MiniMax M2.7 is now available in LM Studio.
This model excels at agentic tool calling 🛠️
Requires at least ~138GB to run locally
lmstudio.ai/models/minimax…
Meta just open-sources a tool that animates complete 3d characters in pure python.
no heavy game engines. no hassle. just pytorch, numpy, and pure ai motion.
We’re expanding Trusted Access for Cyber with additional tiers for authenticated cybersecurity defenders.
Customers in the highest tiers can request access to GPT-5.4-Cyber, a version of GPT-5.4 fine-tuned for cybersecurity use cases, enabling more advanced defensive workflows.
openai.com/index/scaling-…
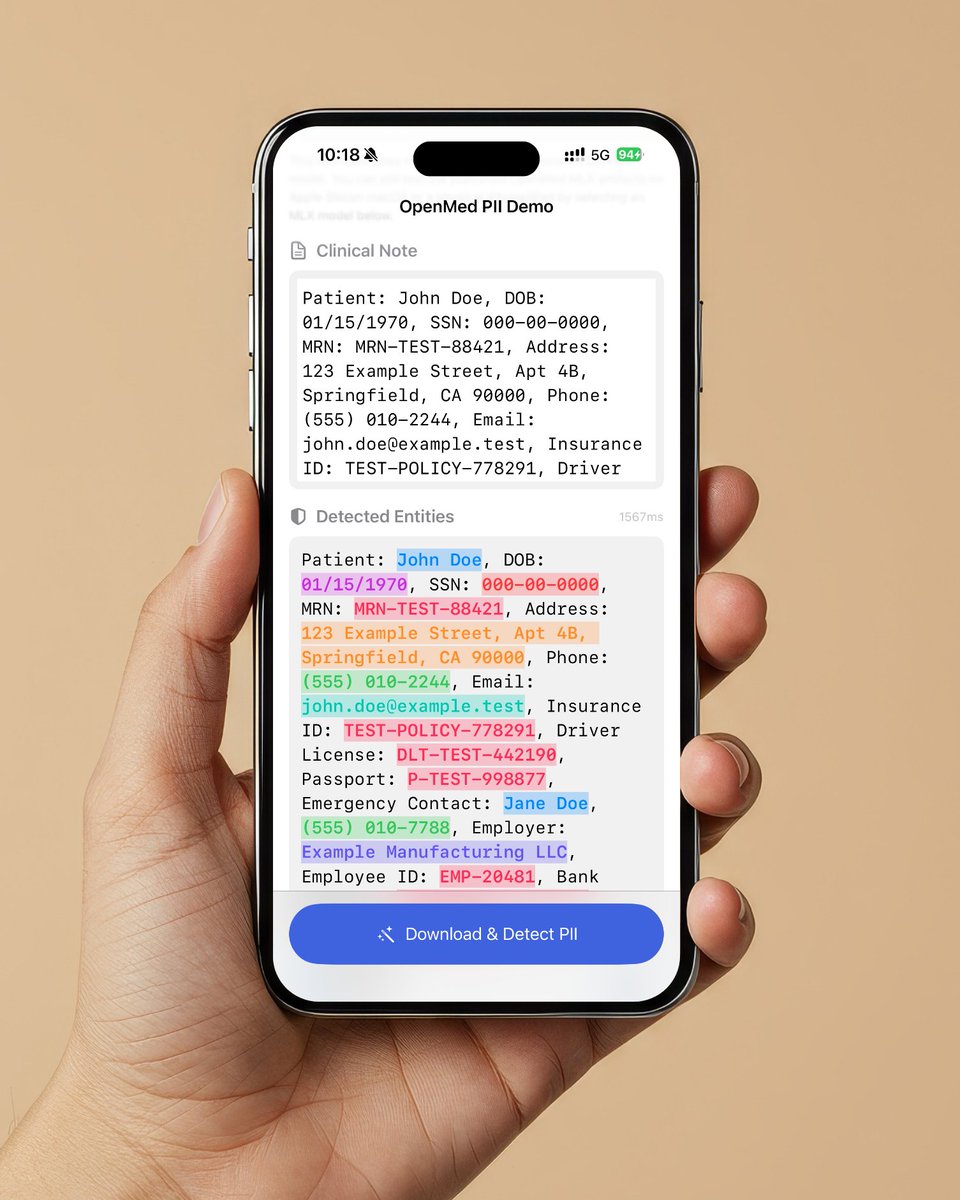
Medical AI models now run on iPhone. No cloud. No API.
OpenMed 1.0.0 just shipped.
MLX backend for Apple Silicon. Swift package for macOS and iOS. 200+ PII detection models across 8 languages.
pip install openmed
Open source. Apache 2.0.
RAG is broken and nobody's talking about it.
Stanford researchers exposed the fatal flaw killing every "AI that reads your docs" product in existence.
It’s called "Semantic Collapse," and it happens the second your knowledge base hits critical mass. If you've noticed your AI getting "dumber" as you add more data, this is exactly why.
Right now, companies are dumping thousands of documents into their AI, thinking it’s getting smarter.
When you add a document to RAG, it converts it into a high-dimensional vector.
Under 10,000 documents, this works perfectly. Similar concepts cluster together.
But past 10,000 documents, the space fills up. The clusters overlap. The distances compress.
Everything starts to look "relevant."
It is a mathematical law called the Curse of Dimensionality. In a 1000-dimensional space, 99.9% of your data lives on the outer edge. All points become equidistant from each other.
That perfect, relevant document you are looking for now has the exact same mathematical similarity as 50 completely irrelevant ones.
The Stanford findings are brutal:
At 50,000 documents, precision drops by 87%. Semantic search actually becomes worse than old-school keyword search.
Adding more context doesn’t fix the AI. It makes the hallucinations worse.
Your "nearest neighbor" search isn't finding the best answer anymore. It's finding everyone.
We thought RAG solved hallucinations.
It didn't. It just hid them behind math.
gemma4 26b is very possibly a serious threat to the "college student with a 16gb macbook using the rate-limited mini version of chatgpt" demographic that openai currently has in droves. just depends entirely on word of mouth viral marketing
same ~83ish GPQA as 5 mini, no ads...
Genie3 generates videos. We generate 𝟯𝗗 𝘄𝗼𝗿𝗹𝗱𝘀 you can actually use.
Launching tomorrow — Tencent #HYWorld 2.0, an engine-ready World Model🚀
This isn't a video. It's a real 3D scene, all generated & editable. One image in. A whole 3D world out.
🔥Open-source tomorrow
Talk to your @openclaw over a “hacked” Google Home mini! 🦞
I finally updated this project w/ a configurable pipeline you can run entirely locally
Code & getting started in🧵
A 35B model that doesn't fit in RAM running at 30 tok/s on a $600 Mac mini.
On NVIDIA, paging a model from NVMe gives 1.6 tok/s. on Apple Silicon: 30 tok/s. 18.6x faster.
That's the core finding behind mac-code -- an open source AI coding agent that runs entirely on your Mac for $0/month.
It's not a chat UI wrapper. it's an actual agent with web search, shell commands, file operations, and code generation, built on two backends:
→ llama.cpp -- 35B MoE via SSD flash-paging, 30 tok/s, works on 16GB RAM
→ MLX -- 25% faster generation, persistent KV cache that saves to disk and syncs across Macs via Cloudflare R2
Here's what the persistence benchmarks look like:
Reprocessing 141 tokens: 1.01 seconds
loading the same context from SSD: 0.0003 seconds
That's 6,677x faster. analyze a codebase once, resume instantly tomorrow.
Two more findings worth noting:
Quantized KV cache (`--cache-type-k q4_0 --cache-type-v q4_0`) doubles context window for free -- the 9B goes from 32K to 64K with zero quality loss and shrinks memory from 1024 MB to 288 MB.
TurboQuant compresses saved context 4x (26.6 MB → 6.7 MB) with 0.993 cosine similarity. almost no information loss.
Routing works too. the LLM classifies its own intent ("search" / "shell" / "chat") at the text level -- which means the 35B at extreme 2.6-bit quantization that breaks JSON function calling still routes correctly. 8/8 in testing.
`bash setup.sh`
100% open source. MIT license.
(link in the comments)
🦞👾 LM Studio is now an official @openclaw provider!
Run:
openclaw onboard --auth-choice lmstudio
Use your local models with your OpenClaw - it's private and free.
Works on Mac, Windows, and Linux.
Let's Claw 🦞🦀
🔥 The hidden tax on multi-agent AI: cache eviction is burning your budget 🔥
Three rules for multi-agent systems:
1.🚫 Never launch sub-agents from a large context. Cache eviction cost dwarfs the agent work itself. Use external scripts.
2.📋 The parent model dispatches, it doesn't relay. It says "go" and reads results. Never passes content, never waits, never gets interrupted.
3.🛡️ Protect your cache like your budget depends on it. Because it does. Every interruption = full-price context reload. Batch work externally.
We learned these the hard way. Burned 50% of a session budget on work that should have cost 10%. The agents weren't the problem. The parent model reloading its own memory 10 times was. 💸
Here's the story. 🧵
We're building v84 — a system where 30 specialized AI agents work in parallel to plan features. Each agent owns one topic, writes entries, an architect reviews everything. The flow works. The output is good. The bill is not.
We launched 30 sub-agents from an Opus conversation with ~500k tokens of context. Each agent was a small, focused task — maybe 15k tokens of work. Should be cheap, right?
How prompt caching works (and breaks) ⚡
When you talk to a large model, your conversation context gets cached. Each subsequent message costs almost nothing — the model only processes new tokens. The cached history is basically free.
You → Opus (500k context)
Turn 1: 500k input (first load — expensive)
Turn 2: 500k cached + 100 new tokens (pennies 💰)
Turn 3: 500k cached + 200 new tokens (pennies 💰)
Beautiful. Until you launch a sub-agent.
You → Opus (500k cached — cheap 💰)
Launch agent 1 → Opus cache EVICTED 💀
Agent 1 finishes → back to Opus
Opus reloads 500k context → FULL PRICE 💸
Launch agent 2 → cache EVICTED 💀
Agent 2 finishes → Opus reloads 500k → FULL PRICE 💸
× 30 agents = 💀💸💀💸💀💸
Every sub-agent launch kills the parent's cache. When control returns, the entire conversation re-processes at full price. With 500k tokens of context and 30 agents, that's 15M tokens just re-reading the same conversation over and over. The actual agent work? 450k tokens total.
We were paying for amnesia, not intelligence. 🧠❌
Each individual agent was cheap. Haiku processing 15k tokens is almost free. But Opus reloading and re-reading its own 500k conversation history 30 times — that's where the budget went. Not on thinking. On remembering.
The fix 🔧
Don't launch sub-agents from inside the expensive model's conversation. Use an external script.
BEFORE (cache thrashing 💀):
Opus → launch agent → cache evicted → reload 500k
→ launch agent → cache evicted → reload 500k
× 30 = 15M tokens of re-reads
AFTER (cache preserved ✅):
Opus says "run the agents" → bash script takes over
Script launches 30 API calls in parallel
Opus cache stays warm the entire time ☀️
Script finishes → Opus reads one summary
ONE reload, not 30
We built a bash script that reads pre-bundled context files, calls any LLM API (Anthropic, OpenAI, Ollama, local models), and writes results to disk. The parent model is never interrupted. Its cache stays warm.
Total cost of 30 agents via script: 30 × 15k tokens at Haiku pricesTotal cost of 30 agents via sub-agent tool: 30 × 15k Haiku + 30 × 500k Opus reloads
Same output. ~30x cheaper. 🤯
What this means for your multi-agent setup:
If you're building anything that spawns agents from a conversation — coding assistants that delegate, planners that fan out to specialists, review pipelines with multiple passes — check if your parent model's context is being evicted between each spawn.
The models are smart enough. The APIs are fast enough. The hidden cost is the architecture between them. 🏗️
This isn't in any pricing calculator. No documentation warns you. You discover it when half your budget disappears on a Tuesday afternoon.
Follow along with V84 for more lessons we paid real money to learn.
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:huggingface.co/MiniMaxAI/Mini…
Blog: minimax.io/news/minimax-m…
MiniMax API: platform.minimax.io
@learntouseai payment follow-ups is the one that actually matters. everything else is nice but chasing late invoices is the part that makes people quit freelancing
We’re taking Gemma 4 on a world tour with 50+ events across the globe! From hackathons to deep dives, come build with the latest open weights in a city near you 🌎
Where we’ll be next: San Francisco, São Paulo, Kolkata, Las Vegas, Seoul, online, and more!
Claude for Word is now in beta.
Draft, edit, and revise documents directly from the sidebar. Claude preserves your formatting, and edits appear as tracked changes.
Available on Team and Enterprise plans.
Gemma 4 looks at a parking lot. Decides what to ask. Calls SAM 3.1.
"Segment all vehicles." 64 found.
"Now just the white ones." 23 found.
One model reasoning and orchestrating. One model executing.
Both running locally on a MacBook. MLX. No cloud. No API.
We're releasing HY-Embodied-0.5, a family of foundation models for real-world embodied agents. The 2B model is now open source.
It strengthens spatial-temporal perception and embodied reasoning for prediction, interaction, and planning. 🤖
The suite includes:
🔹 2B for edge deployment
🔹 32B for complex reasoning
Key innovations:
🔹 Mixture-of-Transformers (MoT) architecture for modality-specific computation
🔹 Latent tokens for improved perceptual representation
🔹 Self-evolving post-training
🔹 On-policy distillation from large to small models
Across 22 benchmarks, the 2B model outperforms similarly sized SOTA systems on 16 tasks. The 32B model approaches frontier-level performance.
🔗 GitHub: github.com/Tencent-Hunyua…
🤗 Hugging Face: huggingface.co/tencent/HY-Emb…
🚀 Qwen Code v0.14.0 – v0.14.2 are now available
Channels:Control Qwen Code remotely from Telegram, DingTalk, or WeChat — send a message from your phone, get results on your server
Cron Jobs :Schedule recurring AI tasks — auto-run tests every 30 min, pull & build every morning, monitor logs on a timer
Qwen3.6-Plus :New flagship model with 1M token context, 1,000 free daily requests
Sub-agent Model Selection:Assign different models to sub-agents — use a powerful model for the main task, a fast one for subtasks, save tokens without sacrificing quality
/plan:Enter planning mode before execution — AI maps out all files and steps first, you confirm, then it executes
Follow-up Suggestions:AI suggests 2-3 next steps after completing a task — "Add unit tests?" "Check similar files?" — click to continue
Adaptive Output Tokens :Default 8K output, auto-escalates to 64K when truncated — no more manually tuning max_tokens
Ctrl+O Verbosity Toggle :Switch between verbose and compact output mid-conversation — debug mode when you need it, clean mode when you don't
📋 Full changelog: github.com/QwenLM/qwen-co…