct but poorly-maintainable code" from creeping into codebases.
English
D C 🌱 ری ٹویٹ کیا

codex with 5.3 taught me something that won't leave my head.
i had it take notes on itself. just a scratch pad in my repo. every session it logs what it got wrong, what i corrected, what worked and what didn't. you can even plan the scratch pad document with codex itself. tell it "build a file where you track your mistakes and what i like." it writes its own learning framework.
then you just work.
session one is normal. session two it's checking its own notes. session three it's fixing things before i catch them. by session five it's a different tool. not better autocomplete. it's something else. it's updating what it knows from experience. from fucking up and writing it down.
baby continual learning in a markdown file on my laptop.
the pattern works for anything. writing. research. legal. medical reasoning. give any ai a scratch pad of its own errors and watch what happens when that context stacks over days and weeks. the compounding gains are just hard to convey here tbh.
right now coders are the only ones feeling this (mostly). everyone else is still on cold starts. but that window is closing.
we keep waiting for agi like it's going to be a press conference. some lab coat walks out and says "we did it." it's not going to be that. it's going to be this. tools that remember where they failed and come back sharper. over and over and over.
the ground is already moving. most people just haven't looked down yet.
English
@tillahoffmann I'm going to rename my vibe-coded fork to "applejax" for now so I can upload to PyPI and use in my projects.
English
@tillahoffmann I tried to confirm correctness by then having Opus 4.6 replicate papers and then generate stress tests. This found a few bugs, which are also now corrected in my fork. Please have a look at github.com/danielpcox/jax… and then let's discuss if you want to use any or all of this?
English
@tillahoffmann I pointed Opus 4.6 at jax-mps and had it solve all open Issues, and then keep going until it was as close to feature complete with jaxlib[cuda12] as it could get. I did this in my own fork so I wouldn't pollute your repo with AI slop, but it seems to have done well
English
D C 🌱 ری ٹویٹ کیا

@tszzl @memeticweaver @tautologer incredible to see people just casually reject the bedrock foundations of American greatness not just as some dumb nonsense that they're too cool to believe but as something they literally are not familiar with
English
D C 🌱 ری ٹویٹ کیا

There were a number of interesting things about doing this evaluation manually. As ever, nothing beats seeing data up close. Some observations in thread.
Epoch AI@EpochAIResearch
New record on FrontierMath Tier 4! GPT-5.2 Pro scored 31%, a substantial jump over the previous high score of 19%. Read on for details, including comments from mathematicians.
English
D C 🌱 ری ٹویٹ کیا

@ylecun @PrincetonNeuro @Princeton @theNASciences The fly's convolutional net is recurrent, dynamic, multi-scale, and likely mostly innate rather than learned. Now the challenge is to understand which of the net's properties are adaptive for vision, rather than accidents of evolution.
English
D C 🌱 ری ٹویٹ کیا
@ylecun @PrincetonNeuro @Princeton @theNASciences the connectome revealed the literal convolutional net inside the fly brain, including its architecture of 230 feature maps, normalizations, and other layers,

English
D C 🌱 ری ٹویٹ کیا

Triple inverted pendulum in transition control
A classic control problem, done in real time.
This setup moves smoothly between all eight equilibrium points of a triple inverted pendulum.
The system reacts every 1 millisecond, which shows how fast modern control loops can be.
• Real-time control at 1 ms sampling
• Stable transitions between multiple balance points
• Built with Simulink and LW-RCP02 hardware
This is a beautiful example of how theory meets practice in advanced control engineering.
Video: youtube.com/watch?v=Rh7JuL…
Credit: Embedded Control Lab, Inha University
—-
Weekly robotics and AI insights.
Subscribe free: scalingdeep.tech

YouTube
English
D C 🌱 ری ٹویٹ کیا

People don't understand the power of DEPRECIATION. You live in a world of sand castles that are constantly falling apart, and only the constant maintenance effort of billions of people keeps it from turning into a post-apocalyptic movie in a matter of months.
Anna Riedl@AnnaLeptikon
Somehow it was learning how many people are fulltime employed to maintain the Golden Gate Bridge that flipped something inside of me in my understanding of the entropic force civilization has to constantly fight against. Before that moment I thought — I had not applied real conscious thought — you simply build a building or anything really and then you just … have it. After that I understood everything is constantly at the brink of being lost.
English
D C 🌱 ری ٹویٹ کیا

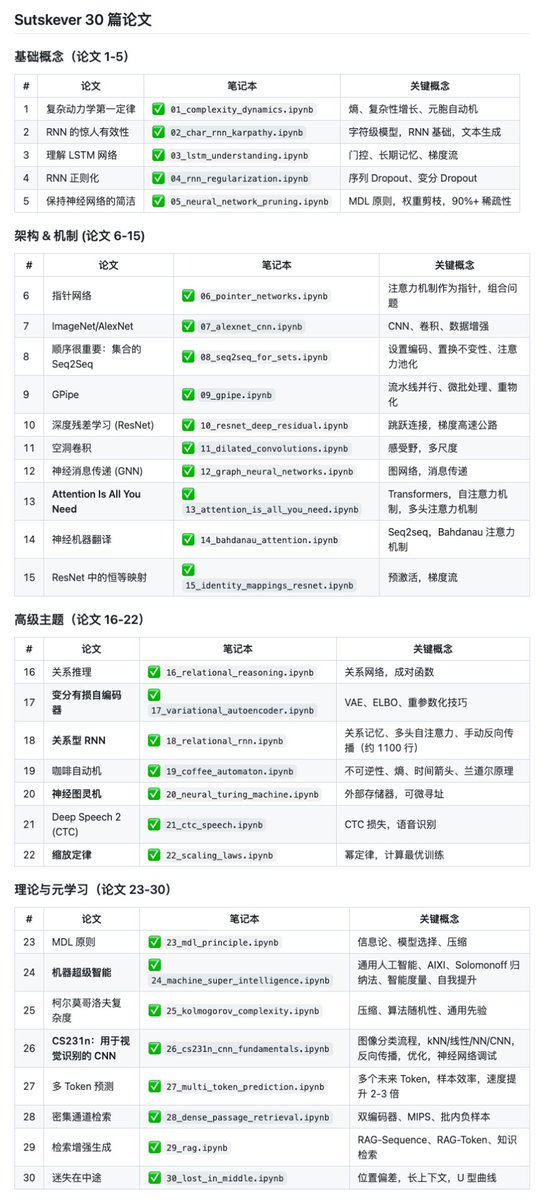
Ilya Sutskever 曾断言,只要读懂那 30 篇奠基论文,就能掌握人工智能 90% 的精髓。但面对枯燥的数学公式,大多数人很难将其转化为可运行的代码。
最近在 GitHub 上发现 Sutskever 30 这个开源项目,用纯 NumPy 实现了 Ilya Sutskever 推荐的 30 篇奠基性论文,全部完成。
每个实现都不依赖深度学习框架,只用 NumPy 从零构建,配合 Jupyter Notebook 交互式学习,还自带合成数据可以直接运行。
GitHub:github.com/pageman/sutske…
涵盖从 RNN、LSTM 到 Transformer、ResNet 的核心架构演进,包括注意力机制、残差连接、图神经网络等关键技术,还有 VAE、神经图灵机、CTC 损失等高级主题。
值得一提,项目还实现了 Kolmogorov 复杂度、MDL 原理、通用人工智能(AIXI)等理论基础,以及 RAG、长文本分析等现代应用。
如果你想从底层理解深度学习的核心机制,而不是只会调用框架 API,这个项目值得收藏学习。
中文
D C 🌱 ری ٹویٹ کیا

One very familiar pattern in AI and science right now is going from a lot of false starts on hard tasks (there have been near-misses where AI appears to solve an Erdos problem but actually just finds an old solution no one knew about) to actually doing the thing soon after.
Chubby♨️@kimmonismus
Terence Tao confirms: For the first time, an LLM (GPT-5.2 pro) has successfully solved an Erdos problem on its own. This makes me really excited for GPT-5.3 pro. Science is gaining momentum, and the breakthroughs are becoming more significant.
English