پن کیا گیا ٹویٹ

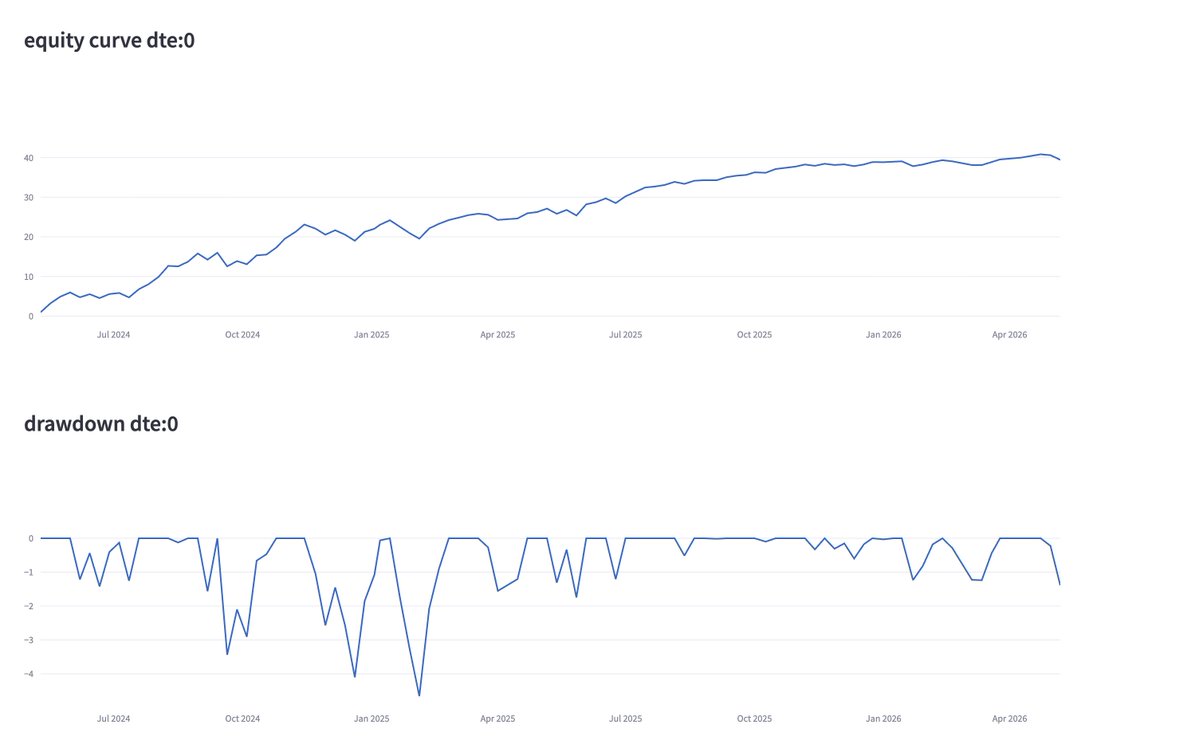
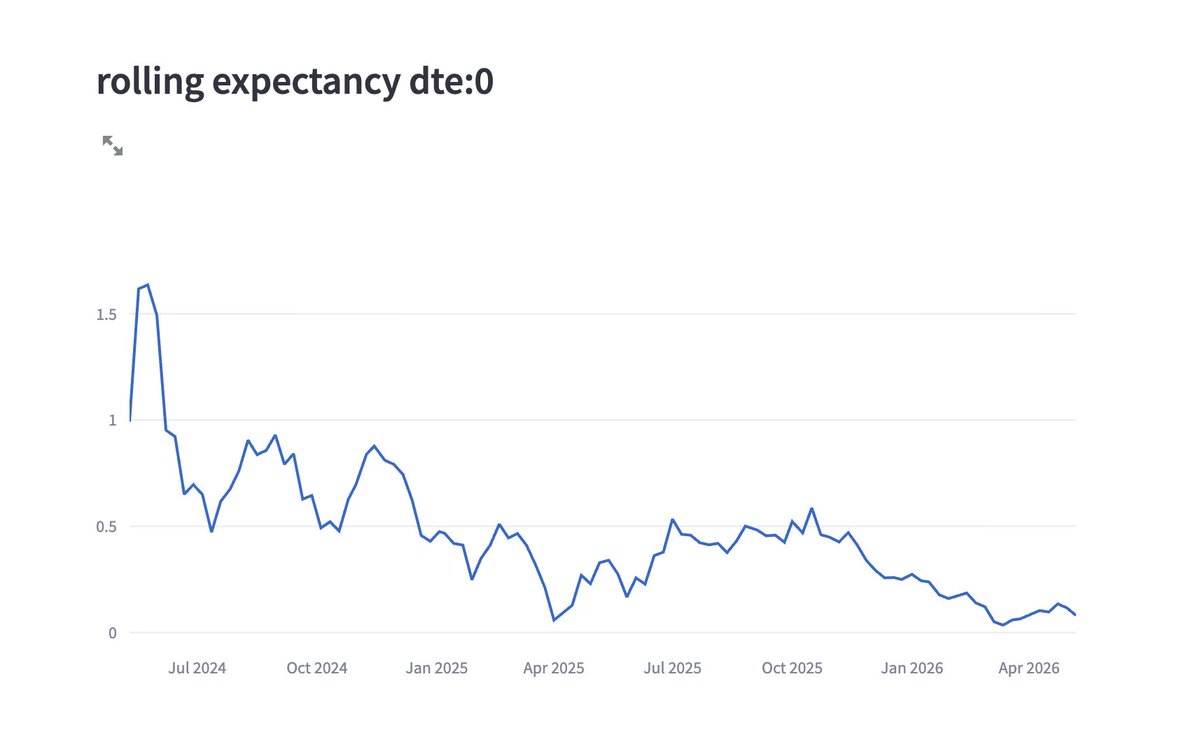
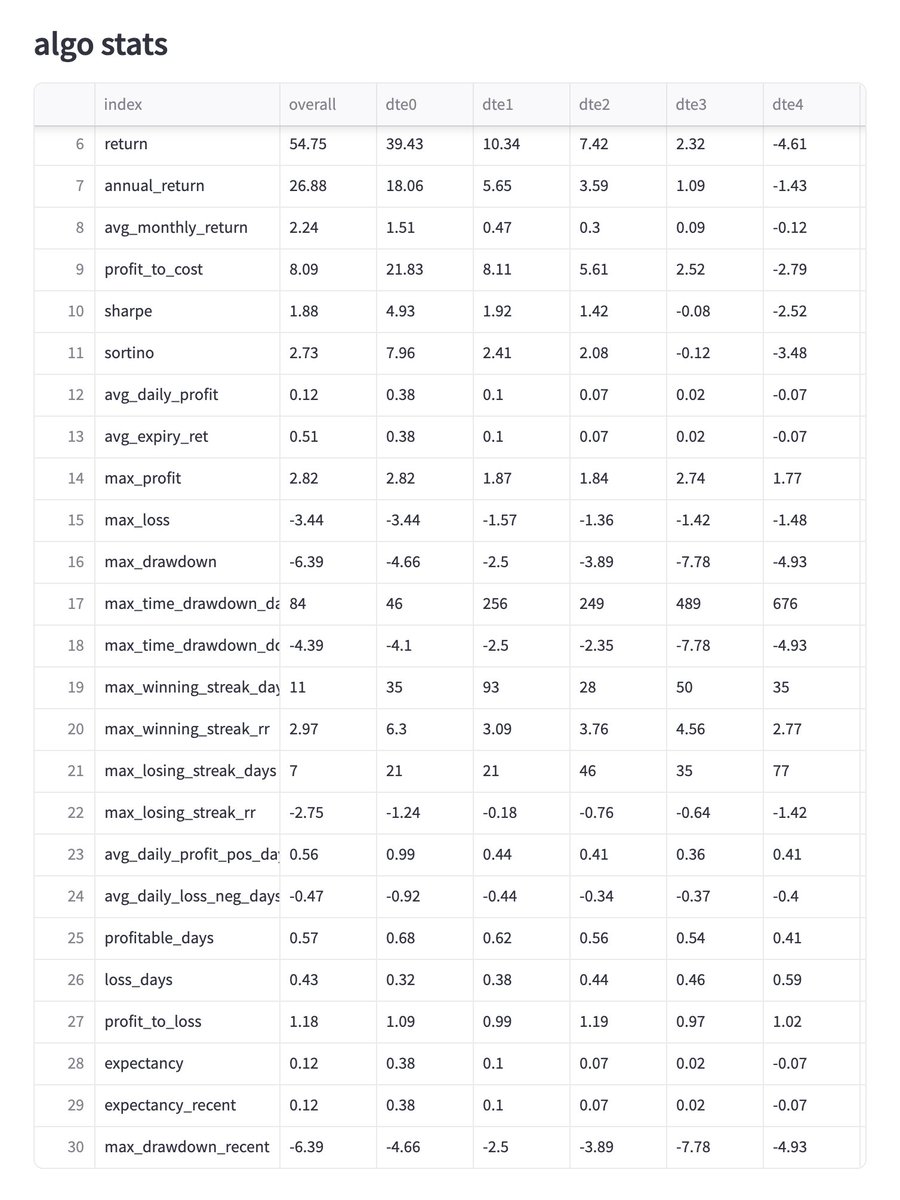
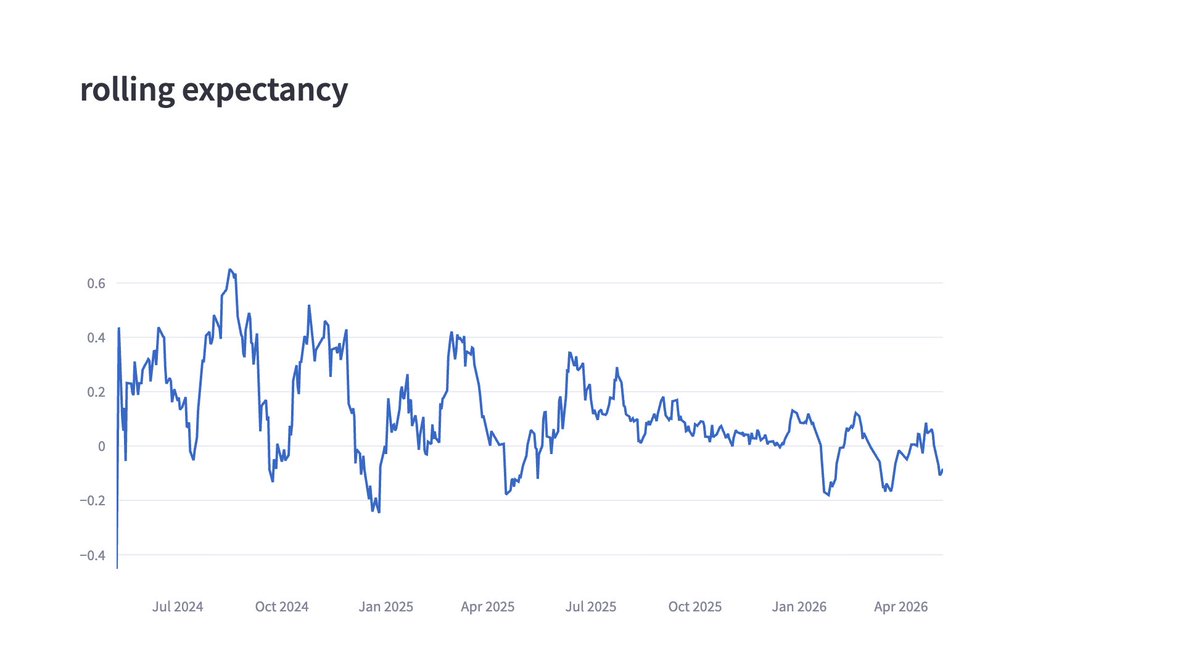
+13L (1.05%)
nice trending day
Also tune in here youtube.com/watch?v=AsPXLy…
I am live with Nitish Shukla @ICICI_Direct
an informal conversation about #algotrading

YouTube

English
Ripu Singla
2K posts

@ripusingla
Over a decade in Machine Learning and large scale cloud infrastructure, IIT Kanpur, Full time Algo Trader, Founder Niuhi Quantitative Research, NISM-8 Certified

Last few weeks I have been focusing on finding systematic traders who are using algo and ai to trade peacefully. Expect more amazing #face2face in this subject like this one with @ripusingla Not for entertainment seekers. Only serious traders pls. youtu.be/TyYH595IMxE

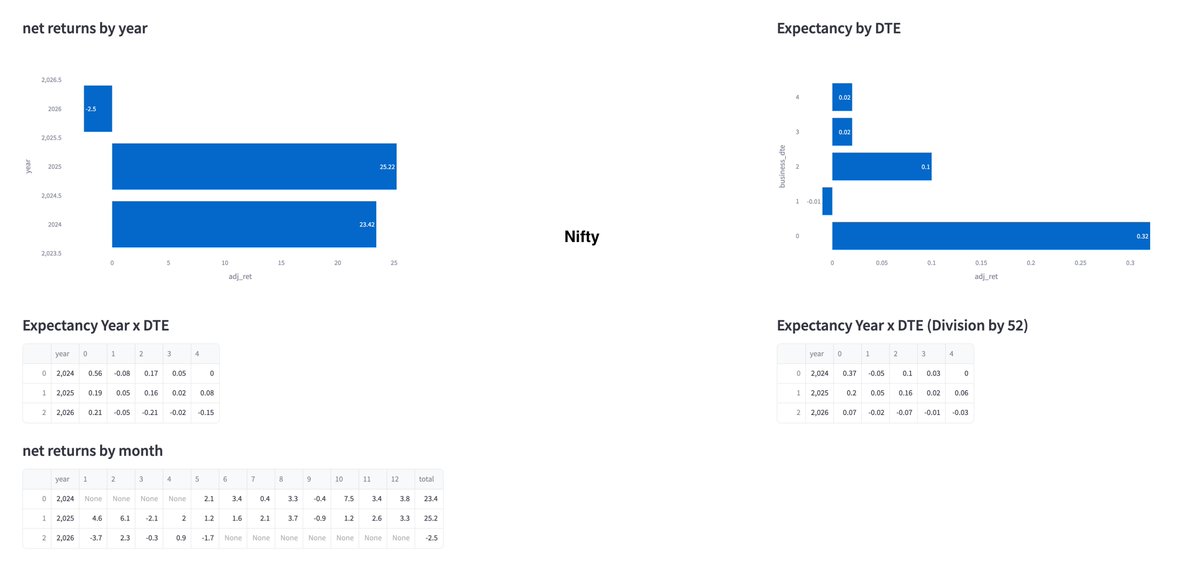

Is pure delta neutral trading currently a negative EV system? Can anyone simulate if delta hedged short gamma trades are net negative for the year? "Finding any edge, be it positive or negative, is quite difficult" If you can get a negative edge, you can simply invert it.


thanks to AI, my 7 year old is building video game for himself. his prompts are the true capability test for AI :P


I've been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX). The status quo of prompt compaction coupled with recursive sub-agents is actually remarkably effective. Seems like we can go pretty far with this. (Prompt compaction = when the context window gets close to full, model generates a shorter summary, then start from scratch using the summary. Recursive sub-agents = decompose tasks into smaller tasks to deal with finite context windows) Recursive sub-agents will probably always be useful. But prompt compaction seems like a bit of an inefficient (though highly effective) hack. The are two other alternatives I know of 1. online fine-tuning and 2. memory based techniques. Online fine-tuning: train some LoRA adapters on data the model encounters during deployment. I'm less bullish on this in general. Aside from the engineering challenges of deploying custom models / adapters for each use case / user there are a some fundamental issues: - Online fine-tuning is inherently unstable. If you train on data in the target domain you can catastrophically destroy capabilities that you don't target. One way around this is to keep a mixed dataset with the new and the old. But this gets pretty complicated pretty quickly. - What does the data even look like for online fine tuning? Do you generate Q/A pairs based on the target domain to train the model? You also have the problem prioritizing information in the data mixture given finite capacity. Memory based techniques: basically a policy for keeping useful memory around and discarding what is not needed. This feels much more like how humans retain information: "use it or lose it". You only need a few things for this to work: - An eviction/retention policy. Something like "keep a memory if it has been accessed at least once in the last 10k tokens". - The policy needs to be efficiently computable - A place for the model to store and access long-term memory. Maybe a sparsely accessed KV cache would be sufficient. But for efficient access to a large memory a hierarchical data structure might be beter.
Introducing mt QUANT by mastertrust Tick-by-Tick Backtesting Starts Now! 🔍 Backtest with precision ⚙️ Master complex logic 📊 Run multiple tests with 100% strategy security Whether you're a beginner or a pro, mtQUANT gives you the edge to test smarter and trade better. 📥 Download now - …st-strapi.s3.ap-south-1.amazonaws.com/mt_Quant_Setup… Learn more: youtube.com/playlist?list=… 💬 Have questions? Reach out at mtquant@mastertrust.co.in