fudingyu đã retweet

Reasoning VLAs can think. They just can't think fast. Until now.
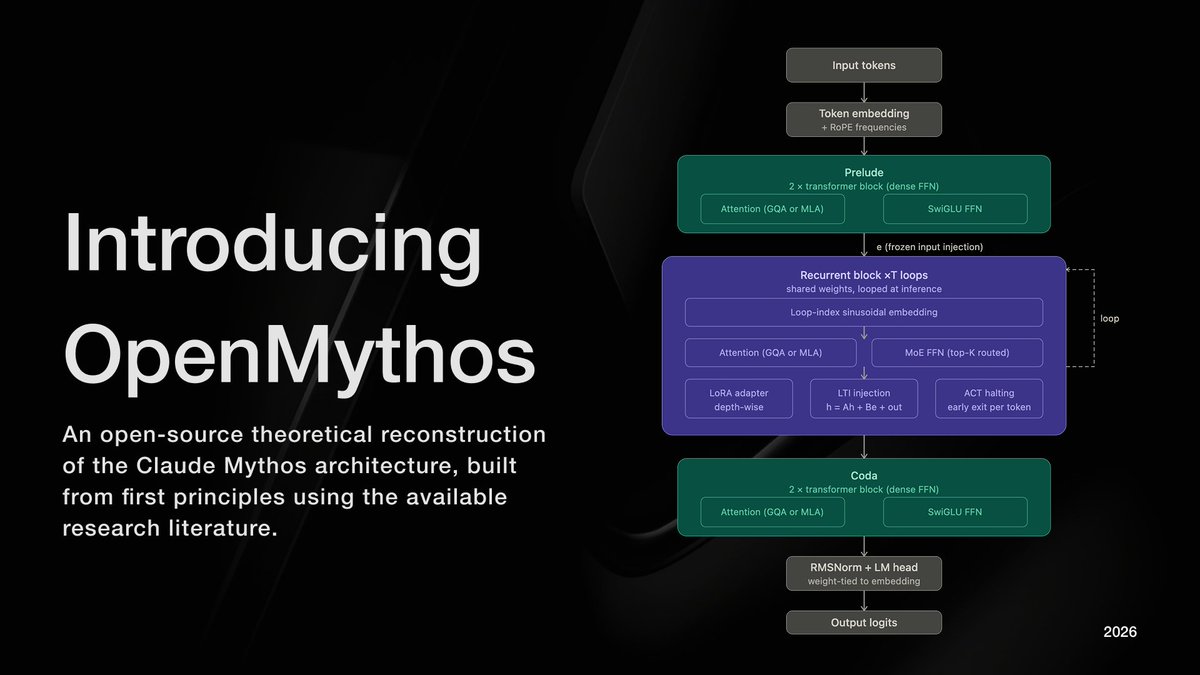
Introducing FlashDrive⚡
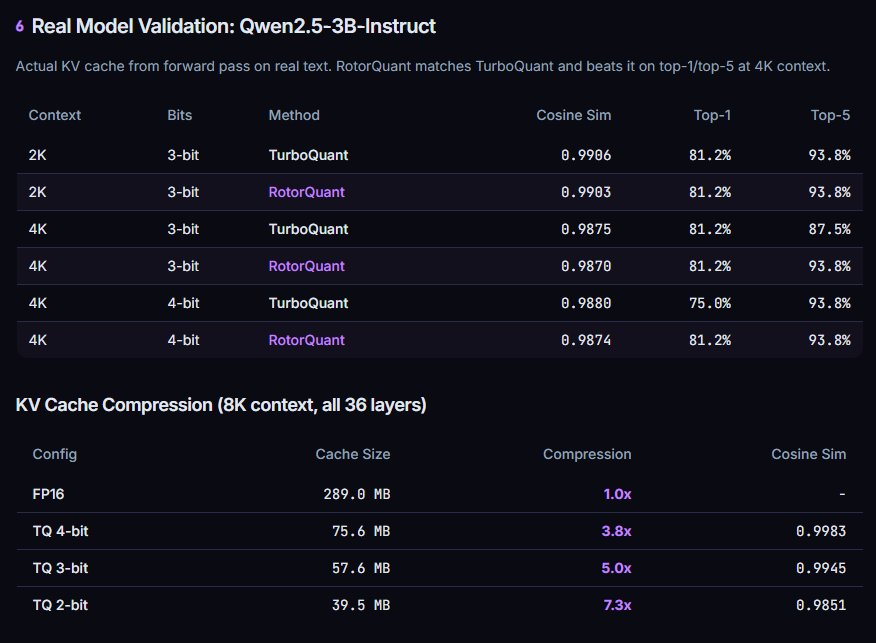
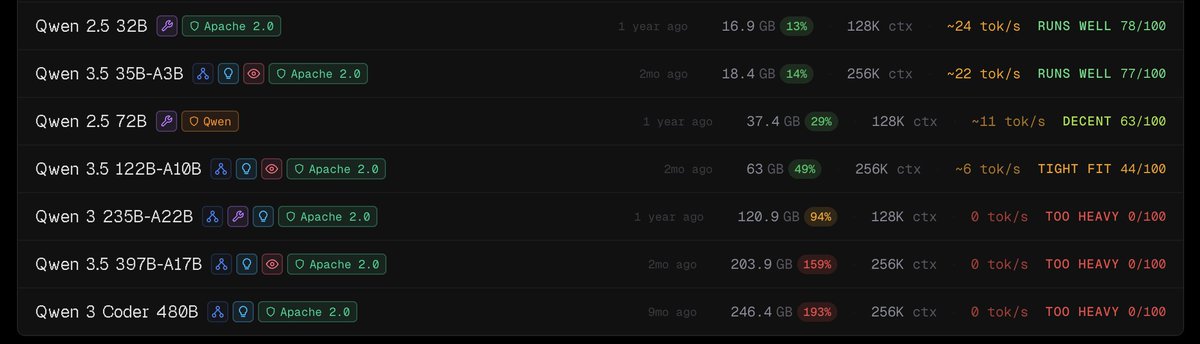
🚀 716 ms → 159 ms on RTX PRO 6000 (up to 5.7×)
✅ Zero accuracy loss
FlashDrive = streaming inference + DFlash speculative reasoning + ParoQuant W4A8
Real-time reasoning for autonomous driving is here!
z-lab.ai/projects/flash…
English