华丽 đã retweet
华丽
3.2K posts

华丽
@yeahmetro
Building: https://t.co/3choTT6mvk github: https://t.co/D58qpvOpUX Creator of unplugin-devpilot, vue-hook-optimizer, tour-master.
Tham gia Mart 2012
214 Đang theo dõi58 Người theo dõi

华丽 đã retweet


华丽 đã retweet

参考原版代码试了一下 web 版的樱花、红枫和雪松效果。并且加上了樱花飘落、红叶纷飞和漫天飞雪。虽然都是飘落,力学模型还是需要不同的。玩得挺开心~
Enzo Manuel Mangano@reactiive_
I've been playing with React Native WebGPU recently and it's really flipping my perspective on animations.
中文
华丽 đã retweet

Two days ago, Anthropic cut off third-party harnesses from using Claude subscriptions — not surprising. Three days ago, MiMo launched its Token Plan — a design I spent real time on, and what I believe is a serious attempt at getting compute allocation and agent harness development right. Putting these two things together, some thoughts:
1. Claude Code's subscription is a beautifully designed system for balanced compute allocation. My guess — it doesn't make money, possibly bleeds it, unless their API margins are 10-20x, which I doubt. I can't rigorously calculate the losses from third-party harnesses plugging in, but I've looked at OpenClaw's context management up close — it's bad. Within a single user query, it fires off rounds of low-value tool calls as separate API requests, each carrying a long context window (often >100K tokens) — wasteful even with cache hits, and in extreme cases driving up cache miss rates for other queries. The actual request count per query ends up several times higher than Claude Code's own framework. Translated to API pricing, the real cost is probably tens of times the subscription price. That's not a gap — that's a crater.
2. Third-party harnesses like OpenClaw/OpenCode can still call Claude via API — they just can't ride on subscriptions anymore. Short term, these agent users will feel the pain, costs jumping easily tens of times. But that pressure is exactly what pushes these harnesses to improve context management, maximize prompt cache hit rates to reuse processed context, cut wasteful token burn. Pain eventually converts to engineering discipline.
3. I'd urge LLM companies not to blindly race to the bottom on pricing before figuring out how to price a coding plan without hemorrhaging money. Selling tokens dirt cheap while leaving the door wide open to third-party harnesses looks nice to users, but it's a trap — the same trap Anthropic just walked out of. The deeper problem: if users burn their attention on low-quality agent harnesses, highly unstable and slow inference services, and models downgraded to cut costs, only to find they still can't get anything done — that's not a healthy cycle for user experience or retention.
4. On MiMo Token Plan — it supports third-party harnesses, billed by token quota, same logic as Claude's newly launched extra usage packages. Because what we're going for is long-term stable delivery of high-quality models and services — not getting you to impulse-pay and then abandon ship.
The bigger picture: global compute capacity can't keep up with the token demand agents are creating. The real way forward isn't cheaper tokens — it's co-evolution. "More token-efficient agent harnesses" × "more powerful and efficient models." Anthropic's move, whether they intended it or not, is pushing the entire ecosystem — open source and closed source alike — in that direction. That's probably a good thing. The Agent era doesn't belong to whoever burns the most compute. It belongs to whoever uses it wisely.
English
华丽 đã retweet



华丽 đã retweet


共识比工程更重要。
在还没有形成共识情况下面就开展全剧治理工作,做得好做得不好都不好。看你的心态还没有为这个事情做好一杆到底得准备,那就需要外部支持(TL、架构师等等)。
没有共识和支持之前,技术债务是敌人,合作伙伴很可能也是敌人。
周尔复@cholf5
最近公司发生一件极恶心的事,让我后悔来这家公司了。 我们项目以前的 Makefile 写的很长,逻辑越堆越多,已经没法维护。并且每次 make 都是全量编译,完全不用上增量编译,结果每次 make 都是10几分钟。我实在看不下去就让 CC 用 Python 重写了一版,加了增量编译支持。就这么放了三个月没敢合到主干,一直小圈子内灰度。 结果后来给我下个新需求,要往 Makefile 里加功能,我实在不想维护两套了,就跟领导说这两个版本二选一,实在不行就把 v2 删掉吧。他说别啊,他一直用,感觉增量编译速度很快。我说如果用 v2 就把 v1 删掉,并把 v2 转正。他说转正吧。 我当时的想法是,转正就转正,以后遇到问题,大家会一起改,这是一个共建的东西。结果转正后,这个 Makefile 就成我的专属,所有人遇到问题都来找我,还说:你改的你就负责到底。 我说这个东西是共建的,你给我我也是让 CC 改,这代码我不比你熟悉多少。你有跟我说的功夫给 CC 说早都改完了。 结果人家偏不(因为都不愿意接锅),这就成了我一个人的锅了。 这件事深刻的教育我们,不要打黑工,不要瞎优化,看到项目里的任何熵,在没有上级明确下单让你干之前,不要自作主张的干,干了就是你的,你就负责到底。
中文
华丽 đã retweet

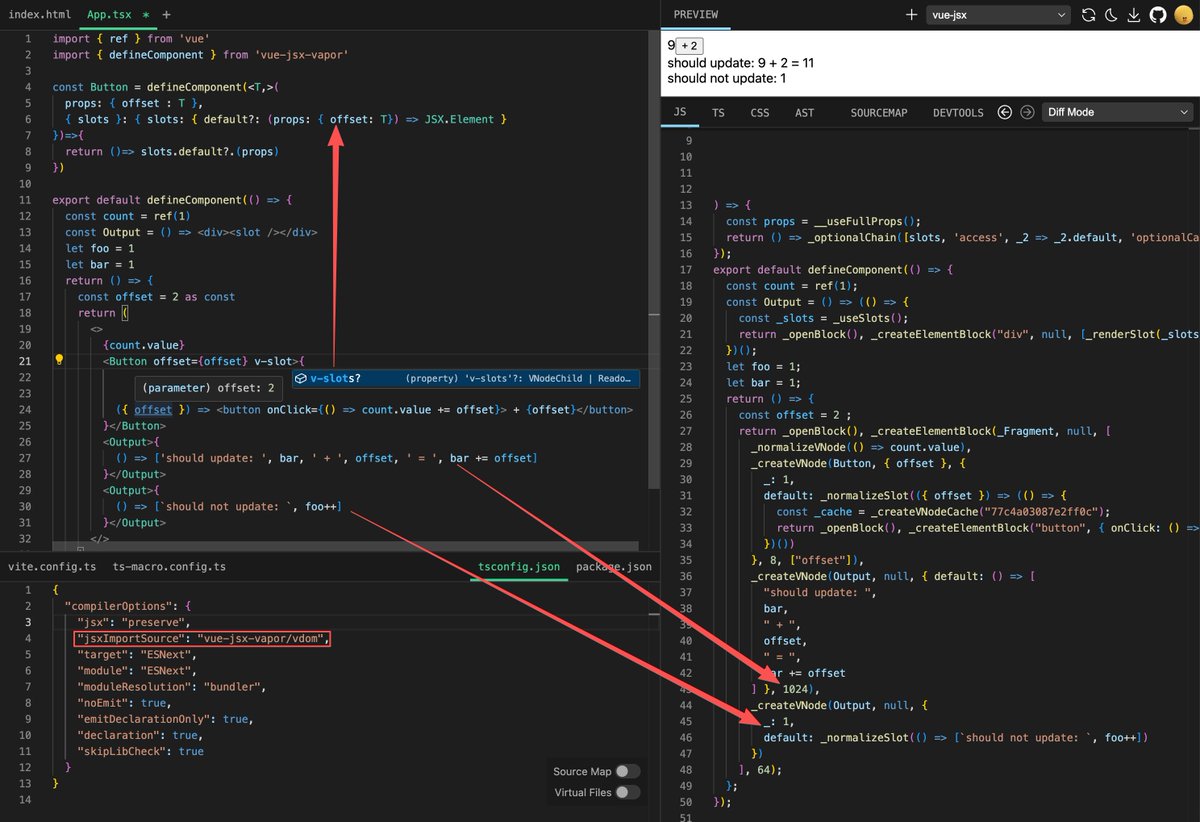
Introducing vue-jsx-vapor 3.2.9
1. Natively supports automatic type inference for JSX children. Since it uses `v-slots` instead of the `children` prop for type inference (#children-type-checking" target="_blank" rel="nofollow noopener">typescriptlang.org/docs/handbook/…), vue-jsx-vapor provides `defineComponent` and `defineVaporComponent` API to automatically add the `v-slots` prop type. You can also define it manually.
2. The compiler optimizations in vue-jsx-compiler now support both Object and Functional slots to reduce unnecessary updates.
repl.zmjs.dev/zhiyuanzmj/jsx…
English
华丽 đã retweet


华丽 đã retweet

The @vuejs community is amazing. It’s only a week out and we are releasing VueLynx v0.3.0:
- v-bind() in <style> @KealanAU
- v-model for input/textarea @jynxbt
- Volar supports @FliPPeDround
Try it out: vue.lynxjs.org
English
华丽 đã retweet

阿波罗拍的这张就是地球的亮面。阿尔忒弥斯这张暗面照片,在阿波罗时代根本拍不出来,光线太暗弱了。
Andy Saunders - Apollo Remastered@AndySaunders_1
Left - Apollo 17, 1972 Right - Artemis II, 2026 Two photographs taken by one of us, of all of us, over half a century apart. What's changed?
中文
华丽 đã retweet


华丽 đã retweet

Leaving Earth orbit, ✅. Next up: Finalizing the Moon observation plan.
Artemis II is both a test flight and a science mission. Astronauts, flight controllers, & science teams are working together to squeeze as much knowledge as possible out of the crew’s lunar flyby. ⬇️ (1/6)
English
华丽 đã retweet



华丽 đã retweet

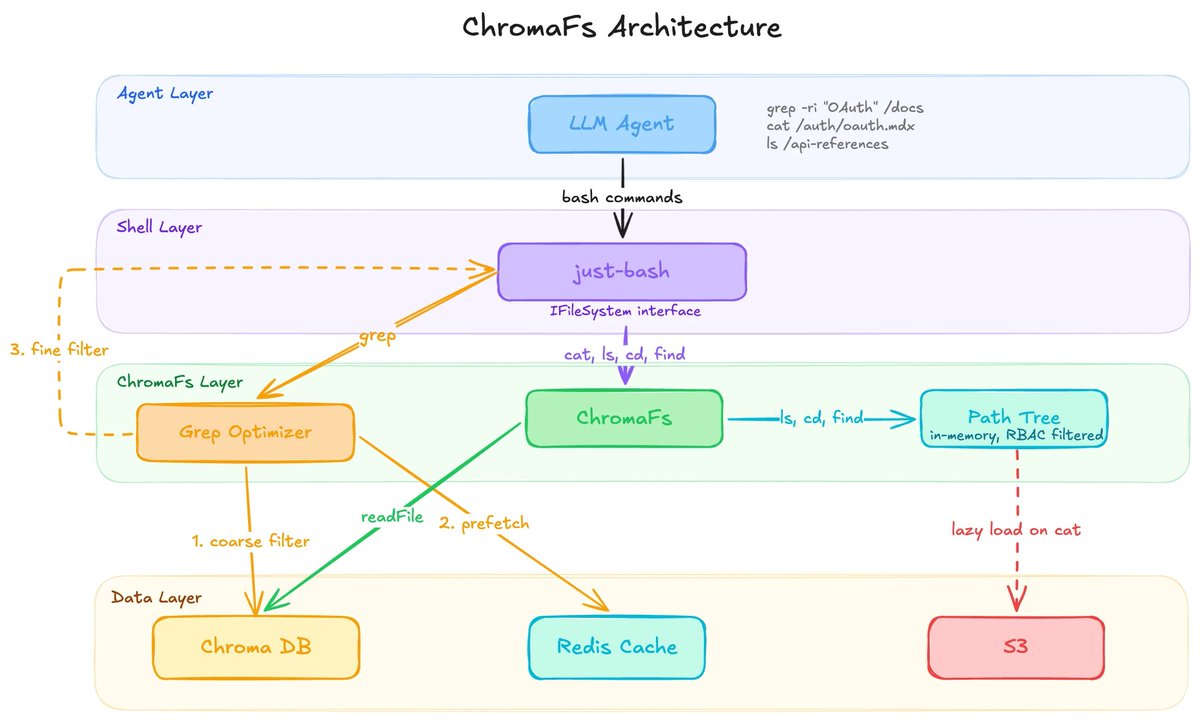
文档平台 Mintlify 发了一篇工程博客,讲了一件挺有意思的事:他们给自家 AI 文档助手造了一套假的文件系统,叫 ChromaFs,让 AI 以为自己在用 grep、cat、ls 这些命令浏览文件,实际上每个命令都被拦截、翻译成了数据库查询。
效果很直接:会话启动时间从原来沙箱方案的 46 秒降到 100 毫秒,每次对话的边际计算成本几乎为零。
Mintlify 之前的方案是标准的 RAG 流程:把文档切块、向量化、存进 Chroma 数据库,用户提问时检索最相关的片段喂给大模型。问题是,如果答案分散在好几个页面里,或者用户要的是某段精确的代码语法,向量检索经常找不对。
他们想让 AI 像开发者翻代码一样翻文档,而不是靠语义相似度碰运气。
核心思路是:AI 不需要真的操作系统,只需要一个足够逼真的幻觉。
ChromaFs 基于 Vercel Labs 的开源项目 just-bash(一个用 TypeScript 重写的 bash 子集)构建。just-bash 提供了可插拔的文件系统接口,负责解析命令和管道逻辑,ChromaFs 则把所有底层文件操作翻译成 Chroma 数据库查询。每个文档页面变成一个"文件",每个章节变成一个"目录",AI 就可以用 grep 搜精确字符串、用 cat 读整页内容、用 find 遍历结构。
之前用真沙箱的方案(给每个用户起一个微型虚拟机),按 Mintlify 月均 85 万次对话的量算,一年光计算成本就要 7 万美元以上。ChromaFs 复用了已有的数据库基础设施,这笔钱省了。
grep 是最难虚拟化的命令。如果真让它逐文件扫描,走网络 IO 会很慢。ChromaFs 的做法是先把 grep 的参数解析出来,用 Chroma 的元数据查询做粗筛,找出可能命中的文件批量预取到缓存里,再让 just-bash 在内存中做精确匹配。
权限控制也很优雅:初始化时根据用户身份裁剪文件树,没权限的路径直接从树里删掉,AI 连路径都看不到,不存在越权风险。
所有写操作一律返回"只读文件系统"错误,AI 能随便看但改不了任何东西,整个系统无状态,不用担心清理和数据污染。
这篇文章在 Hacker News 上引发了一个有意思的讨论。好几位开发者指出,大家不知不觉中把 RAG(检索增强生成)等同于了向量搜索,但 RAG 里的 R 是 Retrieval(检索),本来可以是任何方式:全文搜索、SQL 查询、甚至翻电话簿。把 RAG 绑死在向量数据库上,是早期技术路径的惯性。
有人解释了这种惯性的由来:RAG 概念流行的时候,大模型还不太会用工具,多轮搜索和纠错能力也差,向量检索是当时最省事的方案。现在模型的工具调用和推理能力上来了,让 AI 自己决定用什么方式找信息,反而比预设一条检索管道更灵活。
也有人提出了务实的质疑:Mintlify 的场景是结构化的技术文档,天然适合文件系统隐喻,但如果是组织内部那种乱七八糟、没有层级结构的知识库,这套方案未必好使。
这个方向和 Claude Code 的做法有相通之处:与其把所有信息预检索好喂给模型,不如给模型一套探索工具,让它自己决定看什么、怎么找。对于正在搭建 AI 文档助手或内部知识库的开发者来说,Mintlify 的这套方案提供了一个向量检索之外的选项,尤其适合文档结构清晰、对精确匹配要求高的场景。
Dens Sumesh@densumesh
中文
华丽 đã retweet

新疆塔什库尔干塔吉克自治县,平均海拔超4000米的帕米尔高原上,通过改良土壤、智能温控、精准授粉等技术攻关,在荒漠化严重的土壤里通过温室大棚种出了车厘子。#新疆
中文
华丽 đã retweet


华丽 đã retweet

MSA 的 Inference 代码准时开源了🫡
EverMind@evermind
A few weeks ago we published our Memory Sparse Attention paper, a new way to give AI models long-term memory that actually works. Today's LLMs/Agents forget. They can only hold so much context before things start falling apart. We built a system that lets a model remember up to 100 million tokens, the length of about a thousand books, and still find the right answer with less than 9% performance loss. On several benchmarks, our 4-billion parameter model even beats RAG systems built on models 58× its size. The idea? Instead of searching a separate database and hoping the right info comes back (that's how RAG works), we built the memory directly into how the model thinks. It learns what to remember and what to ignore, end to end, no separate retrieval pipeline needed. The response to the paper blew us away. Researchers and engineers everywhere asking the same thing: "When can we see the code?" So we got to work, cleaned up the inference code, documented it, and made it ready for the community to dig in. You asked for it. We open-sourced it. github.com/EverMind-AI/MSA
中文
华丽 đã retweet

#Norganic Basic バランシングエッセンスミルクのCMに出演しました。
なんと今回の撮影にあたって「荒野に立つ」のMVを撮影チームの皆様が見てくださったんだと教えてくれました。
私にとってとても大切な曲なので、お話をいただいた時もとても嬉しかったです。
インタビュー動画なども公開されているので、よければ見てね🌹🌱 のん
日本語