پن کیا گیا ٹویٹ

Dan Woods
214 posts
@danveloper
Vice President of AI Platforms for CVS Health. Former CTO for @JoeBiden.


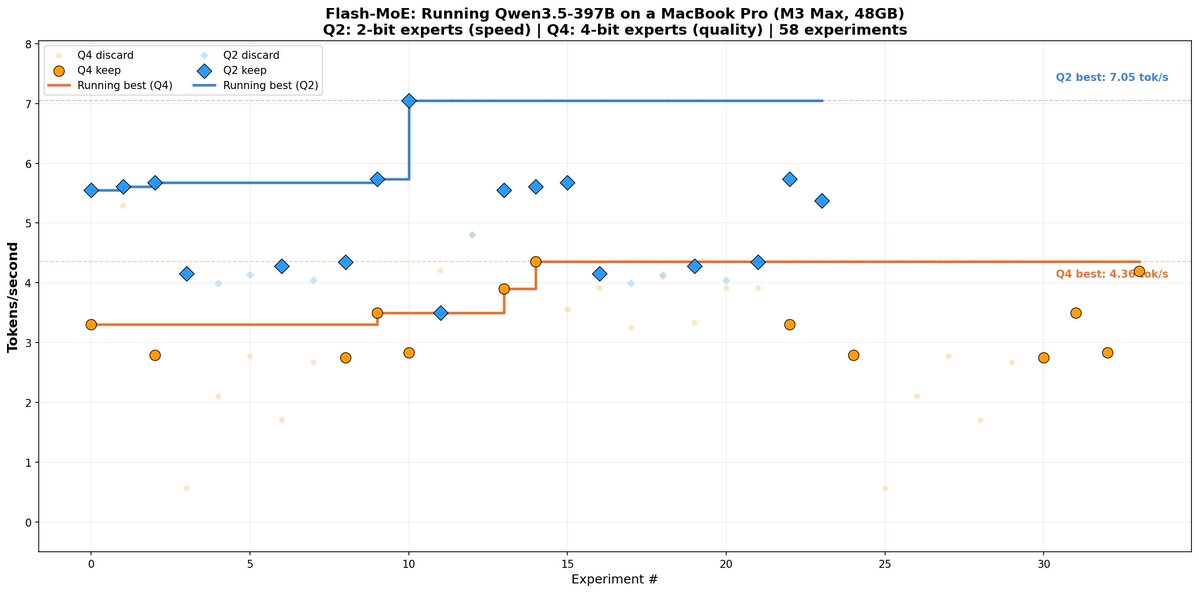
Get Excited: @0xSero and I are close — B300 is currently training on a tiny (15M param) side-loaded neural network that helps select, load, and cache the correct MoE experts for Kimi-K.2.5 (1T Param MoE model running on 25GB of memory). Once experiments are done -will share paper. "Thicket-Guided Expert Prediction for Memory-Minimal Trillion-Parameter MoE Inference on Unified Memory & Consumer Grade Hardware"





@pierrelezan Yes, @Ex0byt is working on this.