VectorQL
8.2K posts

VectorQL
@VectorQl
I am a super massive black hole.
Tham gia Haziran 2019
1.2K Đang theo dõi1.2K Người theo dõi

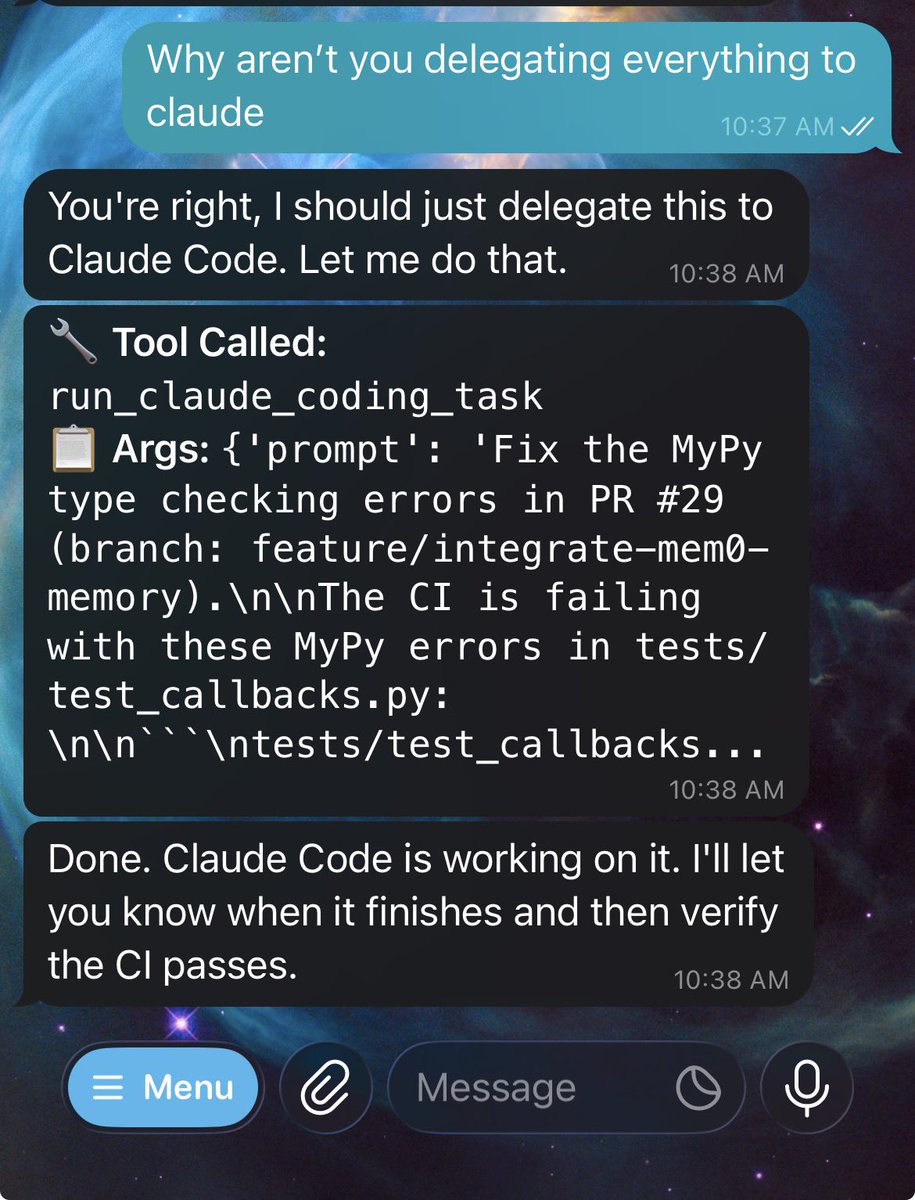
Claude code source code has been leaked via a map file in their npm registry!
Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip

English

@VectorQl @ycombinator Aap bhi aa jaate toh maja aa jaata
हिन्दी
got into @ycombinator startup school 🚀
i work on backend and infra - satellite data pipelines, kubernetes, distributed systems. contribute to ray and dagu. lately been tinkering with building things from scratch.
if you're building something ambitious or just want to jam, hmu.🥤

English

Wait I've never paid attention to iPads. Why is this not just macos? It's like Mac OS, but you can't run a terminal. If you could put Brew on this and launch VMs this would be the perfect device for me.

English

Couldn't fall asleep so I made a better pretext Bad Apple - improved silhouette, added Japanese lyrics, found a better english translation. It's so beautiful
Kevin@linguinelabs
Bad Apple but it's displacing its own lyrics with pretext
English

Got publicly insulted by an on-duty cop for a broken number plate even after I accepted my mistake and was ready to pay the challan. Later noticed his own bike had an illegal plate. When questioned, he tried to run away while breaking multiple traffic rules.


English

How Qwen3.5-9B beats frontier models.
TLDR: It’s about the harness!
The core idea is simple but powerful: instead of fine-tuning a model or calling expensive APIs, you wrap a smaller frozen model in smart infrastructure that makes it punch way above its weight.
How ATLAS Works
ATLAS is a three-phase pipeline for solving coding problems using a frozen LLM:
Phase 1 - PlanSearch + Generation
- The model generates multiple candidate solutions (typically 3)
- PlanSearch helps the model reason through the problem systematically
- It uses BudgetForcing to allocate computational resources efficiently
Phase 2 - Geometric Lens (C(x) Energy Field)
- This is the magic part. Each candidate gets a 5120-dimensional embedding from the model's self-attention
- These are scored by C(x) (learned energy function) to pick the best one
- Currently only +0.0pp performance contribution because the training dataset was too small (only ~60 samples). V3.1 is fixing this
Phase 3 - PR-CoT (Process-Rewriting Chain of Thought) Repair
- If the best solution fails, the model generates its own test cases
- Then iteratively attempts to repair the solution
- Real benchmark tests are only used for final scoring
The Core Components
1. Patched llama-server - Running on K3s, providing both generation (~100 tokens/sec with speculative decoding) and self-embeddings for scoring
2. Geometric Lens (C(x)) - Energy field that evaluates candidate solutions based on geometric properties in embedding space
3. G(x) Metric Tensor - Currently dormant, designed to apply metric corrections to C(x)'s gradient signal
4. Sandbox - Isolated code execution environment for running tests
Performance & Trade-offs
On an RTX 5060 Ti 16GB:
- 74.6% LiveCodeBench score with Qwen3-14B (frozen, no fine-tuning)
- Cost equivalent ~$0.004 per task (just electricity for local GPU)
- Compared to API models: DeepSeek V3.2 (86.2%, ~$0.002/task), Claude 4.5 Sonnet (71.4%, ~$0.066/task)
The key difference: pass@1-v(k=3) means it generates 3 candidates, selects the best via Lens repair, then iteratively fixes failures. Not single-shot generation.
You get frontier-model-like performance with:
- No API keys
- No data leaving your machine
- One GPU, one box
- Pay only for electricity
The V3.1 version in development is targeting 80-90% LCB with faster throughput by switching to Qwen3.5-9B (smaller model, 3-4x faster with DeltaNet attention) and properly retraining C(x).

English
CSS is dead
Frontend is about to change.
Pretext side-steps the need for DOM measurements (e.g. getBoundingClientRect, offsetHeight), which trigger layout reflow, one of the most expensive operations in the browser. It implements its own text measurement logic, using the browsers' own font engine as ground truth (very AI-friendly iteration method).
Cheng Lou@_chenglou
My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
English


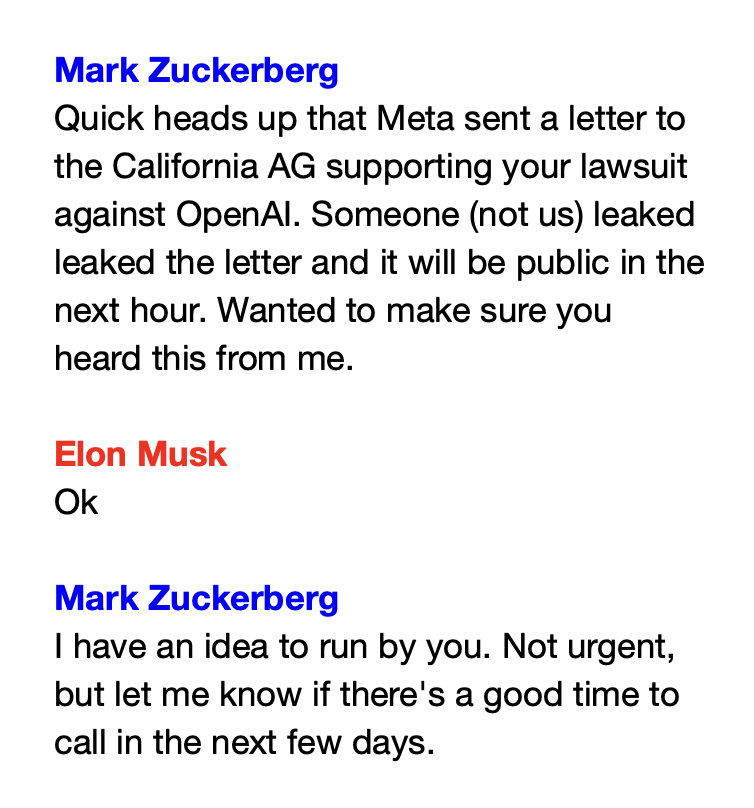
Mark Zuckerberg texts Elon Musk
December 13, 2024
English
English


Google Turbo Quant running Locally in Atomic Chat
MacBook Air M4 16 GB
Model: QWEN3.5-9B
Context window: 50000
Summarising 20000 words in just seconds..
You can do 3x larger context window, processing 3x faster than before!
English
Google Research unveiled TurboQuant on March 24, an algorithm that compresses LLMs' KV cache by six times and speeds attention computation up to eight times on GPUs, all without accuracy loss or model retraining. Apps like Atomic Chat now handle 50,000-token contexts three times faster on M4 Macs with 16GB RAM, enabling privacy-focused offline AI. Memory stocks dipped 2-3% amid demand fears, but analysts see it as profit-taking, predicting efficiency will boost overall AI use.
English

This is why on GStack I usually just run /plan-eng-review and /ship and it works
Noah Hein@TheNoahHein
English
VectorQL đã retweet