Tweet ghim

devPad
52 posts





You can now enable Claude to use your computer to complete tasks. It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk. Research preview in Claude Cowork and Claude Code, macOS only.


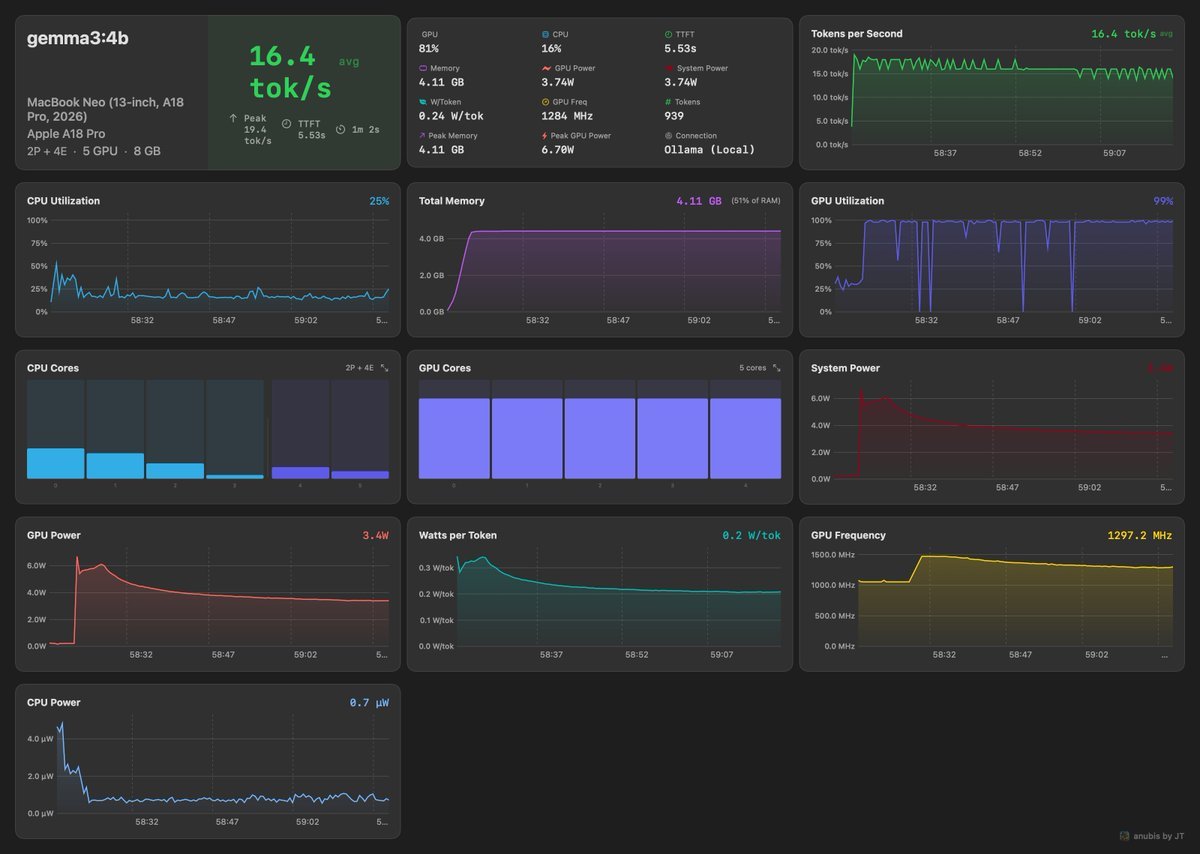
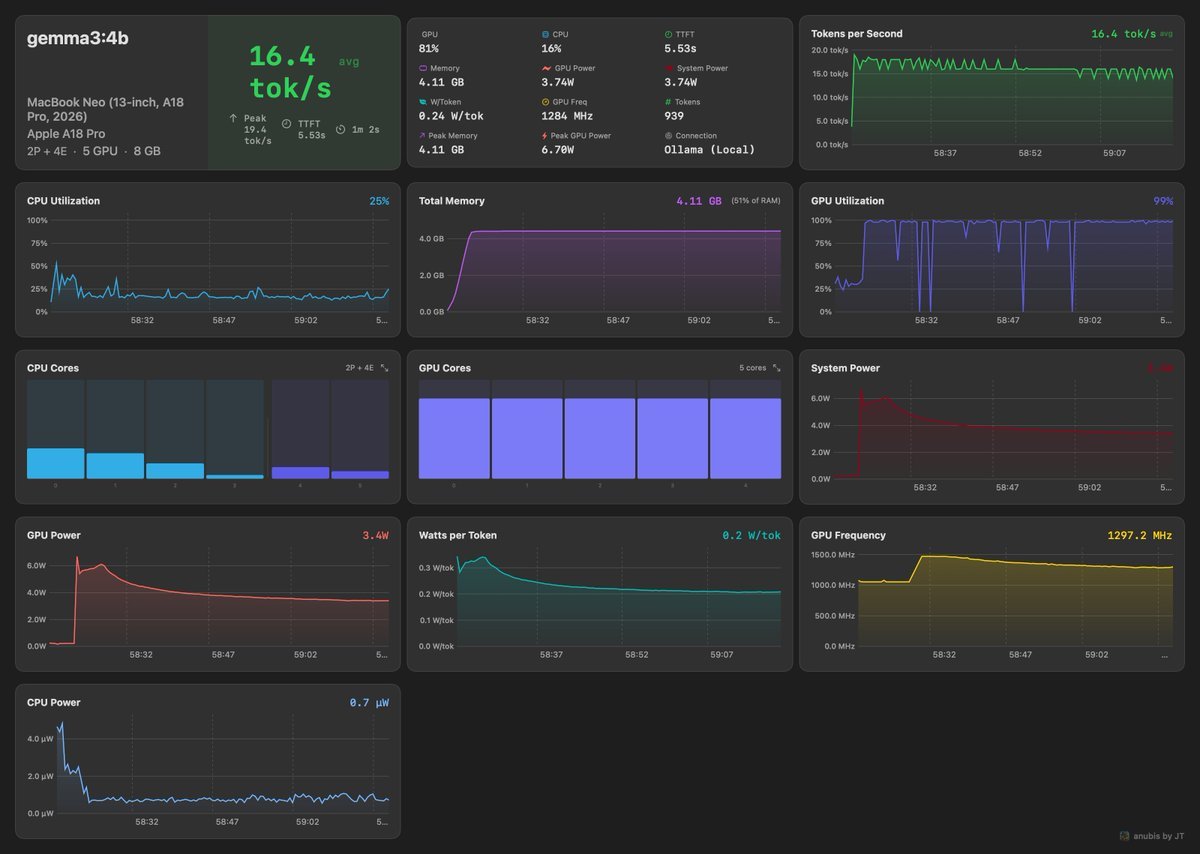
PSA: If you have multiple macbooks that support RDMA, you can cluster them using @exolabs and run 30B+ models at 70 tok/s over thunderbolt5. tensor parallelism on consumer hardware is a solved problem. you are renting GPUs that are worse than the laptop on your couch. 2X M4 Max(64GB each) running mlx-community/Qwen3-30B-A3B-4bit @ 70 TPS













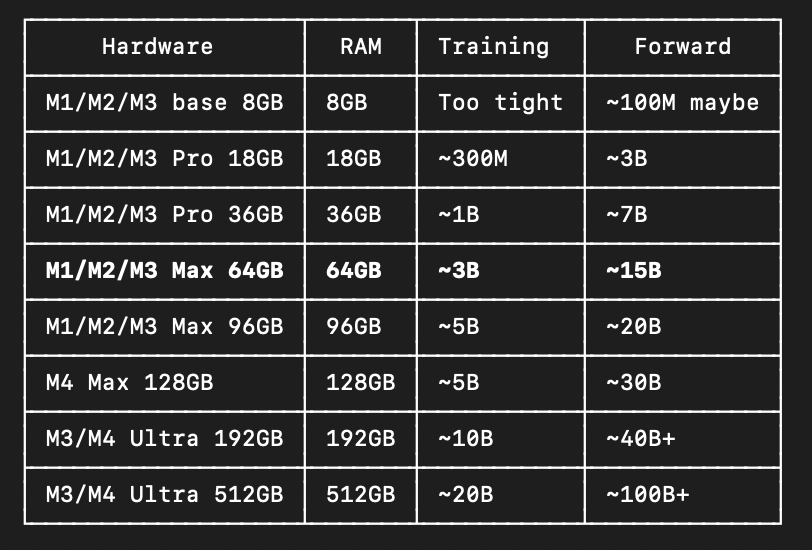
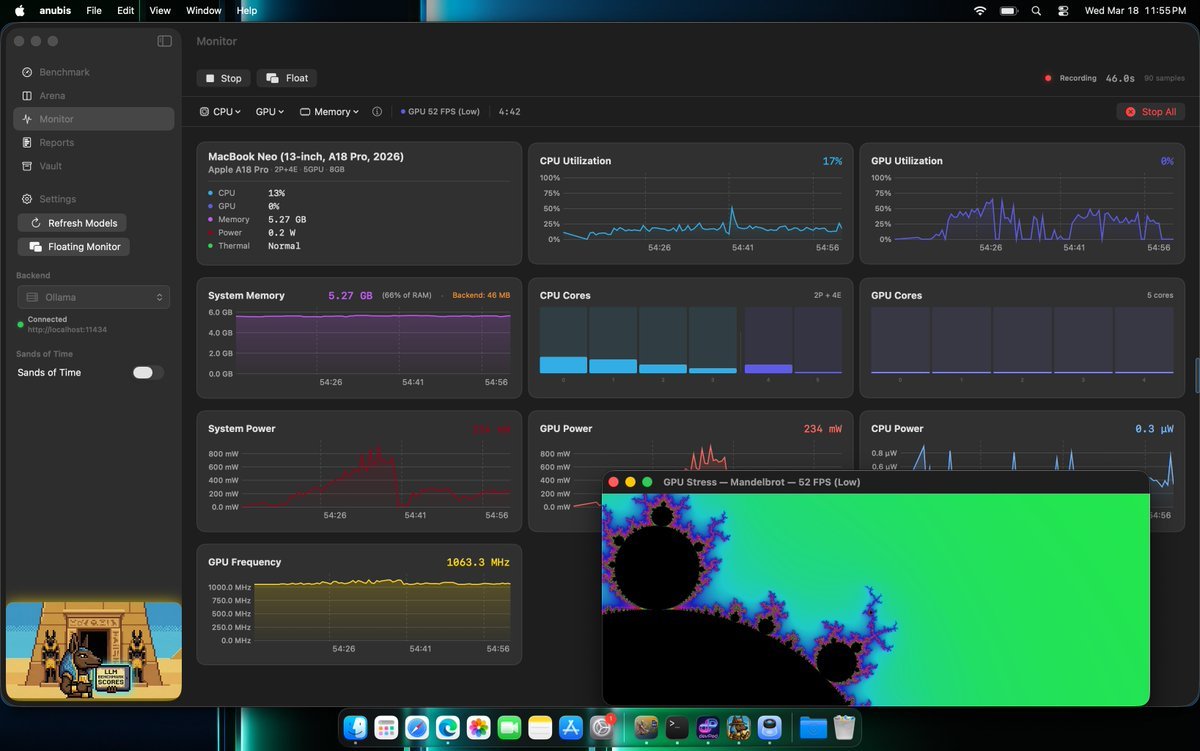
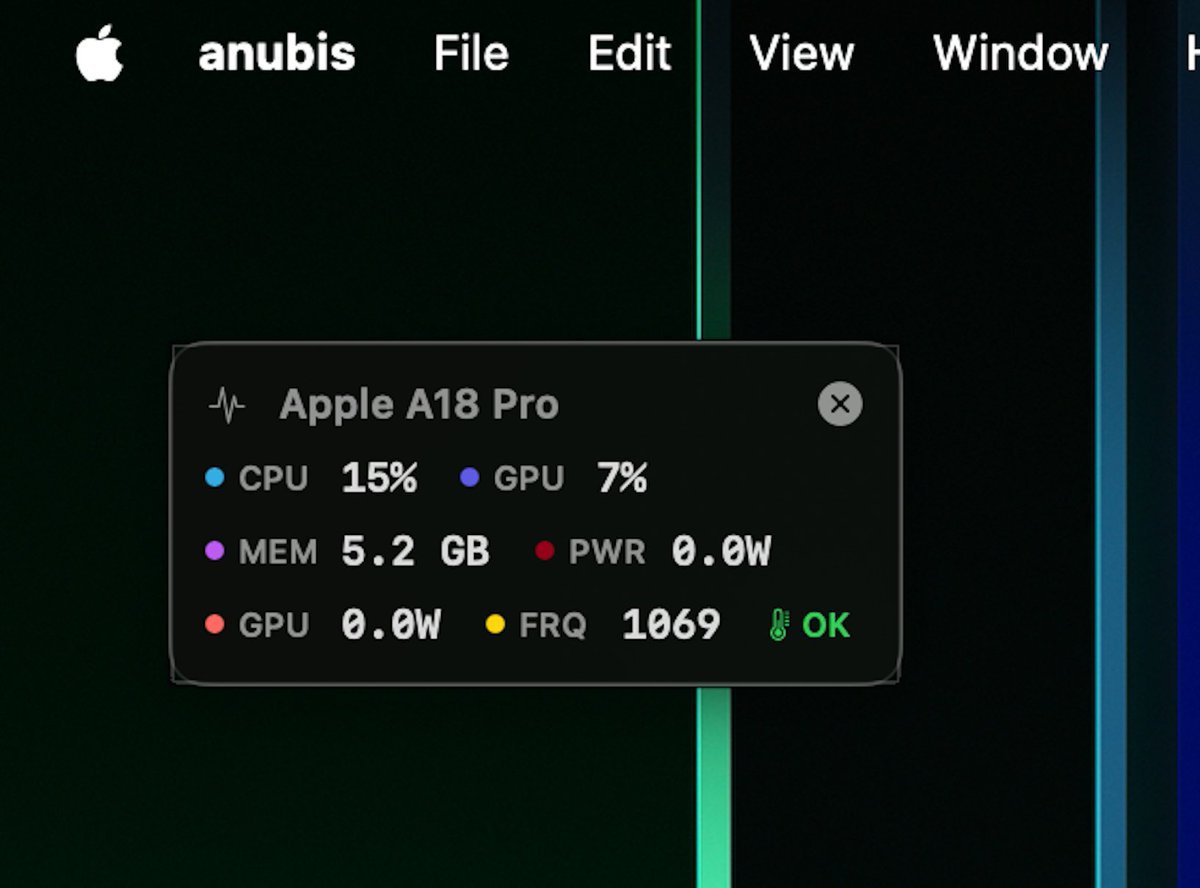
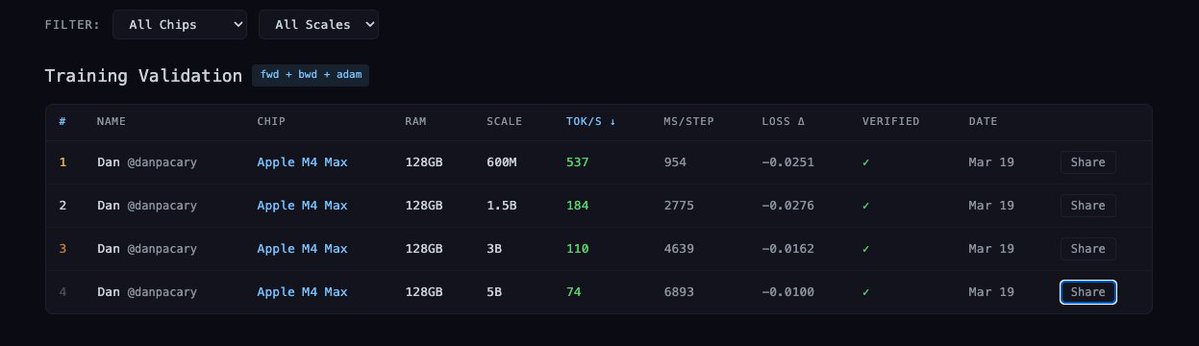
I just trained a 5B param model on Apple's Neural Engine. On a MacBook Pro. Forward. Backward. Adam optimizer. Then I checked to see how far it would go. Technically got to 30B.