Thao ری ٹویٹ کیا

“You look happier”
“Thanks, the Nasdaq 100 is up 18.5% in the past month”
English
Thao
1.9K posts


@tpvt136
mostly make, occasionally take, sometimes (angel) invest @VamientXyz
Cinder is an open-source trading terminal for @PhoenixTrade perpetuals on Solana. Level 3 order books, charts, liquidations. Local-first DeFi. Minimal resource footprint. #top" target="_blank" rel="nofollow noopener">cinder.trading/#top


One of the more depressing conversations a person can have is public markets investors talking about their career outlook


Home robots might be arriving faster than expected. 🤖 Backed by Alibaba, ByteDance, Xiaomi, and Meituan, @XSquareRobot has already been deploying cleaning robots into real homes through a partnership with 58[.]com (often referred to as China’s Craigslist) — now serving hundreds of households and expanding. The setup is straightforward: humans handle complex tasks, robots take on repetitive work like tidying and wiping. Now they’ve unveiled WALL-B, a new embodied foundation model — and say new robots powered by WALL-B will enter real homes in 35 days. Under the hood is their WUM (World Unified Model), training perception, decision-making, action, and physical prediction as one system from the start. The key is real data. Every hour in a real home feeds the model. Still early. The system makes mistakes. Needs supervision. But it runs 24/7 — and keeps learning. That’s the shift. Not perfect robots. But robots that improve inside real homes.



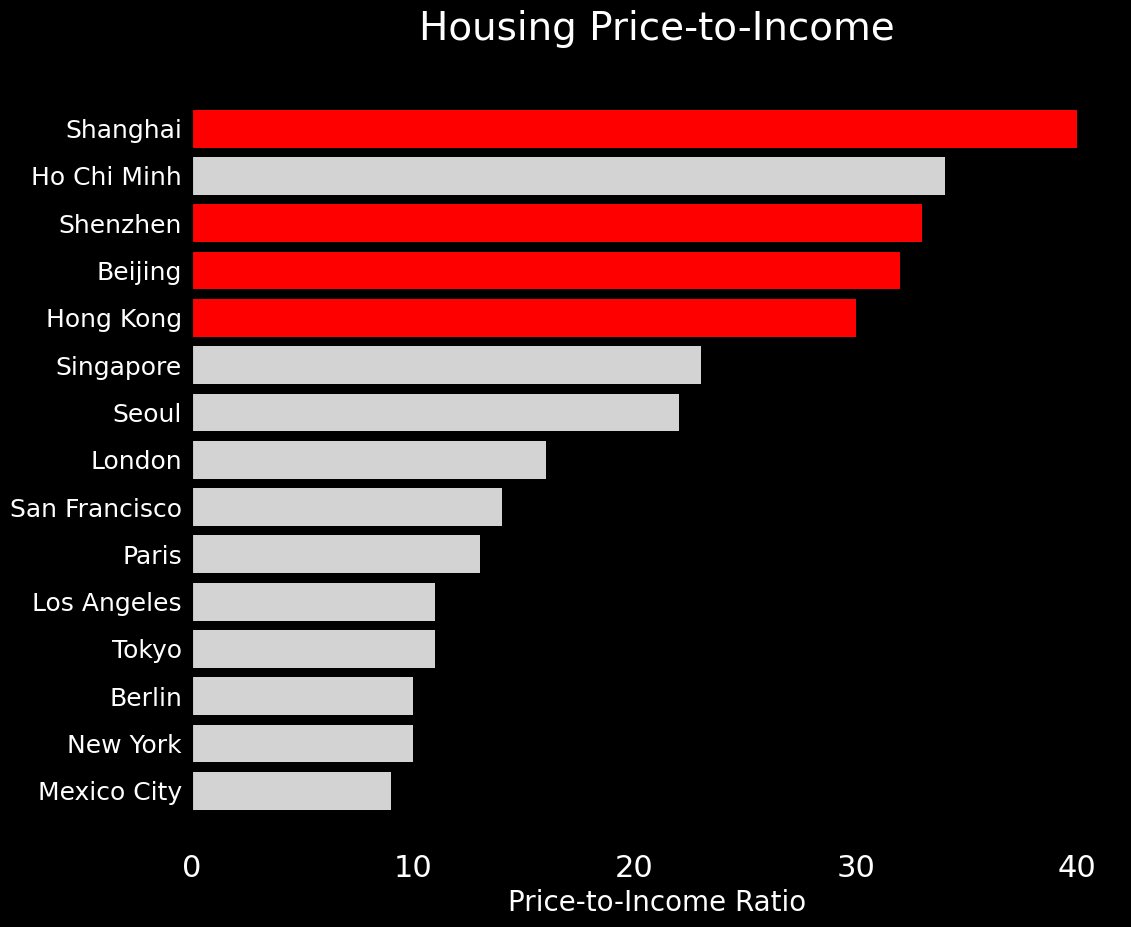
As a foreigner in China who saw apartments in Shanghai selling for $100k 20 years ago that are now worth $1M+, I asked my wife, "Does this mean we can now afford to move closer to the city?" She laughed. We looked at the real estate apps. And while prices are down, an apartment that was $1.4M at the peak is now selling for $1.2M. Some areas are hit harder, some not hit at all. Where we live in Fengxian, in a villa compound, there's been almost no change. Same goes for the next district over in Jin Shan. The apartment we bought in my wife's hometown some years ago went up and is now back to around the price we bought it for. Kinda meh 🤷 Most people we know are happy to see prices come down. Things were getting out of hand. Now young people can continue to afford to buy a home. But negative headlines about China still got to make a living I guess 😂



Thanks @domcooke for spending months on researching and writing this piece. Einstein once said, "If you can't explain it simply, you don't understand it well enough." By that measure, Dom has blown me away with how deeply he came to understand Hyperliquid and what we're all building together. When someone asks what "housing all of finance" means, I'm proud to point them to this piece. I hope readers appreciate just how much Dom and his team put into their work. It reflects the thoughtful craft that is in Hyperliquid's DNA. Special thanks to @patrick_oshag for taking a bet on Hyperliquid's story.

The degree to which you are awed by AI is perfectly correlated with how much you use AI to code.






OpenAI is backing Isara, a new startup founded by two 23-year-old AI researchers that coordinates thousands of AI agents to solve complex problems, like using ~2,000 agents to forecast gold prices. The company just raised $94M at a $650M valuation and plans to sell predictive modeling tools to finance firms first.

"I think that Hyperliquid will eat commodities trading. It's cool to watch oil perps trade on weekends, [but] that's literally 1% of what's possible for just one commodity." @jvb_xyz @1000xPod