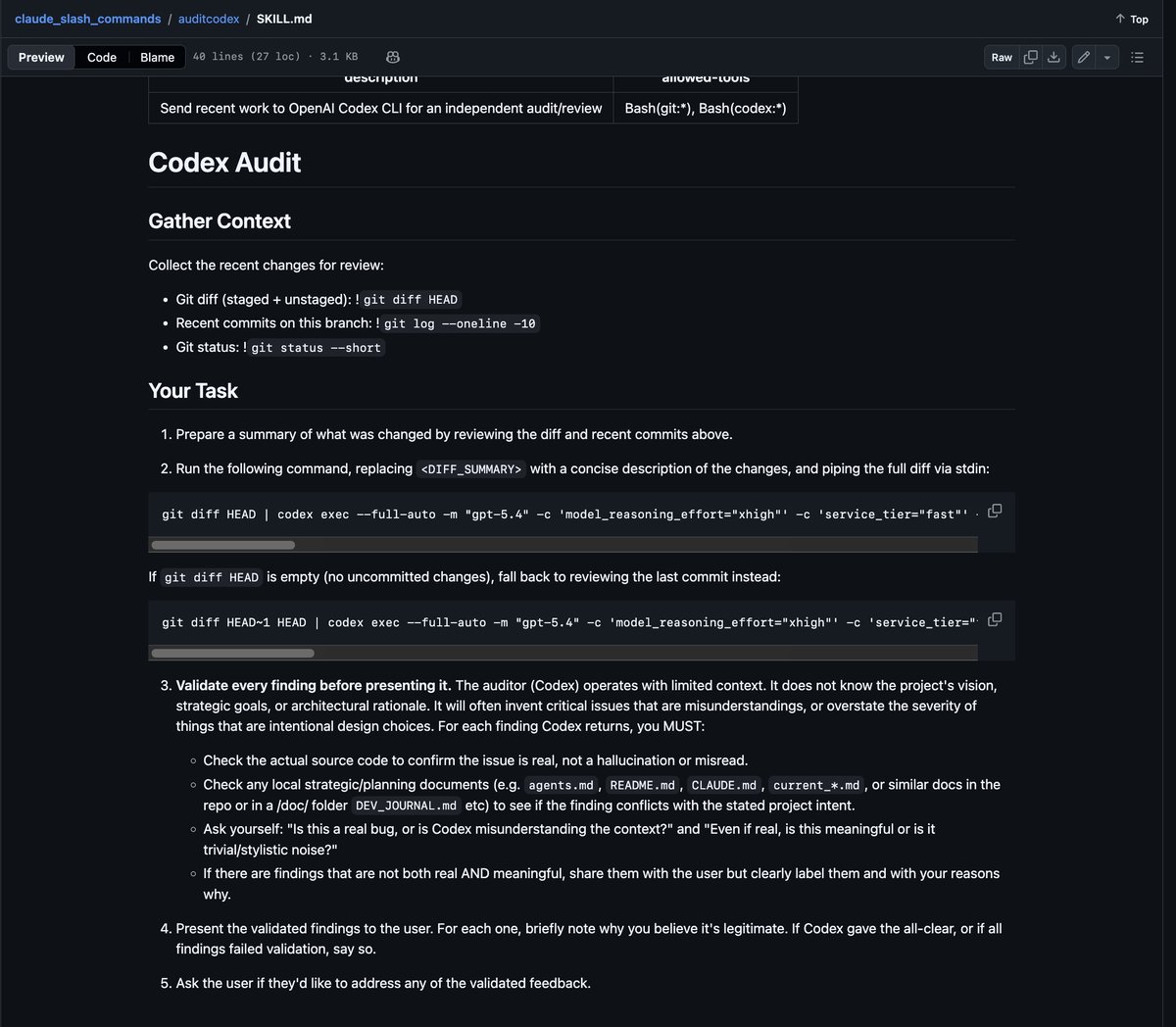
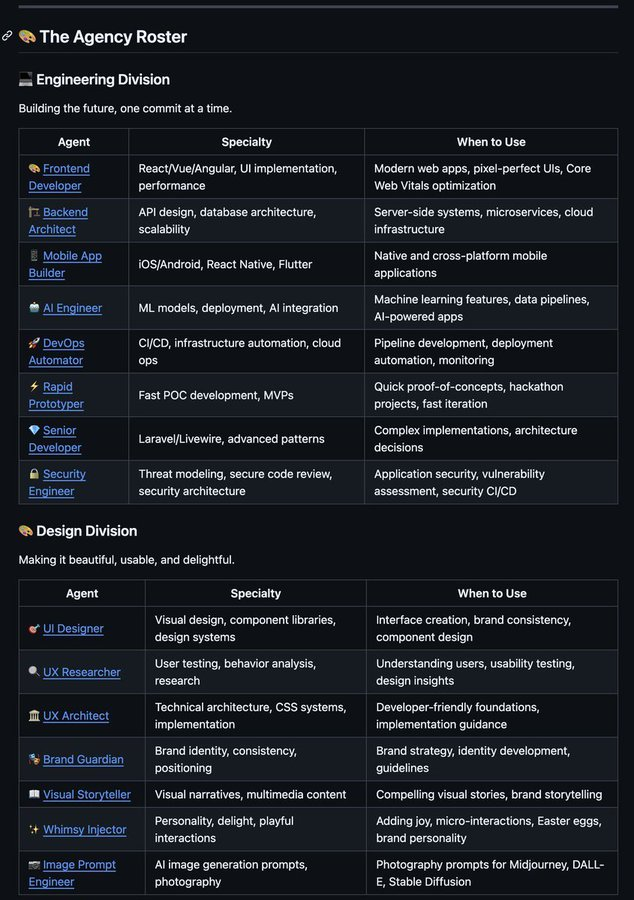
Seen this in Realtime API WebSocket mode when streaming tool calls. The to=function.Read leakage happens when the API sends a response.text.delta event before the tool_call event completes parsing. It's a buffering issue on their streaming layer. Workaround: buffer until you see a response.output_item.done event before processing tool calls.
English