پن کیا گیا ٹویٹ
𝕄𝕚𝕟𝕠𝕣𝕚🏍️
450 posts


𝕄𝕚𝕟𝕠𝕣𝕚🏍️
@helmetti
Executive Specialist (AI/ML) & Senior Director. MBA. @GoogleDevExpert. Raised in 🇲🇾 (Opinions are mine)
Japan شامل ہوئے Mayıs 2010
47 فالونگ1.8K فالوورز


@algo_diver Will you go to I/O Extended Shanghai, China (APAC event)? I met many GDEs from Korea
English

TLDR; 4 RTX6000 > 1 H100 for RTX LoRA
This is an interesting results. RTX 6000 is not a poormans GPU for fine tuning in some cases. (somebody give me GPU
chansung@algo_diver
RTX PRO 6000 for AI Research: When Is It Enough? I wrote a short blog post based on experiments conducted on @jarvislabsai platform. parkchansung.medium.com/rtx-pro-6000-f…
English





実際に企業と会話すると「日本語処理能力が高い」「地政学リスクがない」を要求されることが多い。文化面の強さは人文系の研究者から要望される一方でビジネス関係ではあまり話題にならない(それはそう)。
mamita@chemical_tree
国産LLMの意義として日本固有の知識を問う文化依存なタスクに強いというのはよく言われるわけだけど、実ビジネス/プロダクトでそれがクリティカルになるユースケースとかって実際どのくらいあるのだろうか(普通に知りたい)
日本語
ベクトルおじさんが見るに非構造化データの取り扱いがわかんないから手っ取り早くLLMに突っ込めばいいじゃん的なモノを強く感じますね。別にベクトル化のモチベーションは距離測る為だけではなく、コンテクスト周りや手法も進化してるしマルチモーダルで埋め込める今初手LLMはディープでポンと同じ香り
Kazunori Sato@kazunori_279
ベクトル検索の界隈をLLM以前から見ていると、起きてることはすごく単純。これまでの流れ:LLMすげえ→これからはベクトル検索だ!(根拠なし)→単純な類似検索やってみた→精度でねえ!面倒だからエージェントの推論任せでgrepしよう(←いまここ)。 俺が2年前に書いたような議論(単純な類似検索では検索品質低いし、IRのプロはみんな自前の推薦モデルを使う)は、RAG界隈では今だにほとんど見かけない。推薦モデル作る方法を今から学ぶより、"agentic"に済ませたほうが速いし結果がすぐ出るから。もちろんそれで済むデータ規模とレイテンシとコスト要件なら、最初からベクトル検索はいらない。 こういうLLM界隈の右往左往とは関係なく、大手各社は10年前も現在も何も惑わされずにベクトル検索でコンテンツ検索と推薦を数十億人規模に提供し、高い検索品質と大きな収益を上げている。 cloud.google.com/blog/products/…
日本語
𝕄𝕚𝕟𝕠𝕣𝕚🏍️ ری ٹویٹ کیا

ここで私が言う推薦モデルとは、構造化データのみを用いる伝統的な統計モデルではなく、two-towerモデルのようなクエリテキストと回答テキスト、クエリテキストとマルチモーダルコンテンツ等の非構造化データ間の埋め込みの関係性を学習するディープモデルを指します。さらに特徴量として構造化データや時系列データから作る埋め込みも合わせて使うケースが多いです。Xのタイムラインもそうやって作られますし、弊社や大手各社のサービスの検索や推薦もほとんどこれに似た仕組みです。
もちろん、ここにLLM推薦を組み合わせるととても強力です(レイテンシとコストの制約が許せば)。私もgenerative recommendationという呼び方で2年前くらいからそうした記事を書いてきました(Agenticってキーワードはまだバズってなかったので)。ただ、現在の多くのベクトル検索不要議論は、上述のような「ベクトル検索の基本」を飛ばしたまま安易に後者のバズに乗ろうとする流れが多く、プロフェッショナルな議論を見ることは少ないと思っています。
cloud.google.com/transform/infi…
日本語

次元がもったいないマンはあながち間違いでもなかった!
Kazunori Sato@kazunori_279
Grokファクトチェックした。そんな的外れではなさそう: 本投稿(@kazunori_279要するに、「LLMの高次元埋め込み空間をそのままグラフ(Knowledge Graph)に完全に移し替えて維持するのは現実的に難しい」という指摘です。 ファクトチェックのポイント「king - man + woman = queen」例→ 完全に事実。2013年のWord2Vec論文(Mikolov et al.)で示された有名なアナロジー計算です。以降、GloVeや現代のLLM埋め込みでも同様の幾何構造(高次元空間での意味的関係)が確認されています。投稿の例は正確です。 Google Knowledge Graph(KG)は「低次元な関係性」 → 正しい。Google KG(および一般的なKG)は、主に「entity1 — relation — entity2」という**三元組(triple)**で構成され、関係性が比較的低次元・シンボリックです。クエリが高速で正確なのはこの構造のおかげです。 LLMが捉える「高次元のセマンティクス」 → 正しい。現代の言語モデル(BERT以降)の埋め込みベクトルは通常512〜4096次元以上で、無数の幾何構造(アナロジー、類似度、ニュアンス)を保持しています。これを「漏らさず」グラフに射影するのは、情報損失の観点で極めて困難です。 「高次元グラフに射影して保守するのは大変」「次元削減し過ぎると昔のグラフDBと大差ない」 → 技術的に妥当な指摘。現在、GraphRAG(Microsoft)や知識グラフ+RAGのハイブリッド手法が海外で注目されていますが、多くの実装ではノードに高次元ベクトルをそのまま保持するか、ベクターDBと併用しています。 純粋にグラフDB(Neo4jなど)だけで高次元構造を「完全に」保守しようとすると、ストレージ・クエリコストが爆発的に増えたり、次元削減(PCAなど)せざるを得なくなります。結果として「昔のシンボリックKGに戻る」リスクは実際に議論されています。
日本語
BQMLのML.GENERATE_EMBEDDINGにムルタァィエンベディングスが生えておる!'multimodalembedding@001'とあるけどこれはGemini Embeddings2と違うの?どうなの?!最大512次元なので別のモデルの予感。埋め込みおじさんの未来は明るい
#multimodalembedding" target="_blank" rel="nofollow noopener">docs.cloud.google.com/bigquery/docs/…
日本語

すげー!!!今デスクに置いてあったコカ・コーラゼロを映しながらこれなに?って聞いたら「これはコカ・コーラゼロでラベルから日本の物と思われますね!」やって! Live APIと組み合わせるのがセンスありすぎて鼻血ちょっと出た
Kazunori Sato@kazunori_279
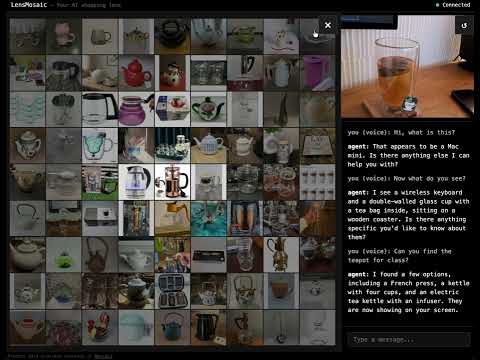
Gemini Embedding 2とVector Search 2とADK Gemini Live API Toolkitで100万件の商品からリアルタイム&マルチモーダル検索できるライブデモ作った。モデルが世界をどう見てるか覗く万華鏡のようなUX。誰でも試せます:LensMosaic - a live multimodal shopping demo youtu.be/SgMn-6q8Qg8?si…
日本語
𝕄𝕚𝕟𝕠𝕣𝕚🏍️ ری ٹویٹ کیا
Gemini Embedding 2とVector Search 2とADK Gemini Live API Toolkitで100万件の商品からリアルタイム&マルチモーダル検索できるライブデモ作った。モデルが世界をどう見てるか覗く万華鏡のようなUX。誰でも試せます:LensMosaic - a live multimodal shopping demo youtu.be/SgMn-6q8Qg8?si…
YouTube
日本語