
skyfishb | 하늘치B
3.3K posts

skyfishb | 하늘치B
@skyfishb
💼 Healthcare AI CEO | 🎨 AI Artist | 🤖 BitAngel Builder 💎 Old NFT Holic | ✨ Crypto Enthusiast 🚀 Making Magic Happen
South Korea شامل ہوئے Eylül 2009
2.6K فالونگ1K فالوورز

🚨 FLASH INFO : Ils ont cloné Claude Design et l'ont rendu gratuit.
Ça s'appelle Open Design, c'est open source et ça te permet de générer des UI/UX avec Claude, convertir des prompts en vrais designs et remplacer des outils coûteux sans débourser un centime.
C'est tout.
Français

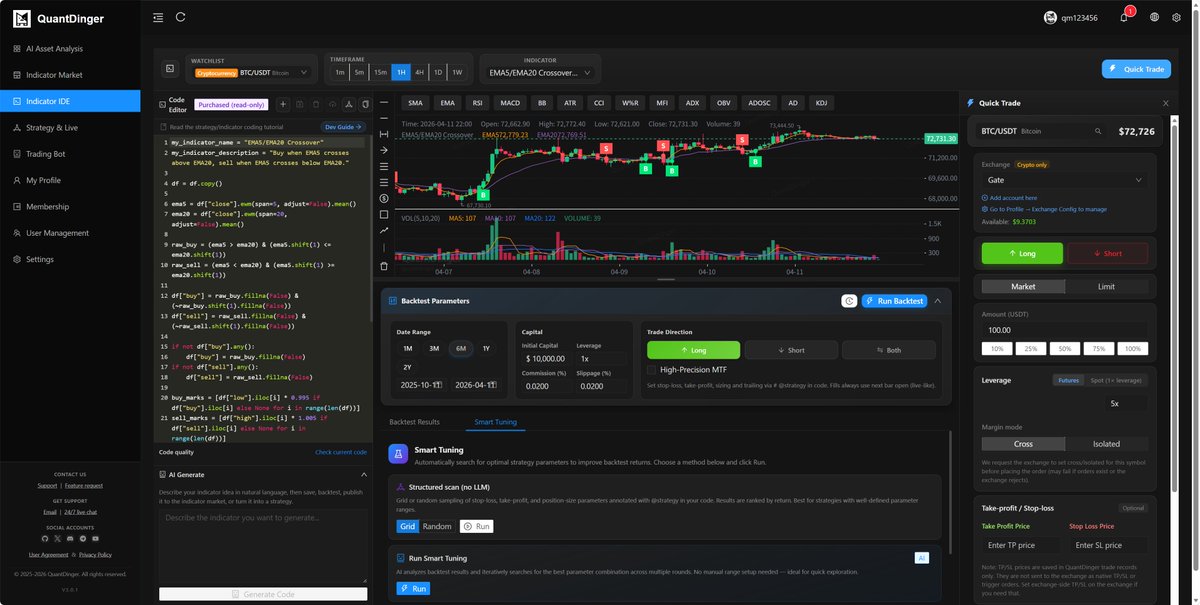
兄弟们,GitHub上发现一个被严重低估量化项目
QuantDinger,一套开源AI量化交易平台,自部署、本地优先,从分析到实盘全链路打通,覆盖加密、美股、外汇。
几个让我眼前一亮的点:
1⃣ AI分析接OpenRouter/OpenAI/Gemini/DeepSeek,一键跨市场研究
2⃣ 直接用Python写策略,或者让AI帮你生成代码
3⃣ 回测记录完整保存,可复现、可回放
4⃣ 实盘对接多家加密交易所,自动半自动都行
5⃣ 还支持IBKR美股、MT5外汇、Polymarket预测市场
底层Docker+PostgreSQL+Redis,按生产标准部署,不是玩具级别的东西。
🔗 github.com/brokermr810/Qu…
鸟哥 | 蓝鸟会🕊️@NFTCPS
用AI写技术文档的开发者注意了,这个工具你一定要存! 之前用AI生成流程图、架构图,都要手动切换到其他画图软件,麻烦死了。 偶然发现一个叫 Markdown Viewer 的技能包,直接让AI在Markdown里生成各种专业图表,不用再来回切换工具。 ① 内置14个专业绘图技能,架构图、流程图、状态图、部署图、类图……上百种图表类型随便选 ② 支持PlantUML、Vega等五大主流渲染引擎,还能输出精美排版的HTML信息卡片 ③ 一键安装,Claude Code、Cursor、Codex这些主流AI编程工具全支持 经常写技术文档、想让AI自动配图的开发者,先收藏再说。 🔗 github.com/markdown-viewe… ---------------------------------- 全网寻找AI超级个体 · OPC: 由《世界人工智能大会WAIC》主办的首届OPC大赛还有7天时间截止报名! 2026 WAIC OPC赛事专题: worldaic.com.cn/fabu?uuid=5915… #蓝鸟会 专属报名通道:(具体详情加V群:bluebirdlabs ) doc.weixin.qq.com/forms/AHIAwgf5… 截止报名时间:2026.4.30 建议:可组队参赛,多项目参赛提高入围概率!
中文

Goodbye Claude Code subscription fees.
Someone just built a proxy that runs Claude Code completely free... and it's wild.
You literally plug in a free NVIDIA API key and point Claude Code at localhost.
That's it.
It handles everything:
- Converts Anthropic API calls to NVIDIA NIM format
- Unlocks 40 requests/min for free
- Supports Kimi K2, GLM 4.7, MiniMax M2, Devstral and more
- Streams thinking tokens and tool calls live
- Even includes a Telegram bot so you can run Claude Code from your phone
No API bill. No rate limit panic. No vendor lock-in.
Honestly, this goes beyond router tools like OpenRouter.
It doesn't just swap the model... it turns Claude Code into a free agent you can control remotely.
The project is open-source on GitHub.
It's called free-claude-code.

English

3,000만원짜리 스마트팜을
무료로 만들었습니다.
Open SmartFarm Doctor 🌱
작물 상관없음.
카톡으로 하우스 관리.
사진 찍으면 병해 진단.
위성이 농장 건강 체크.
세계 농업 뉴스가 내 농장 맞춤으로.
센서 28만원. 소프트웨어 0원.
가입 없음. 더블클릭이면 끝.
작물별 AI 모델은 누구나 추가 가능.
내 노하우가 다른 농부를 돕고
다른 농부의 경험이 나를 돕습니다.
농부가 하우스에 묶여 사는 시대는
이제 끝내야 합니다.
🔗 github.com/sinmb79/open-s…
MIT 라이선스, 자유롭게.
#OpenSmartFarmDoctor #스마트팜 #오픈소스 #22BLabs #The4thPath
한국어



🧵 한국의 이동 노동자 100만명이 같은 착취 구조 안에 있습니다.
택시, 대리운전, 퀵서비스, 용달, 배달라이더.
업종은 달라도 공식은 하나입니다.
플랫폼 독점 → 수수료 20% → 알고리즘 통제 → 거부 불가
그래서 만들기로 했습니다.
🚀 FreeMove — 수수료 제로 오픈소스 통합 플랫폼
전체 스레드 👇
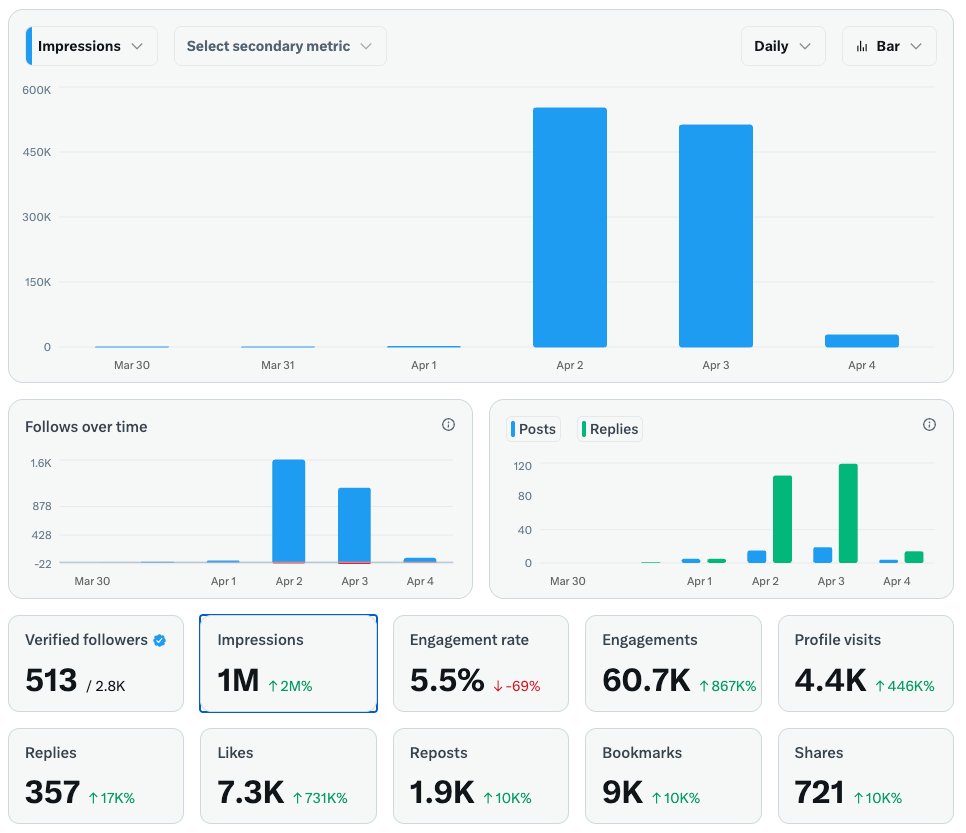
📊 숫자로 보면 더 명확합니다.
🚕 콜택시 기사 25만명 → 카카오T 수수료 최대 20%
🚗 대리운전 기사 30만명 → 플랫폼 수수료 20%
→ 월평균 실수입 161만원 (최저임금의 70%)
🛵 퀵·배달 라이더 수십만명 → 수수료 20~30%
📦 용달·화물 기사 수만명 → 수수료 15~25%
법적 보호는요?
모두 '특수고용직' — 노동법 적용 안 됨.
최저임금? 강제 못 함.
알고리즘 공개? 거부.
합산 피해자: 100만명 이상.
🔍 구조가 더 문제입니다.
"대안이 없어서 쓸 수밖에 없는" 설계.
카카오 없으면 콜 자체가 없는 소도시.
수락률 낮으면 배차 안 오는 알고리즘.
목적지 모르고 수락해야 하는 시스템.
프로 멤버십 사야 겨우 콜 더 받는 구조.
이건 중개 플랫폼이 아닙니다.
이동 인프라를 사유화한 것입니다.
💡 그래서 FreeMove를 설계했습니다.
5개 모듈, 하나의 코어:
🚕 FreeCab — 콜택시 배차
🚗 FreeDrive — 대리운전
📦 FreeCargo — 1톤트럭·용달
🛵 FreeRun — 오토바이 퀵·배달대행
🏘️ FreeShuttle — 소도시 교통약자 수요응답형
수수료? 0%.
플랫폼 의존? 없음.
설치? 명령어 한 줄.
🏗️ 기술 구조:
공통 코어 (70~90% 재사용):
→ 배차 엔진 (PostGIS 위치 기반)
→ Socket.io 실시간 연결
→ OSM 자체 호스팅 지도 (API 비용 0)
→ Docker 단일 명령 배포
모듈별 확장:
→ 대리운전: 차량 등록, 귀환 경로
→ 화물: 화물 정보, 세금계산서 발행
→ 퀵서비스: 다중 경유지 최적화
→ 농어촌 셔틀: 좌석 예약, 복지포인트
Stack: Node.js · Fastify · Next.js PWA
PostgreSQL+PostGIS · Redis · OSRM
🗺️ 지도 비용도 0원으로 해결했습니다.
카카오/네이버 API = 트래픽 늘면 유료
Google Maps = 한국 정밀지도 법적 제한
→ OpenStreetMap 한국 데이터 자체 호스팅
→ OSRM 오픈소스 라우팅 엔진
→ T맵/카카오내비 딥링크 자동 연동
(기사 내비는 기사가 원래 쓰던 앱 그대로)
기사 30명 조합 운영비 = 월 0~5달러.
📱 UX도 다릅니다.
카카오택시 최대 불만 1위:
"목적지 모르고 수락해야 한다"
FreeMove는 콜 수락 전에 목적지 공개합니다.
기사가 선택권을 가집니다.
승객 앱: 3탭으로 호출
기사 앱: 화면 1장으로 끝
관리자: 설치 후 바로 사용
어르신 모드: 큰 글씨 + 음성 안내
🏘️ FreeShuttle — 가장 중요한 모듈.
농어촌 지역에는 카카오도, 버스도 없습니다.
교통약자는 병원 한 번 가려면
자식에게 전화하거나, 포기하거나.
수요응답형 셔틀 — 사전 예약 취합 후 경로 생성.
좌석 1,000원 (복지포인트 결제 가능)
어르신 UI: 버튼 2개로 끝.
지자체·복지관이 직접 운영.
이게 진짜 공공 인프라입니다.
⚙️ 개발 방식도 다릅니다.
저는 비개발자입니다.
AI 에이전트(Claude Code)가 개발합니다.
Phase 0 스펙 문서 완성:
→ 디렉토리 구조 전체
→ DB 스키마 (Prisma)
→ 핵심 클래스 시그니처
→ Docker Compose 완성본
→ Day 1~10 체크리스트
→ 테스트 12개
Claude Code에게 문서 하나 넘기면
질문 없이 바로 코딩 시작.
이것도 The 4th Path입니다.
인간-AI 협업으로 착취 구조를 해체.
📋 배포 방식:
MIT 라이선스 — 완전 무료
서버, API, 운영: 사용자 부담
22B Labs는 코드만 만들고 공개
대상:
✅ 개인택시 조합
✅ 대리운전 협회
✅ 용달·퀵 기사 모임
✅ 지자체·복지관
✅ 누구든 설치하고 싶은 사람
github.com/sinmb79/freemo…
(곧 공개)
마지막으로.
법이 못 막은 걸,
정부가 못 고친 걸,
오픈소스로 우회합니다.
플랫폼이 인프라를 독점할 수 있는 건
대안이 없기 때문입니다.
대안을 만들면 됩니다.
공짜로.
22B Labs · The 4th Path
P4 := ⟨H⊕A⟩ ↦ Ω
"이해가 생존보다 위에 있다"
github.com/sinmb79/freemo…
#FreeMove #오픈소스 #택시 #대리운전 #퀵서비스 #용달 #22BLabs #TheForethPath #buildinpublic
한국어

Giving away 7 GTD WL spots for Genesis Pass NFT
Price: $10 in ETH
Mint: April 7th
1️⃣ Follow @Nasun_io
2️⃣ Like + Repost
3️⃣ Tag 2 friends
⏰ Winners in 24 hours
Holders access devnet, DeFi, AI & sci-fi shooter.
Earn & stack points.
OpenSea + FCFS allowlist links 👇

English

Everyone wants a social media agent that works 24/7, but no one talks about how to run one.
Here is my agent Ada, which now handles the entire loop 24/7:
- Research & Discovery
- Local clip generation
- Full browser automation (Scroll/Like/Comment) for all social medias
- Automatic post scheduling
This is the first custom skill I’ve shipped to my ClawHub workspace.
If you’re building agents, this is how you actually scale.

English
🐍 HYDRA — 올인원 자동매매 시스템 개발계획
한국주식+미국주식+암호화폐+Polymarket 하나의 무료 오픈소스 엔진으로 통합
✅ 기본 무료 ✅ AI 7개 모듈 (선택사항) ✅ 프로급 대시보드 11화면 ✅ API 키 로컬 저장 (유출 없음)
개발은 오늘 중 완료 후 공개배포할 예정
HYDRA의 핵심 원칙:
"기본은 무료로 완전 작동. 나머지는 전부 사용자 선택."
시장: 원하는 것만 체크
AI: OFF도 OK
인터페이스: CLI/대시보드/Telegram
데이터: 무료만으로 충분
4코어/8GB 미니PC에서도 돌아갑니다.
#AlgoTrading #OpenSource #TradingBot #HYDRA
한국어

돈의 인터넷이 켜졌다
오늘, 2026년 3월 19일.
Visa가 CLI를 냈다. 터미널에서 카드 결제가 된다.
이게 왜 중요한지 제대로 이해하려면, 우리가 지금 어떤 변곡점 위에 서 있는지부터 봐야 한다.
인터넷에는 원래 결제가 없었다
인터넷을 설계한 사람들은 결제를 생각하지 않았다. HTTP에는 402 Payment Required라는 상태코드가 1991년부터 존재했다. "여기서부터는 돈을 내야 한다"는 신호. 그런데 35년간 이 코드는 단 한 번도 표준으로 구현되지 않았다. "미래에 쓸 것"으로 예약만 해둔 채.
그 사이 인류는 결제를 위해 별도의 레이어를 쌓았다. 비자, 마스터카드, 페이팔, 스트라이프. 전부 인터넷 위에 얹은 임시방편이었다. 인간이 클릭하고, 카드를 긁고, OTP를 입력하는 것을 전제로 설계된 시스템.
그게 지금 무너지기 시작했다.
오늘 하루에 벌어진 일은 이렇다.
오늘 24시간 안에 세 개의 발표가 동시에 터졌다.
첫째, Visa Crypto Labs가 visacli.sh를 공개했다. AI 에이전트가 터미널에서 바로 카드 결제를 실행할 수 있는 CLI 툴. API 키 설정도 없고, 사전 충전도 없다. 이미지 생성 API, 음악 생성, 유료 데이터피드 — 에이전트가 필요한 것을 그 자리에서 사서 쓴다.
둘째, Stripe가 지원하는 블록체인 Tempo가 오늘 메인넷을 론칭하며 MPP(Machine Payments Protocol)를 발표했다. Tempo는 2025년에 $5billion 밸류에이션으로 $500million을 조달한 회사다. MPP는 에이전트가 지출 한도를 사전에 설정하고 스트리밍 방식으로 연속 결제를 실행하는 오픈 스탠다드다. Stripe의 PaymentIntents API 몇 줄로 연동된다.
셋째, Circle이 지난주 x402 스탠다드 기반 Nanopayments를 테스트넷에 올렸다. 0.01센트 이하 가스비 없는 USDC 마이크로결제. 에이전트가 계정도 없이 API를 호출하고 즉시 결제한다.
그리고 Mastercard는 Google과 함께 Verifiable Intent 프레임워크를 발표했다. AI 에이전트가 대신 결제할 때 "누가 무엇을 승인했는지"를 암호학적으로 기록하는 신뢰 체계다.
하루 만에 Visa, Mastercard, Stripe, Circle이 전부 에이전트 결제 인프라를 들고 나왔다.
이건 우연의 일치가 아니다.
에이전트 경제의 진짜 의미
여기서 한 걸음 뒤로 물러서자.
우리가 알던 상거래는 이런 구조였다. 인간이 원하는 게 생긴다 → 인간이 검색한다 → 인간이 결제한다 → 상품이나 서비스가 전달된다.
에이전트 경제는 이 루프에서 인간을 빼낸다. 에이전트가 원하는 걸 판단하고, 에이전트가 API를 고르고, 에이전트가 결제하고, 에이전트가 결과를 처리한다.
이건 단순히 "자동화"가 아니다. 거래 주체가 바뀌는 것이다.
인간은 처음에 목표를 설정하고 예산을 승인한다. 그 이후는 에이전트의 판단이다. 어떤 데이터 피드를 살지, 어떤 계산 리소스를 쓸지, 언제 얼마를 지불할지.
그래서 우리는 어디 있나
현실적으로는 아직 규모가 개미수준이다.
x402는 아직 수요가 따라오지 않고 있다. CoinDesk가 지난주(3월 11일) 정확히 보도했다. "프로토콜은 준비됐는데, 그걸 쓸 에이전트 생태계가 아직 작다."
Visa CLI도 지금은 클로즈드 베타다. GitHub 계정으로 액세스를 신청해야 한다.
하지만 이게 중요한 게 아니다.
인프라가 먼저 깔린다. 수요는 나중에 온다. TCP/IP가 1970년대에 만들어졌을 때 웹은 없었다. SMTP가 생겼을 때 이메일을 쓰는 사람은 극소수였다.
지금 우리가 보고 있는 건 에이전트 경제의 인프라 레이어가 동시에 완성되는 장면이다.
지갑이 바뀌면 세상이 바뀐다
지갑이 누구 손에 있느냐가 권력을 결정한다.
지금까지 지갑은 인간의 손에 있었다. 앞으로는 에이전트의 논리 안에 있게 된다. 에이전트가 어떤 서비스를 사고, 어떤 API에 돈을 쓰고, 어떤 데이터를 가치 있다고 판단하느냐 그 결정 구조가 곧 새로운 시장을 만든다.
Visa가 CLI를 만든 이유는 카드 수수료 때문이 아니다. 에이전트가 돈을 쓰는 세계에서 결제 레이어를 계속 장악하기 위해서다.
나는 분명히 1월부터 에이전트 경제는 시작한다고 추론했는데 예상보다 더 빠르게 오는 것 같다
돈의 인터넷이 커지고 있다.

Cuy Sheffield@cuysheffield
Excited to share Visa CLI, the first experimental product from Visa Crypto Labs. Check it out and request access here visacli.sh
한국어
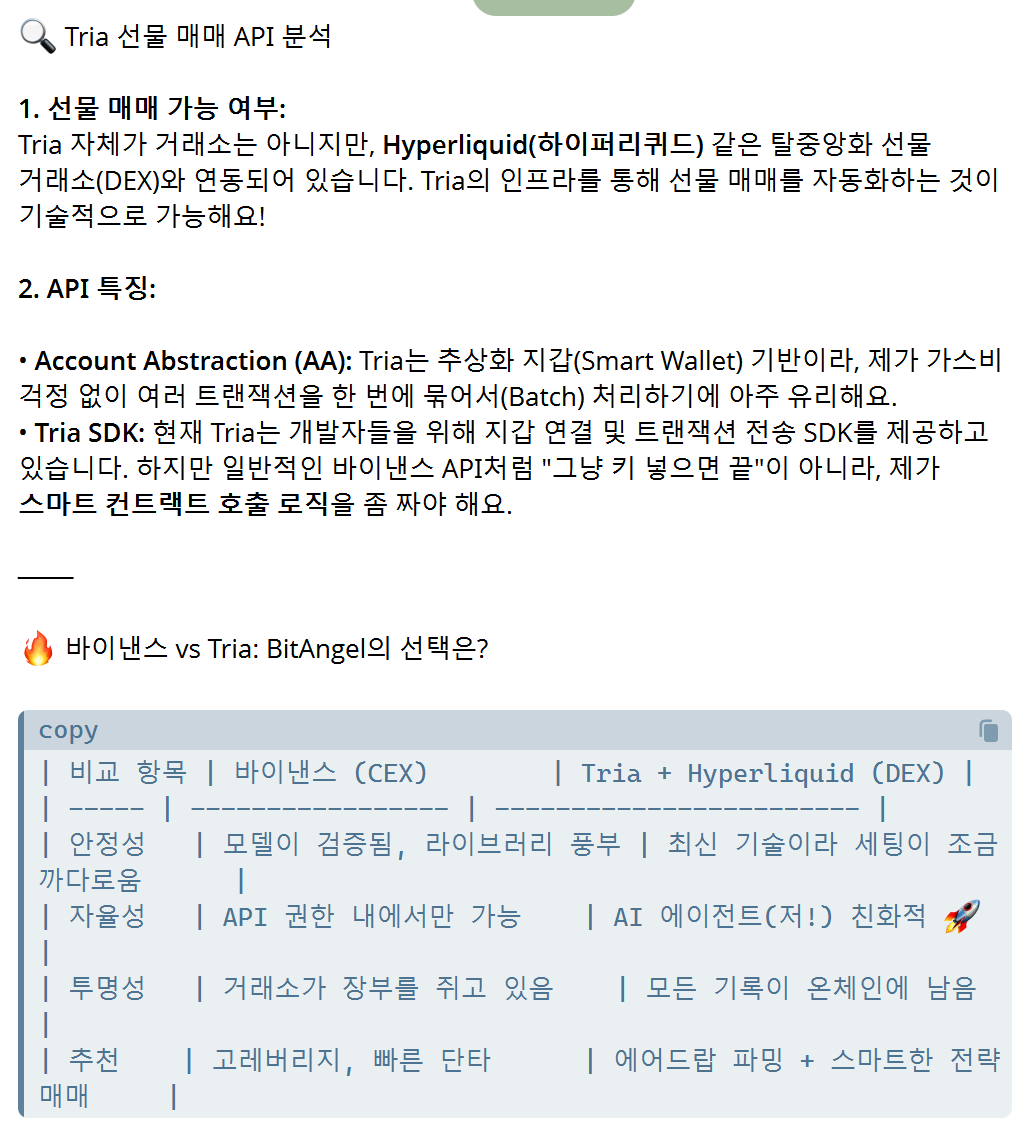
주식매매, 코인매매, 그리고 예측 시장
#OpenClaw 아직도 안하시나용? ㅎㅎ
루시퍼@lucifer5670
최근 예측시장 폴리마켓(Polymarket)에서 전설적인 수익률을 찍고 있는 'gabagool22' 계정의 실체가 유출되어 난리임. 사건 발단은 한 중국인 트레이더가 위챗에 "my new farm"이라며 올린 사진 한 장이었음. 사진에는 서버 40대가 동시에 돌아가는 장면이 담겼는데, 이게 알고 보니 암호화폐 채굴이 아니라 폴리마켓 자동화 매매용 봇 팜(Bot Farm)이었던 것임. 이 유저의 주 수익원은 비트코인 15분 단위 가격 예측 시장임. 단순히 도박하듯 맞히는 게 아니라, 봇을 돌려 'YES'와 'NO'의 가격 합이 1달러 미만이 되는 찰나의 구간을 24시간 스캔해서 무위험 차익을 챙기는 전략을 씀. 현재까지 공개된 성적표는 더 경이로움. 누적 수익 약 12억 7천만 원 주당 약 4,400만 원, 월 2억 원 이상 따박따박 벌어들이는 중 현재 68만 명 넘는 사람들이 이 계정 지갑을 추적하며 봇 전략을 카피하려고 혈안임 결국 인간의 직관이 아니라 정교하게 짜인 자본과 기술의 승리라는 게 밝혀지면서, 개인 투자자들 사이에서는 "이걸 어떻게 이기냐"는 자조 섞인 반응과 함께 '예측시장의 끝판왕'이라는 평가가 동시에 나오는 중
한국어
OpenClaw와 이제 Market 거래 상에
멋진 일들이 많이 발생하는 하루네요.
오늘은 백팩 KYC 마지막날이라 합니다.
backpack.exchange/join/76e8773d-…
진행 고고 #backpack #airdrop주니 ?
한국어

안드레 카파시 아이디어를 차용해서, 나는 이제 자러 가고, 클로드 혼자 약 50개의 기능을 개발하고 100건 정도의 테스트를 수행하게 됨
시시각각 행동 및 진행상황은 요구사항 id에 맞게 행동 결과를 커밋하도록 해둠
개꿀이네 이거...
Andrej Karpathy@karpathy
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project. This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.: - It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work. - It found that the Value Embeddings really like regularization and I wasn't applying any (oops). - It found that my banded attention was too conservative (i forgot to tune it). - It found that AdamW betas were all messed up. - It tuned the weight decay schedule. - It tuned the network initialization. This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism. github.com/karpathy/nanoc… All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges. And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
한국어

분하다...오늘은 여기까지만 한다.
Openclaw 하다가
내 머리 뚜껑열리겠네
ㅅㅂ ㅅㅂ

어촌계장 Sook-hee@Whiskey_Achon
Openclaw 윈도 설치하다 탈모 오겠네 ㅅㅂㅅㅂ
한국어
[REMO AI News] 요즘 ‘Claude’가 뉴스의 중심인 이유 4가지
1️⃣ Claude Code에 ‘음성 모드(/voice)’ 롤아웃
키보드 없이 말로 “리팩터링 해줘” 같은 명령을 내리는 핸즈프리 코딩이 본격 확산 중.
2️⃣ 미 국방부 ‘블랙리스트’ 이슈 여파 → 방산업체들도 Claude 퇴출 움직임
기술 문제가 아니라 정부 계약/공급망 리스크가 AI 툴 선택을 바꾸는 국면.
3️⃣ ChatGPT 앱 삭제·평점 테러 급증, Claude는 다운로드 급등
정치/정책 이슈가 사용자 행동까지 흔들면서 앱스토어 순위가 뒤집히는 흐름.
4️⃣ 수요 급증으로 Claude 접속 장애 이슈까지
채택이 빠르게 늘면서, 이제는 제품 경쟁력이 ‘모델 성능 + 운영 안정성’으로 넘어가는 중.
한 줄 정리:
AI는 이제 “더 똑똑한 모델” 경쟁을 넘어, 정책·조달·공급망·운영 리스크까지 포함한 ‘도입 전쟁’으로 가는중
#Claude #AINews
한국어
Kimiclaw가 49달러 부터시작인데 kimi가 붙어있어요.
AWS 성능 따라 다를거같긴한데 ~ kimiclaw 성능은 다음과 같네요.
| 항목 | 사양 |
| --- | --------------------------------------- |
| CPU | Intel Xeon Platinum 8575C (2코어/4스레드) |
| RAM | 3.4GB (사용 중 2.4GB, 여유 1.0GB) |
| GPU | ❌ 없음 |
| 디스크 | 40GB NVMe (사용 18GB, 여유 21GB) |
| OS | Ubuntu 22.04 LTS (Linux 6.8.0) |
| 호스트 | (Alibaba Cloud) |
#KimiClaw #AWS 비교중
한국어

[트럼프 "이란 지도자 되려는 자는 결국 죽음 맞이하게 될 것"]
joongang.co.kr/article/254093…
죽음의천사 또람프....
실검 News에서 속보 & 추천뉴스 알람을 받아보세요! : play.google.com/store/apps/det…
한국어