Pradyumna
2.2K posts




Check out my system design articles here
pradyumnachippigiri.substack.com
English

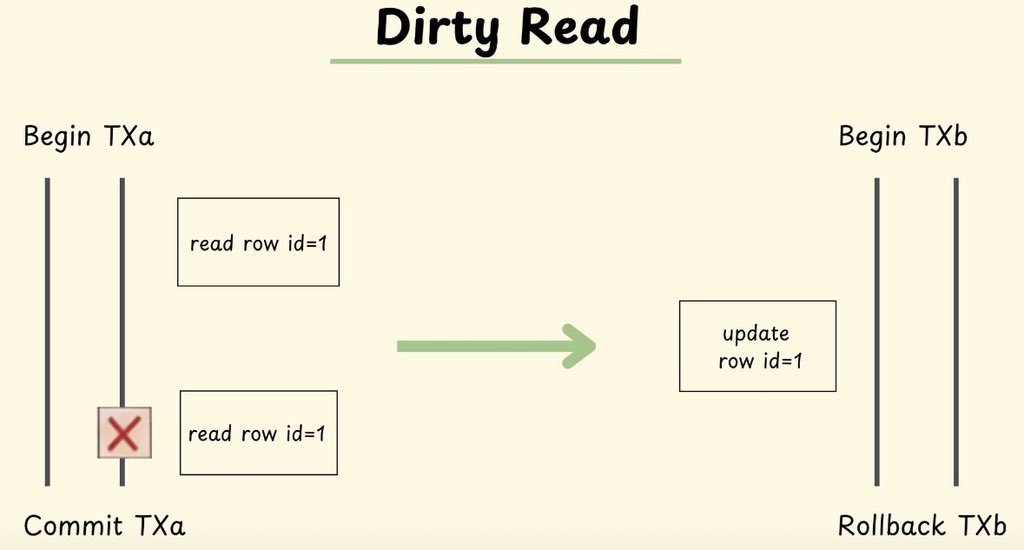
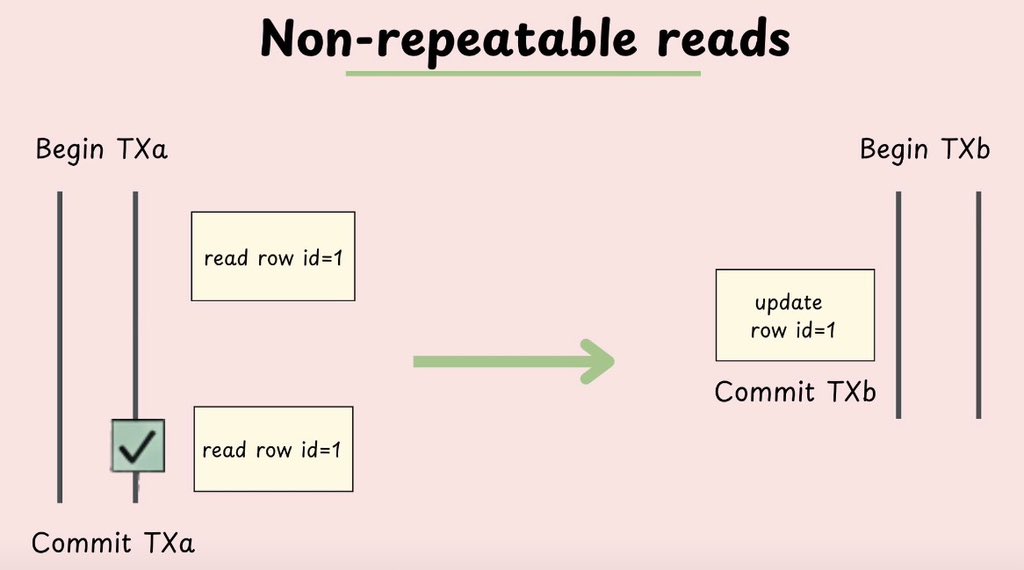
Checkout my new article on pessimistic vs optimistic locking
pradyumnachippigiri.substack.com/p/concurrency-…

English
Check out my new post on Optimistic locking vs pessimistic locking in databases.
Pretty nice way to deal with concurrent transactions. Hence, worth a read.
pradyumnachippigiri.substack.com
English
@sunnykgupta @JioHotstar @cricketworldcup @ICC @ESPNcricinfo @Sports Would love to be a part of such a scalable and performant infra
English

Let that sink in... a platform built from the ground up just streamed over 72.5MN fans at the same time.
With personalized ads, real‑time commentary, rich match analytics and a tidal wave of emotions all holding steady.
A double win for the @JioHotstar engineering and product teams... we broke global streaming records and then stayed on to celebrate India lifting the T20 World Cup trophy together.

English

@furiouswhopper @0xlelouch_ I mean everything is an engineer decision based on the scale, complexity, cost efficiency and how much engineering skill is needed. If it’s going to improve a huge systems performance then why not just do it.
For smaller systems yes this bloom filters isn’t a good one.
English

@codeslayerprads @0xlelouch_ Or let the db do db things and everything works absolutely fine. It should be criminal to over engineer like this
English

Typed a Gmail username once and the UI instantly said: “Username already taken.”
I asked an ex-Staff Google engineer the same problem (he was director of engineering in a startup i worked at), “You’re not doing an Elasticsearch query on every keypress, right?”
He laughed. “No. That’d be a crime.”
My classy approach:
1. Keep an in-memory trie of reserved usernames.
2. Update it async (delta pushes), not per keystroke.
3. UI checks locally in O(k) where k = username length.
Numbers (why this is feasible):
1. Assume 2B usernames, avg length 10 chars.
2. Raw chars = 2B × 10 = 20B chars.
3. Even if you store 1 byte/char (not true in a trie, but baseline) that’s ~20GB just for characters.
4. A trie is about prefix sharing, so common prefixes collapse hard. Real memory is “nodes + edges”, not “strings”.
5. If we model ~1 node per char worst-case: ~20B nodes.
- If a node is 8 bytes (tight packed arrays, bitsets, offset indices; no pointers), worst-case is 160GB.
- With prefix sharing, you can easily cut multiples of that depending on distribution (gmail-like usernames are not random).
6. Shard by first 2 chars (36 possible: a-z, 0-9). 36² = 1296 shards.
- Worst-case per shard: 160GB / 1296 ≈ 123MB.
- Suddenly “instant check” fits in memory per front-end pod or edge POP.
Yes, you can also do it with WebSockets:
1. Client streams “candidate username” events.
2. Server replies with availability.
3. Works fine, but now you’ve built a hot, stateful, low-latency service for… a UI hint.
Most people will ship:
1. Elasticsearch prefix search.
2. Debounce 150ms.
3. Cache a bit.
4. Pray at peak signup traffic.
And it works.
But the trie approach is the kind of solution where the UI feels like magic tbh and it's something novel that i thought of.
Things are just different at google scale.
SumitM@SumitM_X
As a developer, Have you ever wondered : You type a Gmail username and UI instantly shows "Username already taken"... There are millions of users globally How is this check so fast?
English
@arpit_bhayani The office looks like some fitness center at the first glance 😂
English

Joined Razorpay as Principal Engineer II :)
From being a long-time customer to now building parts of the system - it's a full circle. Fintech is a new territory for me - time to get under the hood of how money actually moves.
New domain, same guarantees - availability, correctness, performance - just with real money on the line.

English
@striver_79 @takeUforward_ Have you come across the channel called “Hello interview” pretty solid content.
English

To my surprise, there still isn’t a single really solid end-to-end HLD playlist on YouTube.
For DSA, you will find plenty. For HLD, not really something that covers the journey properly from basics to an advanced level.
Possible reasons, at least from what I feel:
- Many people who genuinely have strong HLD experience are working full-time, and there can be a conflict of interest with their employers.
- A lot of good HLD content is kept behind a paywall. And apart from a few exceptions, much of that content is often shaped heavily by the specific domain the creator has worked in.
- It is also rare for someone at that stage of life and career to leave a stable income unless YouTube is able to provide meaningful stability in return. With experience often comes family responsibility, and stability starts mattering a lot more.
- And in many other cases, the teaching feels a bit shallow, more like knowledge collected from blogs, articles, LLM's, and existing videos, rather than from hands-on experience building or scaling real systems.
I could be wrong, but this is honestly how it looks to me from the outside as I am planning it out.
English
Pradyumna 已转推