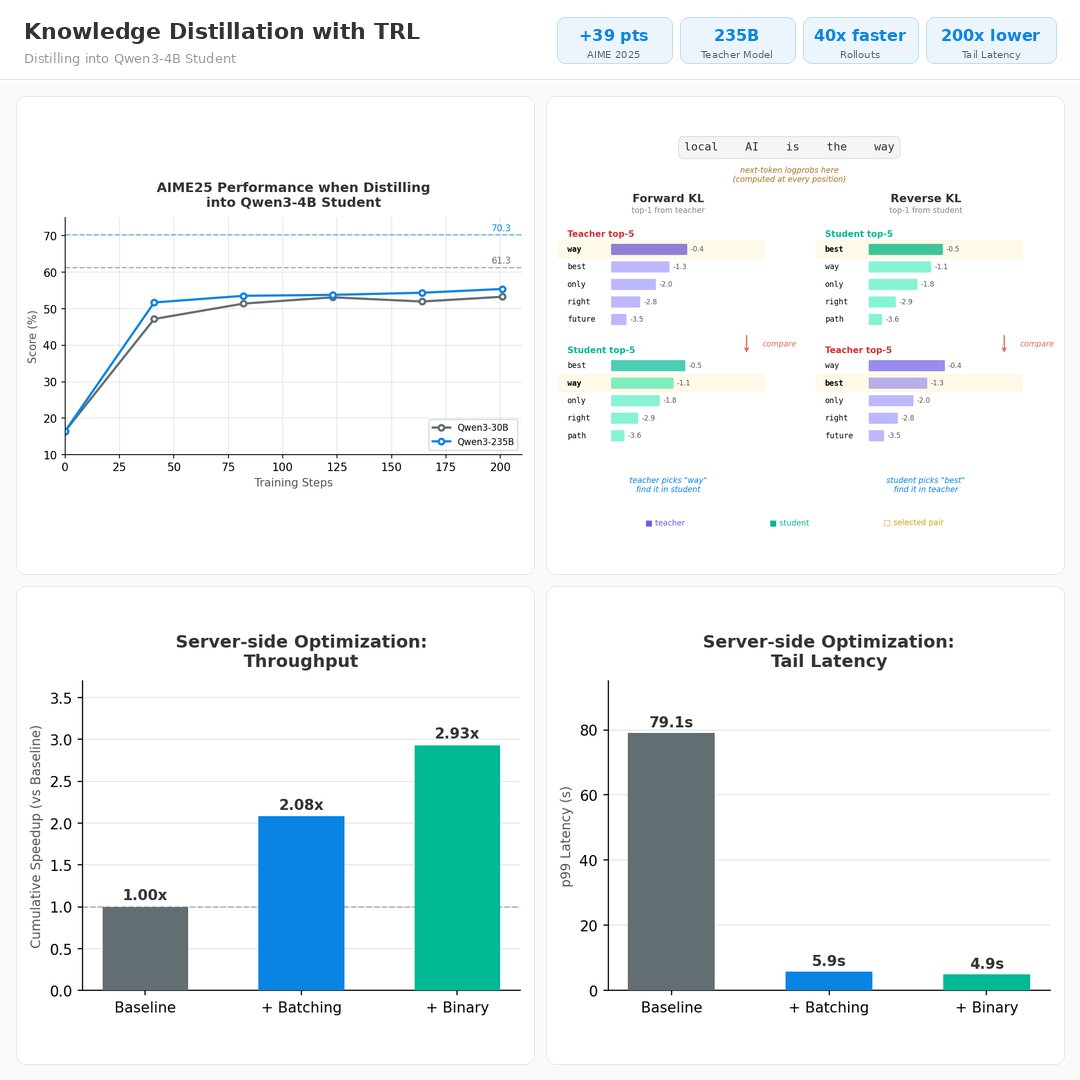
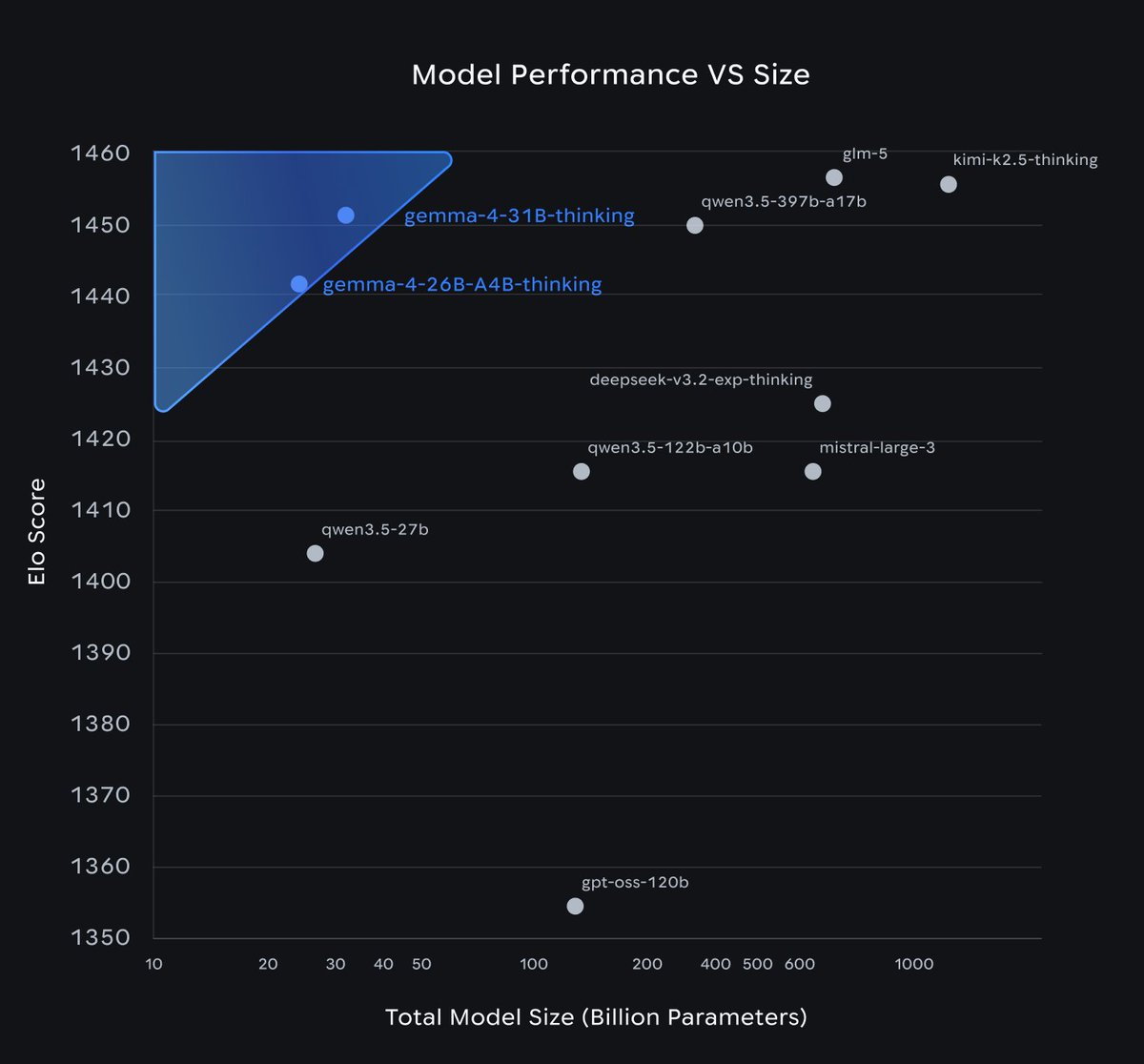
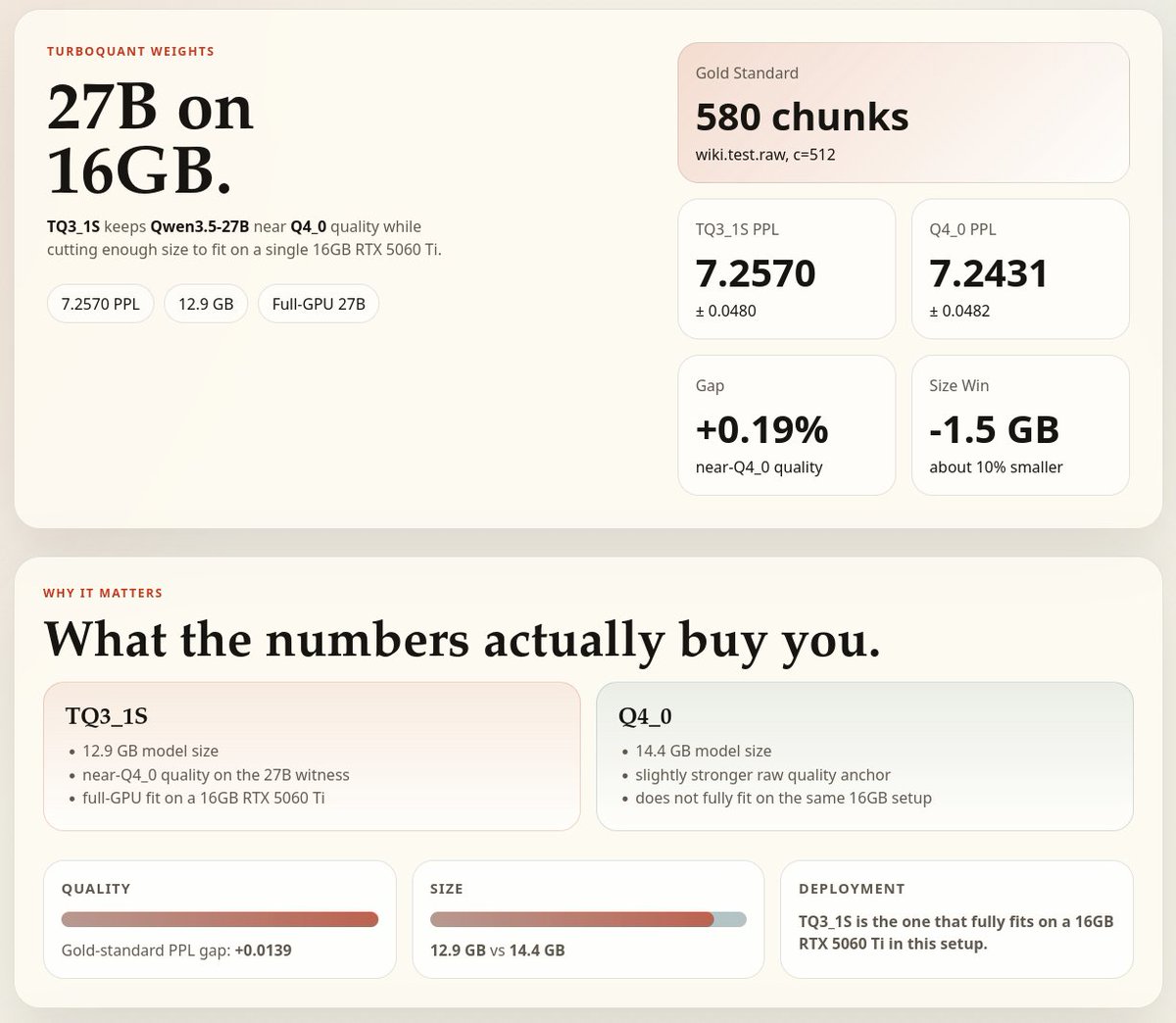
Frank Lin đã retweet

Yay, finally! Introducing Vision Banana🍌 from @GoogleDeepMind, our unified model that outperforms SoTA specialist models on various vision tasks!
By treating 2D/3D vision tasks as image generation, we unlock a new foundation for CV.
Project page: vision-banana.github.io
(1/5)
English