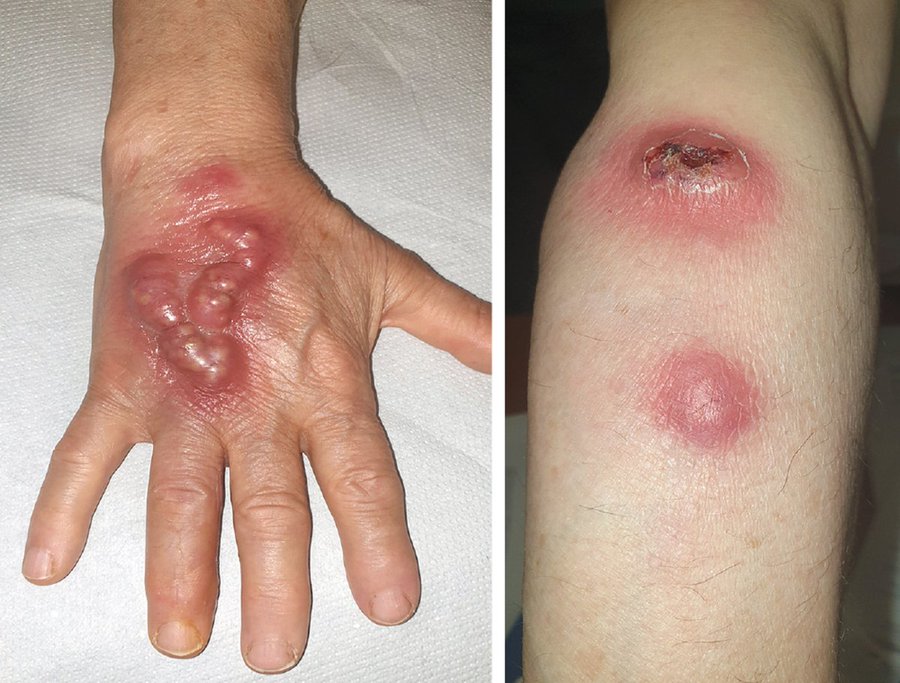
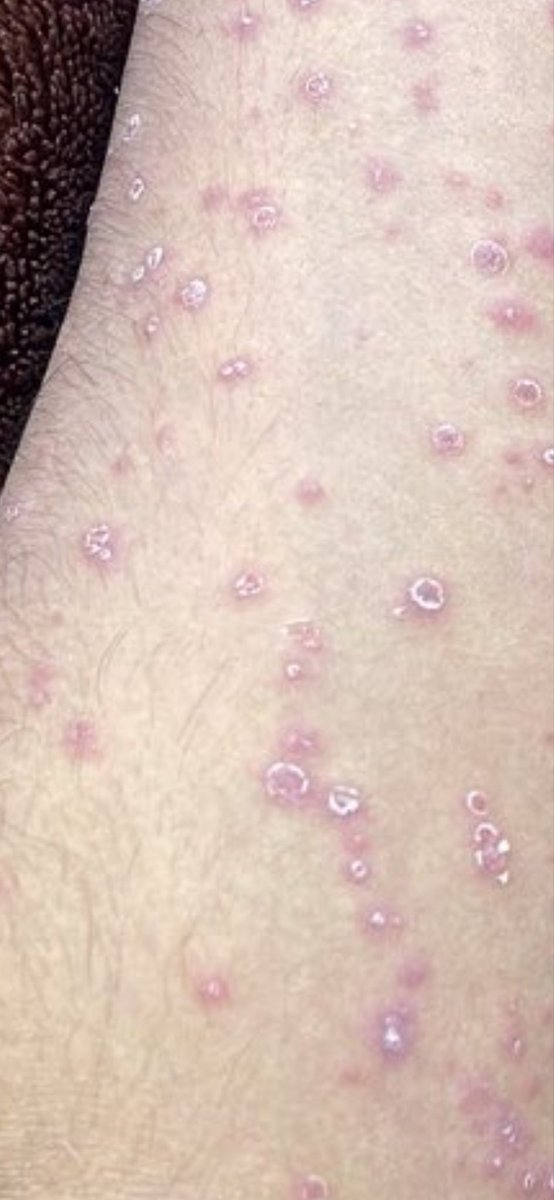
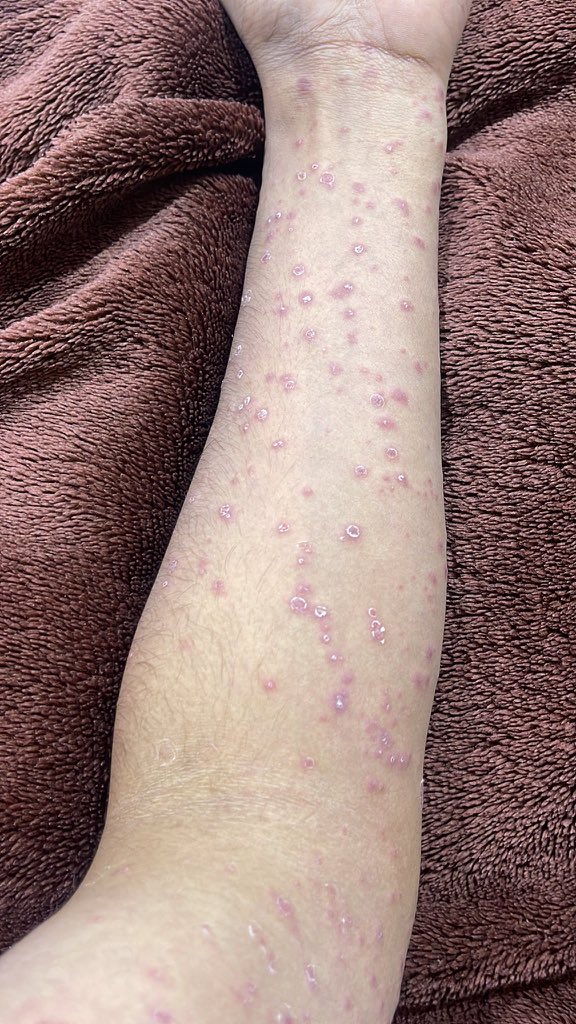
•Clinical presentation: Painful erythematous bullous/nodular lesions on the right hand with proximal nodules along the forearm, showing sporotrichoid (lymphocutaneous) spread after likely traumatic soil/gardening inoculation over 10 days.
•Microbiology: Nocardia causes this pattern; aspiration shows filamentous, gram-positive, branching, weakly acid-fast rods (beaded on Gram stain), consistent with an aerobic soil organism.
•Distinguishes from: Actinomyces is branching but not acid-fast and anaerobic; fungi and mycobacteria differ by stain/growth features.
•Confirmation: Culture confirms the diagnosis. This matches an NEJM Image Challenge case of sporotrichoid nodular lymphangitis due to Nocardia.
English