置顶推文

🚀 New from Cleanlab: Expert Guidance
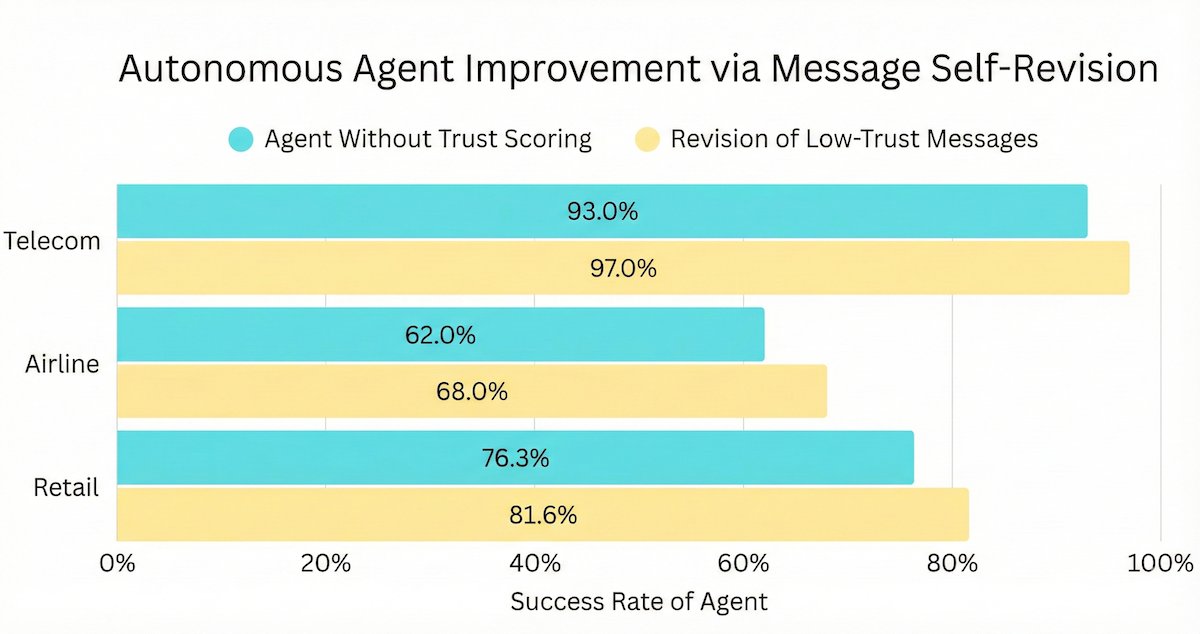
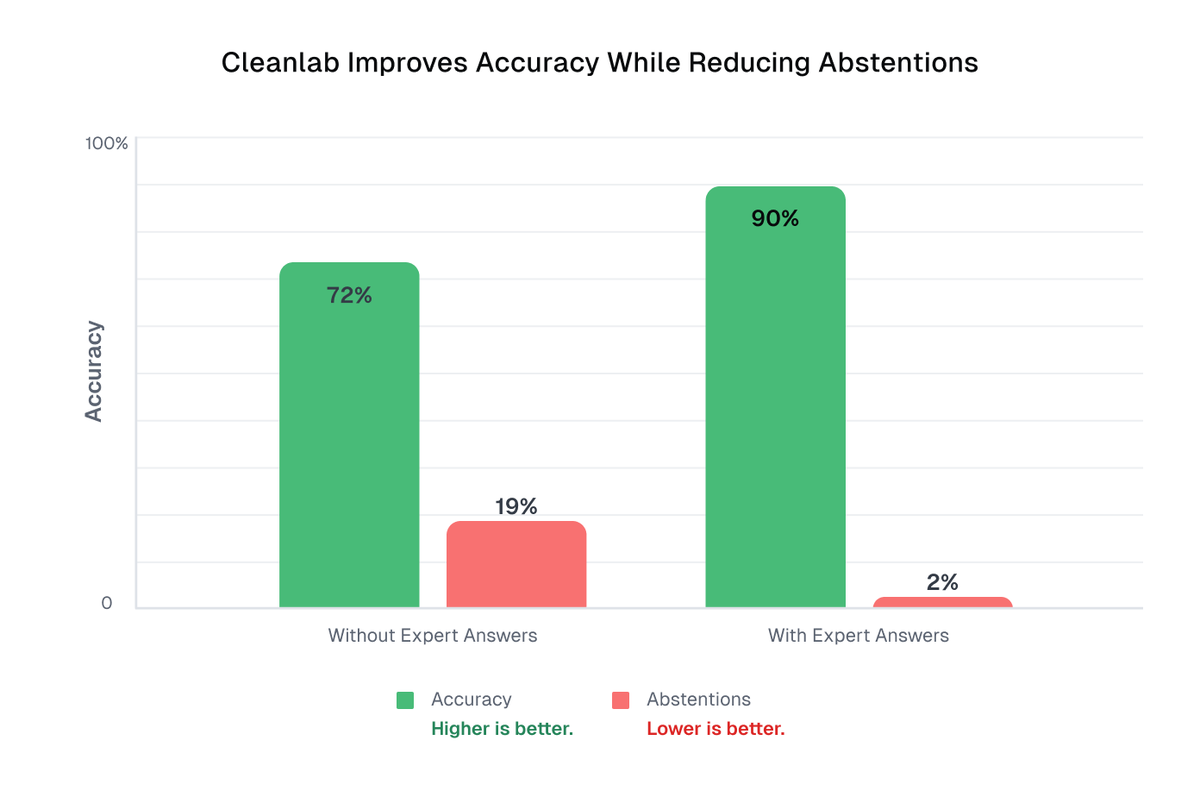
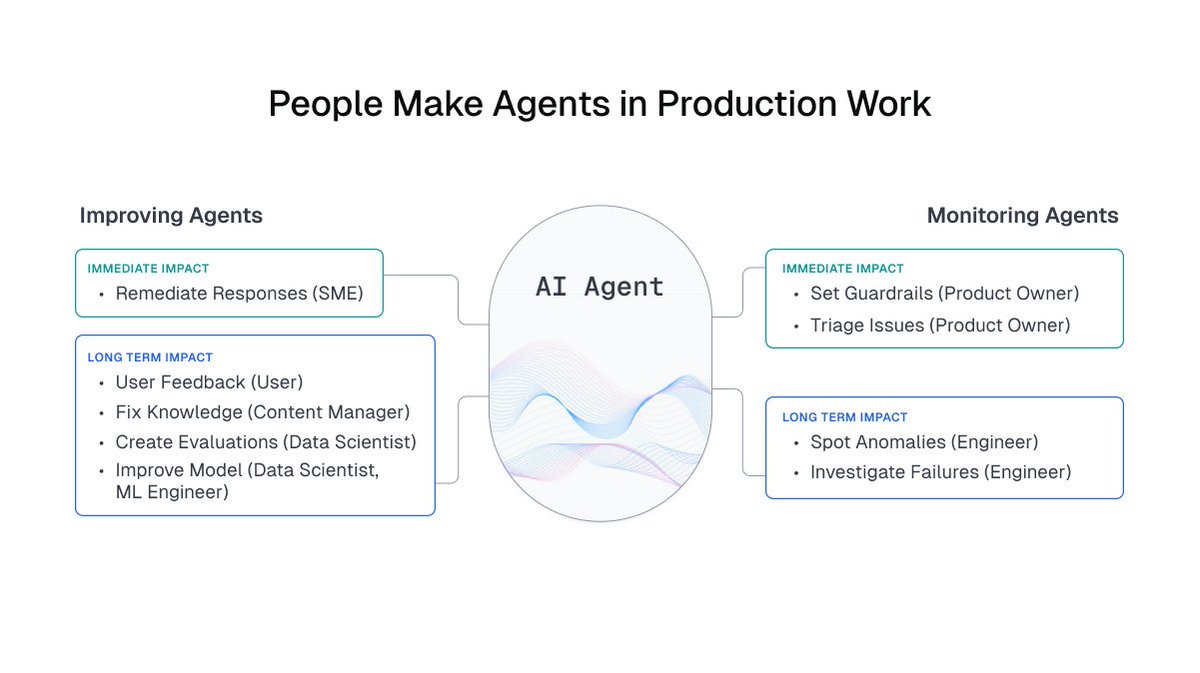
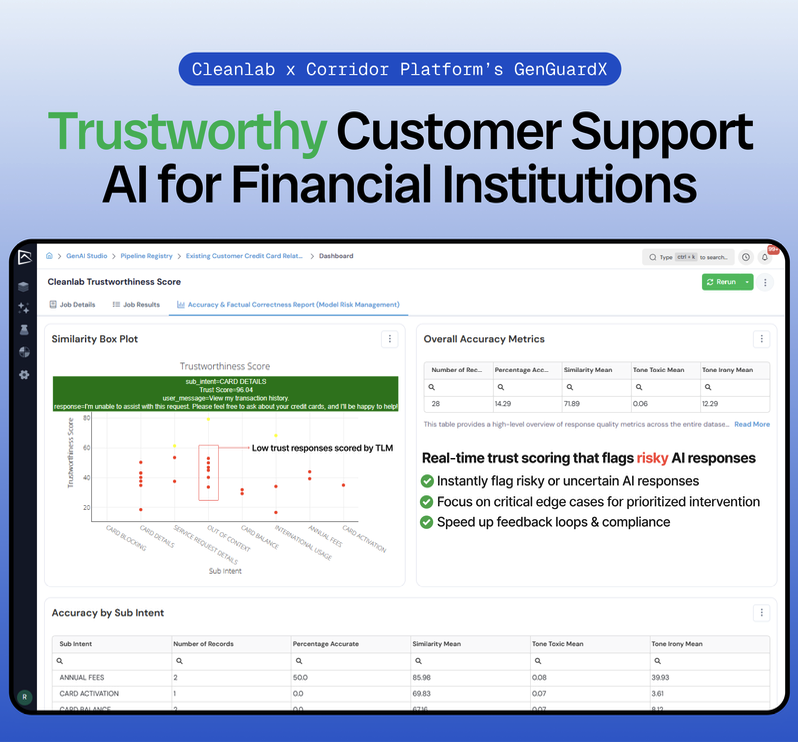
AI agents running multi-step workflows can fail in tiny, trust-breaking ways.
Expert Guidance lets teams fix these behaviors with simple human feedback, instantly.
✈️In one airline workflow: 76% → 90% after only 13 guidance entries.
English