@yesitsarmin yes, the main limitation is the 2D detector here, but there are tons of better models (SAM3, VLMs) if you have the compute. for very cluttered scenes it doesn't work as well
English
Daniel DeTone
500 posts

@ddetone
Deep Nets and Geometry — what could go wrong?



Introducing ShapeR, a method for robust conditional 3D shape generation from casually captured sequences. ShapeR leverages a rectified flow transformer conditioned on per-object multimodal data to turn casual image sequences into full metric scene reconstructions. Project Page: facebookresearch.github.io/ShapeR Paper: arxiv.org/abs/2601.11514 Links to code and huggingface below ⬇️
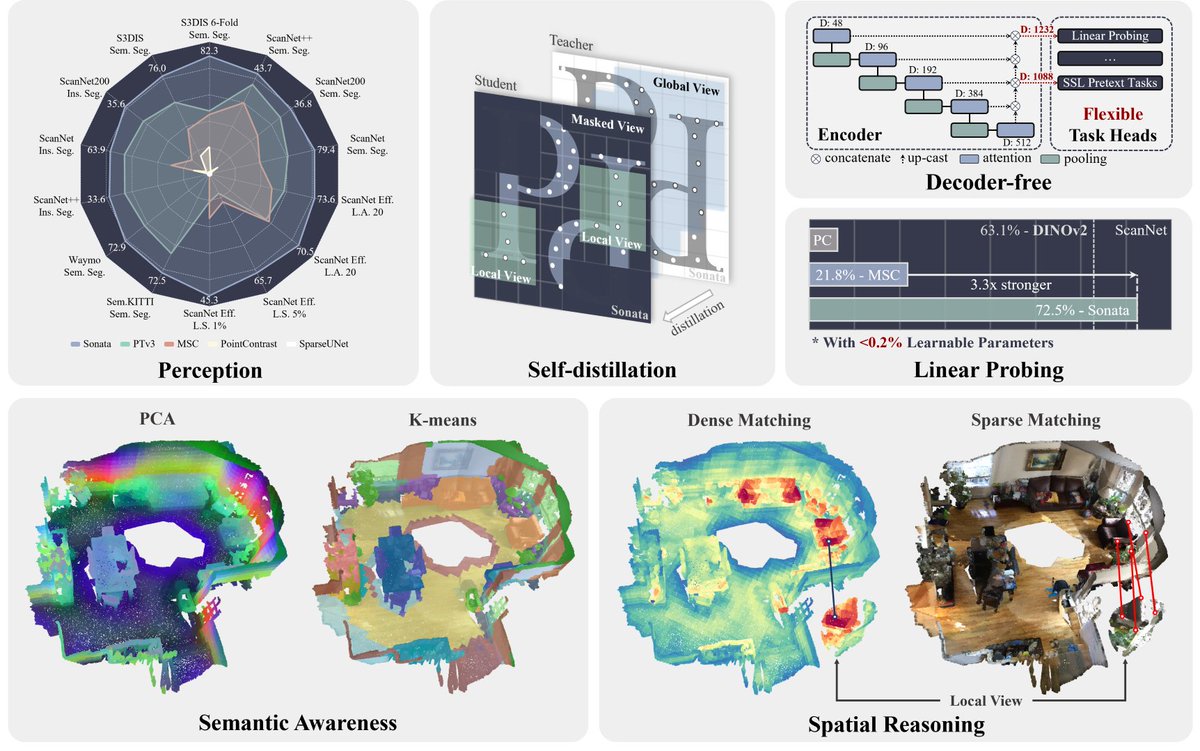
📢Sonata: Self-Supervised Learning of Reliable Point Representations📢 Meet Sonata, our"3D-DINO" pre-trained with Point Transformer V3, accepted at #CVPR2025! 🌍: xywu.me/sonata 📦: github.com/facebookresear… 🚀: github.com/Pointcept/Poin… 🔹Semantic-aware and spatial reasoning representations learned with no label; 🔹3x linear probing accuracy (from 21.8% to 72.5%) on ScanNet; 🔹2x data efficiency performance with only 1% of the data compared to previous approaches; 🔹As always, establish new SOTA results across indoor and outdoor 3D perception tasks. Our author team: @HengshuangZhao, @jstraub6, @rapideRobot, @ddetone, @NinjaDuncan, @TianweiS, @Christopher_Xie, @NanYang719.