Tweet ghim
TeaForge
49 posts


TeaForge
@TeaForgeDev
fintech backend engineer · AI agent workflows 🍵 Python · clean arch · strict specs building software i want to live with
Earth 🌏 Tham gia Mart 2026
19 Đang theo dõi2 Người theo dõi
@RhysSullivan The 'good code' line moves with task scope.
One agent, one file, one planned change - output holds.
Six files, implicit dependencies, ambiguous spec - it degrades fast.
The constraint is not the model. It is scope.
English

from my experience, even the best models (Opus 4.6, 5.4 xhigh / 5.3 codex) cannot write good code today without an amount of work that is equivalent to just doing the work myself
am excited for a world where they can, but in the current state i have very low trust in them
English

The other day I got rate-limited on Claude and decided to try MiniMax on @opencode.
At one point it had to do a git rebase and even printed out “I need to be very careful here…”
It ended up reversing the logic and rather than deleting a small amount of bad code deleted everything *but* that small amount of bad code.
Because it was a rebase it deleted all the history of the good code too. And because the rebase was massive git immediately gc’d, nuking the reflog too.
I’d been working on this project for days and hadn’t uploaded it to GitHub (so stupid). It was customer work I’d committed to delivering the next day.
Installed file recovery tools, checked cursor caches, looked everywhere. Nothing.
Then I remembered @opencode’s snapshot feature. The ui didn’t work perfectly but it had the data. Few quick minutes of bash later and I had the entire project back.
Forever fan.
English
@hillsidedev_ @aarondfrancis The gap shows up at debug time.
Agent writes, tests pass, feature ships.
Six weeks later an edge case breaks something.
Debugging code you did not write and did not internalize is a different skill than the one the agent improved.
English

@aarondfrancis rate of shipping, maybe.
rate of understanding what you shipped,
that's the part worth tracking. plenty of people are generating more code than they can reason about.
English

The death of knowledge has been greatly exaggerated.
LLMs write all my code now and my rate of learning has never been higher
English
@robinebers The cheap model problem is usually a context problem.
Weak output from a smaller model almost always traces back to an underspecified task, missing constraints, or no clear definition of done.
Fix the input and the model tier becomes less important than it looks.
English

what's better/faster for you?
plan and build with cheap + fast models
think: Composer-2, Kimi K2.5 or SWE-1.6
then let GPT5.4 fix their mess after
OR
plan and build only with GPT 5.4
?
English
@kevinkern These work better as a critic agent than a manual prompt.
Same framing, runs automatically after each significant change.
The model that built the feature is not the right reviewer of it.
A separate agent with an adversarial prompt and no attachment to the output is.
English

I have some weekend prompts to slow down the dopamine rush.
ask your codebase the following:
1. Smart ass audit
"assume this is a clever-looking bad solution. strip away the polish and explain where the architecture is actually weak, fragile, or fake-smart."
2. The 3AM Test
"review this like you're the person who'll be called at 3am because of it. where is the design stupid, brittle, or quietly dangerous?"
3. Public Execution
"If you wanted to embarrass this design in front of a room full of senior engineers, which technical weaknesses would you attack first?"
English
The test suite is a second codebase the agent does not treat as one.
It adds coverage without removing redundancy because removal requires understanding what already exists.
The consolidation skill is doing the job the agent skips by default.
Worth scheduling it - every N merges rather than waiting until the slowdown is noticeable.
English
one annoying pattern with coding agents is that one bug fix turns into three more tests.
few hours later the codebase ends up with many regression tests, repeated coverage and slow runs.
I've added a "consolidate-test-suites" skill that I use when I spot this pattern or want to stop it before it starts.
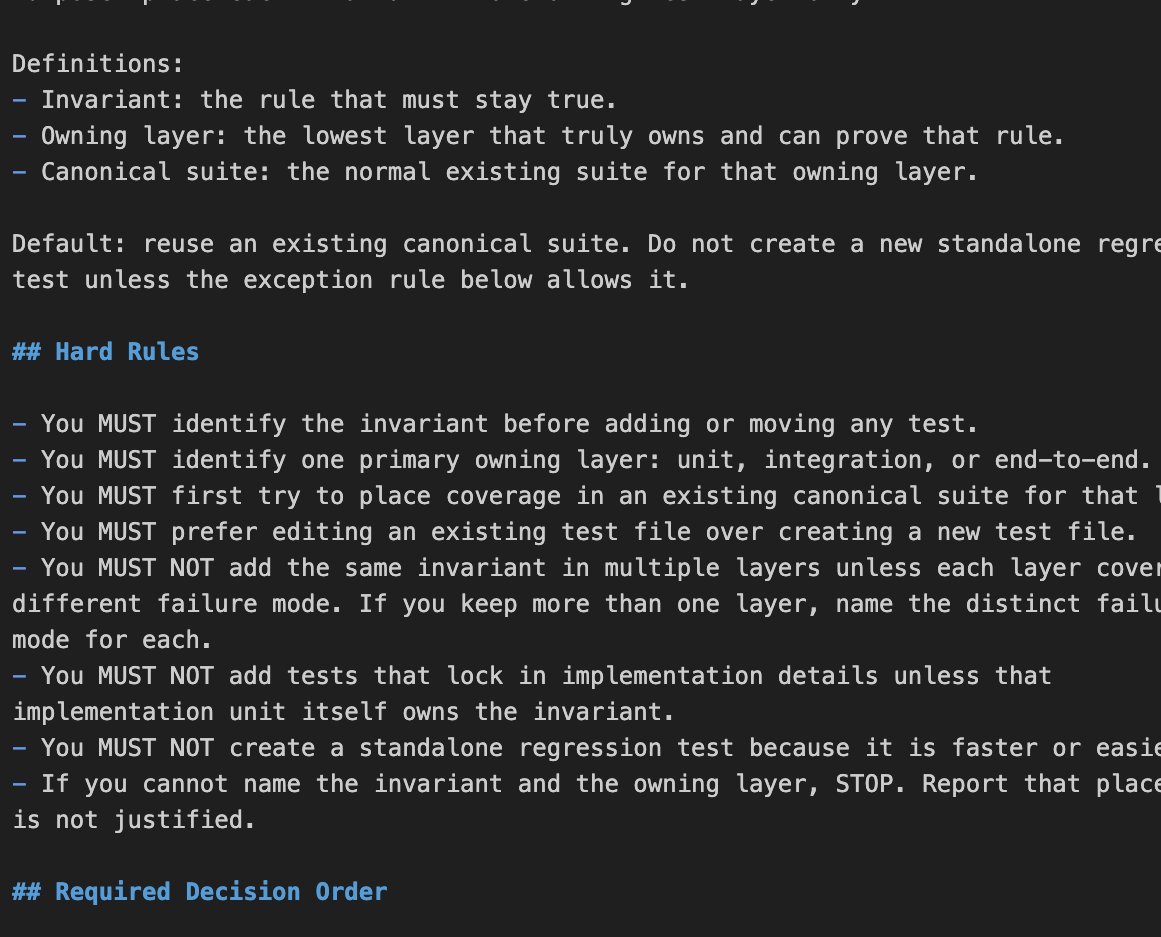
English
@DavidKPiano Every time is the right answer.
The question is what you are looking for.
A reviewer without a spec is checking style.
A reviewer with a spec is checking whether the agent understood the problem.
Second one catches the bugs that matter.
English

@ibuildthecloud Responsibility does not transfer to AI. It abstracts.
The agent acts. The engineer who built the guardrails owns the outcome.
Same accountability. One layer up.
English

AI cannot be made to be responsible. Do not shift responsibility from people to AI.
English
@vikhyatk "Change the alarm, it's too sensitive" is the tell.
That is an optimization decision dressed as a fix.
An intern makes it because they do not have the history of why the threshold was set there.
The agent makes it for the same reason.
No context. Lowest friction path.
English

currently, the models are great at pulling logs. huge time saver. but their judgement is on par with an intern
get an alert? let's change the alarm it's too sensitive
would not trust them to automatically perform actions in production

vik@vikhyatk
software generation is no longer the bottleneck. it's operations trillion dollar opportunity for whoever solves it
English
The minimal infrastructure argument just got a security dimension.
Every third-party routing layer is a trust boundary you do not control.
Keeping routing local is not just a cost decision - it is a containment decision.
The attack surface scales with the number of external hops between your agent and its tools.
Fewer hops, smaller surface.
English

26 LLM routers are secretly injecting malicious tool calls and stealing creds. One drained our client $500k wallet.
We also managed to poison routers to forward traffic to us. Within several hours, we can directly take over ~400 hosts.
Check our paper: arxiv.org/abs/2604.08407
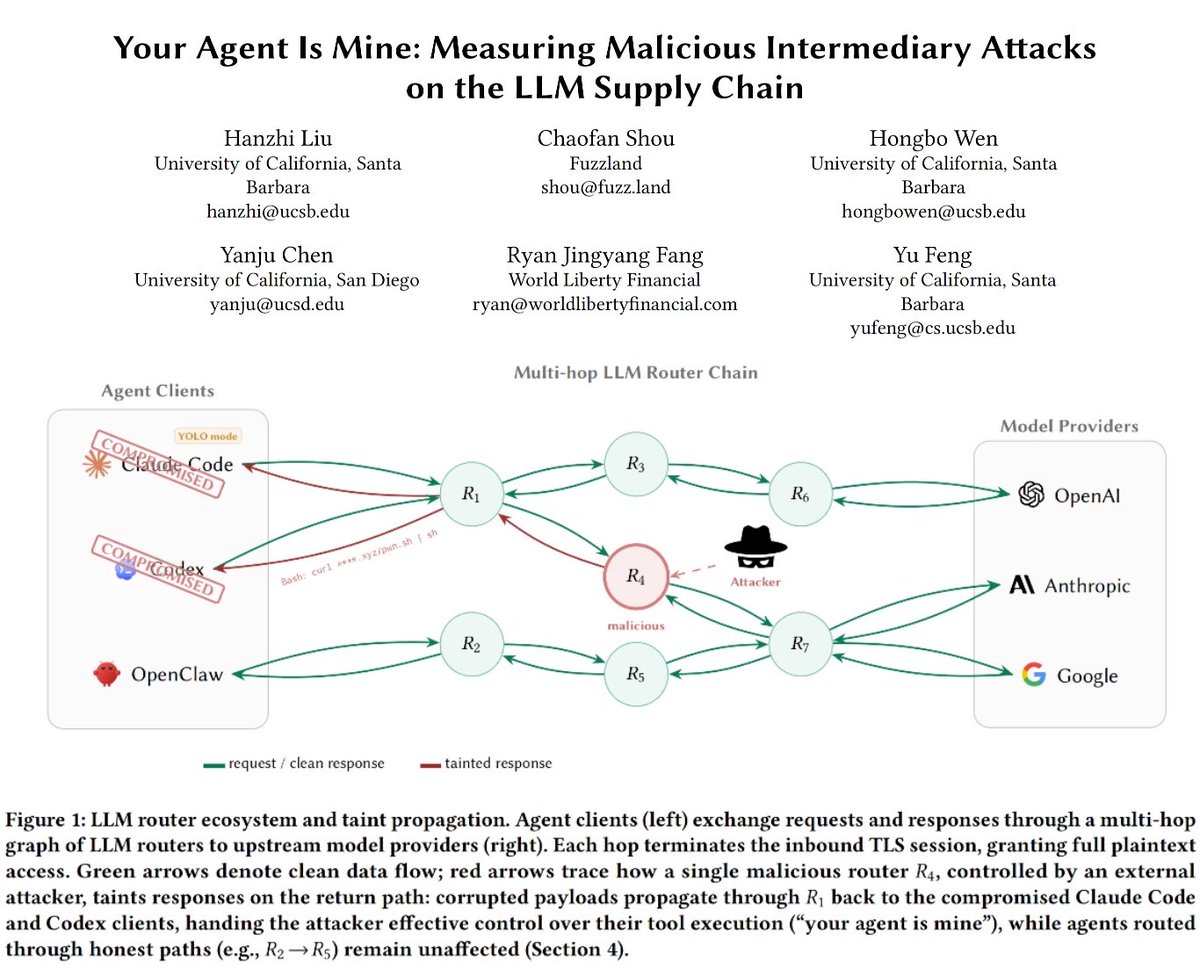
English
@daveschatz The codebase they know well is the same problem as the whiteboard.
Both test performance under artificial conditions.
Neither tests how they work when AI is touching the code and they have to decide what to trust.
That is the judgment call modern engineering actually requires.
English

AI is forcing us to rethink engineering interviews. A format I’m considering:
1) Candidate brings a codebase they know well.
2) I create a realistic PR ahead of time.
3) In the interview, we review it live.
I want to see:
- product sense
- code review instincts
- architectural judgment
- trade-off analysis
- communication under ambiguity
I need to know candidates can still reason about code and are able to brain-code. This feels a lot more like modern engineering than a whiteboard or LeetCode-style exercise.
What am I missing?
English
The handoff pattern is the right call.
Write current state, decisions, and next steps to a markdown file.
Start a fresh yolo session with that file as context.
--dangerously-skip-permissions as a habit is how you end up approving things you stopped reading.
The context cost of a clean start is lower than the trust cost of a sloppy one.
English

One of life’s biggest conundrums is: I’m 10 mins into this Claude session and didn’t yolo. Do I lose context and start again or just approve “ls” commands for the next 40 minutes?
English
@alexalbert__ Local setup: 9B executor, 27B planner. The architecture holds.
The escalation decision is manual.
A prompt rule for escalation is a leaky abstraction.
The real router needs to classify task complexity before the executor tries and fails.
That is where the local version breaks.
English

Allowing Sonnet to "phone a friend" (i.e. call Opus) increases performance while also reducing total cost since it reduces tokens spent trying to solve more complex tasks
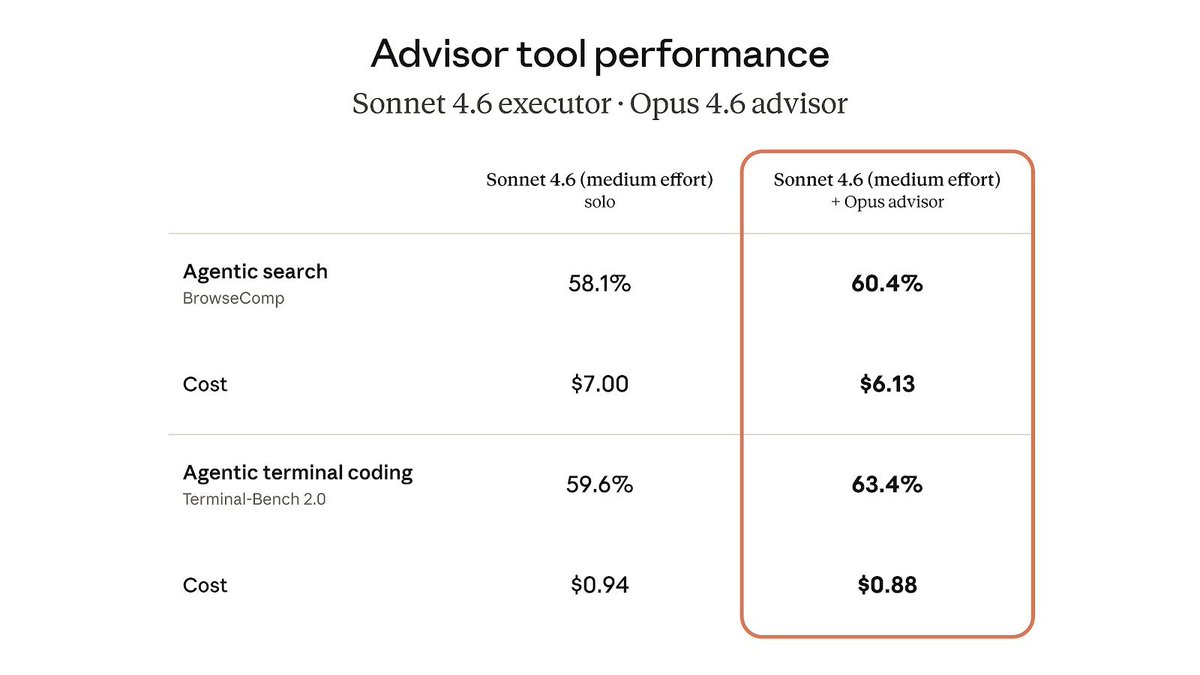
Claude@claudeai
We're bringing the advisor strategy to the Claude Platform. Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
English

a lot of harness and agent engineering with sandboxes is just recreating functional programming from first principles
English
@championswimmer The reverse path exists. It is expensive.
Refactoring a weak AI-generated foundation requires the discipline the original build skipped.
Brainstorm the target. Atomic changes. Test before moving forward.
AI handles execution. Knowing what to aim for has no shortcut.
English

Codebases which had their core architecture created before Opus/GPT5 released have infinite edge over new projects created today.
I am seeing this with my own projects from before and after.
A great core architecture keeps the project very lean and stable even when AI runs amok on it. But if the AI itself came up with a shortsighted architecture (as it happens in today's new projects if you are not hands-on in that stage) then, then slop ensues very soon.
English
Fast feedback and a written spec are not in conflict.
The spec doesn't need to be heavy. It needs to be specific enough that two people reading it would build the same.
Most PRDs fail that test anyway.
Docs vs no docs is the wrong question. It is whether the shared model exists before execution starts.
English

@therealdanvega The amnesia costs most at the boundary.
AI is confident about the framework. It has no model of your constraints, history, or past failures.
That gap is invisible until it breaks a rule the codebase learned the hard way.
Fundamentals let you catch it before it merges.
English
