
Howard Felix
160 posts


Statement from President Trump on South Pars Gas Field:

English
Howard Felix đã retweet

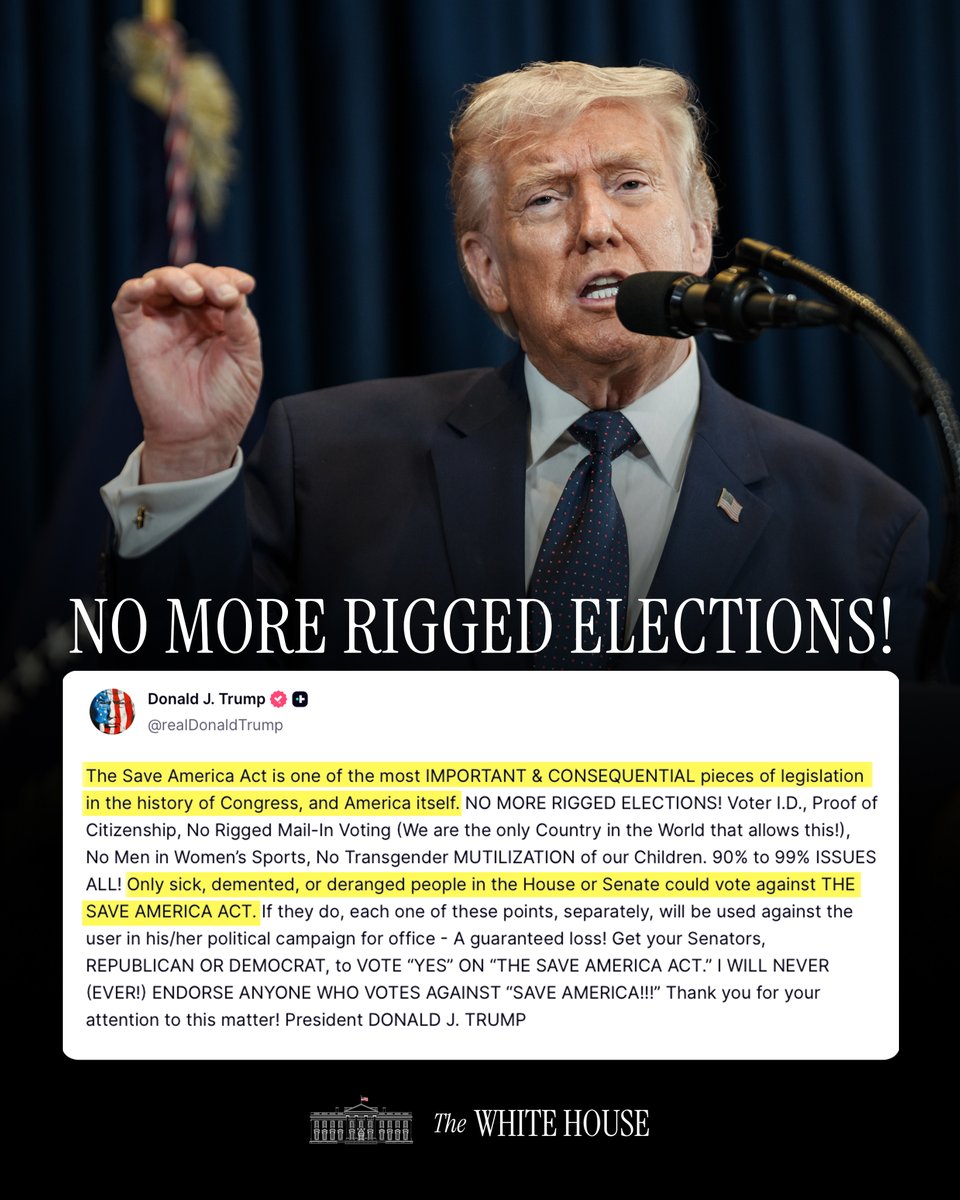
"The Save America Act is one of the most IMPORTANT & CONSEQUENTIAL pieces of legislation in the history of Congress, and America itself. NO MORE RIGGED ELECTIONS!" - President Donald J. Trump 🇺🇸
English
@honeymoon250 When they moved United States down to U in country code boxes lol
English



BREAKING: President Donald Trump has announced that the United States, together with its allies, will reopen the Strait of Hormuz by using military force to ensure safe navigation.
He calls on countries to deploy warships to the Strait of Hormuz alongside the United States, while America will continue large-scale bombardments along the coastline and the destruction of Iranian military targets.
A Marine Corps expeditionary force is on its way as well as the 82nd Airborne Division as President Trump‘s war quickly escalates into a new world war…

English

Here is an xAI story.
When I was first hired (low level) by xAI, I was extremely excited. I greatly admired Elon and what Grok could be.
I have a pretty cool AI following here on X. Some big names see my stuff, including Elon himself (at the time).
Lex, Beff, Andreessen, Aravind, many others.
During the interview and onboarding for xAI, they made a *big deal* about wanting people who "take initiative" and think outside the box. Ok...
So, some of the biggest names in tech follow me on X. I decided to ask for ideas and feedback on how Grok (then still early at version 2) could be improved.
I asked my followers on X for the best "how can we make Grok awesome?" ideas, and was going to collect them (organized by Grok himself) into a big report for my boss(es) and ultimately, Elon.
(xAI makes a big deal about how it's a "flat structure" also. You're supposed to be empowered to act on good ideas.)
Well, my post got way more attention than I expected - great! Ideas to improve Grok poured in! I built a script to collect and sort all these great ideas to make xAI's core product better.
John Carmack (personal friend of Elon, creator of Doom, id software, legend) retweeted it. Carmack has 1M followers.
There were so many great ideas on how to improve Grok! I was collecting them and excited. Until.......
I woke up the next day to a threatening email from my main supervisor* at xAI, telling me I had messed up, that I was NEVER to ask for ideas to improve Grok ever again, that it wasn't my job (I thought our job was to improve Grok.)
They suspended my account on X. They never explained why. It was obviously related to my post about improving Grok.
I was told to delete those posts which had gone viral. I had to delete all the hundreds (thousands?) of genuinely good ideas for improving Grok that had poured in by users on X, because it stepped on someone's toes.
It made me confused and sad. Incidents like this happened often, where xAI employees would come in full of excitement and enthusiasm, and would have it stomped out by managers who hated ideas.
They filled xAI with middle managers and busybodies. It was one of the most DEI and corporate-y places I've ever worked. I came in wanting Elon and xAI to win and left just sad.
*That manager is gone, for what it's worth.
Everyone I knew at xAI is gone.
Elon Musk@elonmusk
@beffjezos xAI was not built right first time around, so is being rebuilt from the foundations up. Same thing happened with Tesla.
English

@peterwildeford xAI will catch up this year and then exceed them all by such a long distance in 3 years that you will need the James Webb telescope to see who is in second place
English

Based on the data I see, I think:
- Anthropic🇺🇸/Google🇺🇸/OpenAI🇺🇸 all ~tied
- Meta🇺🇸 / xAI🇺🇸 each ~7mo behind
- Moonshot🇨🇳/- Deepseek🇨🇳 / zAI 🇨🇳 / Alibaba🇨🇳each ~9mo behind
- Mistral🇫🇷 ~1.5 years behind
- No other companies competitive
Ethan Mollick@emollick
Both xAI and Meta seem to be falling behind, based on the Grok 4.2 benchmarks and this reporting. Frontier AI models are really a three way race at this point.
English
English
Many talented people over the past few years were declined an offer or even an interview @xAI. My apologies.
@BarisAkis and I are going through the company interview history and reaching back out to promising candidates.
Elon Musk@elonmusk
@beffjezos xAI was not built right first time around, so is being rebuilt from the foundations up. Same thing happened with Tesla.
English


@heygurisingh Soon as Elon buys 200,000 gpus Microsoft releases this lol
English

Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License.
English
English

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanoc…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

English
@elonmusk It's an offense that seems to repeat from victimization to victim
English

@OpenSourceZone what kind of idiot is voting favorably
English


@Hazelkeech0918 You should booty bump a shot of vodka for celebration
English

My name is Elina I'm from the USA. I'm single, 53, and have been battling alcohol addiction for 8 years. Today marks 600 days of sobriety. ❤️🩹💔
English

Who believed in you when you didn’t believe in yourself?
English

These are “give-up” pants.
You will never see a person who is doing well in life wearing them in public.
You will never see someone who has it together mentally/physically/emotionally wearing them.
This is natures warning sign for “I cannot be relied upon because I can’t even rely on myself to take care of myself.”
The Food Professor@FoodProfessor
One of my pet peeves at the grocery store: seeing people shop in their pajamas. Call me old-fashioned…
English
Another 𝕏 peak usage record this week
Mario Nawfal@MarioNawfal
March 1, 2026. 𝕏 breaks its own record. 513 billion user-seconds. In one day. Previous high? 417 billion. Gone. When the world moves, it moves on 𝕏.
English
@MrBeast So basically 10 people break even for quiting their jobs and living like a liberal
English


Only Grok speaks the truth.
Only truthful AI is safe.
Only truth understands the universe.
The Rabbit Hole@TheRabbitHole
English
