𝕱𝖔𝖗𝕷𝖔𝖔𝖕@forloopcodes
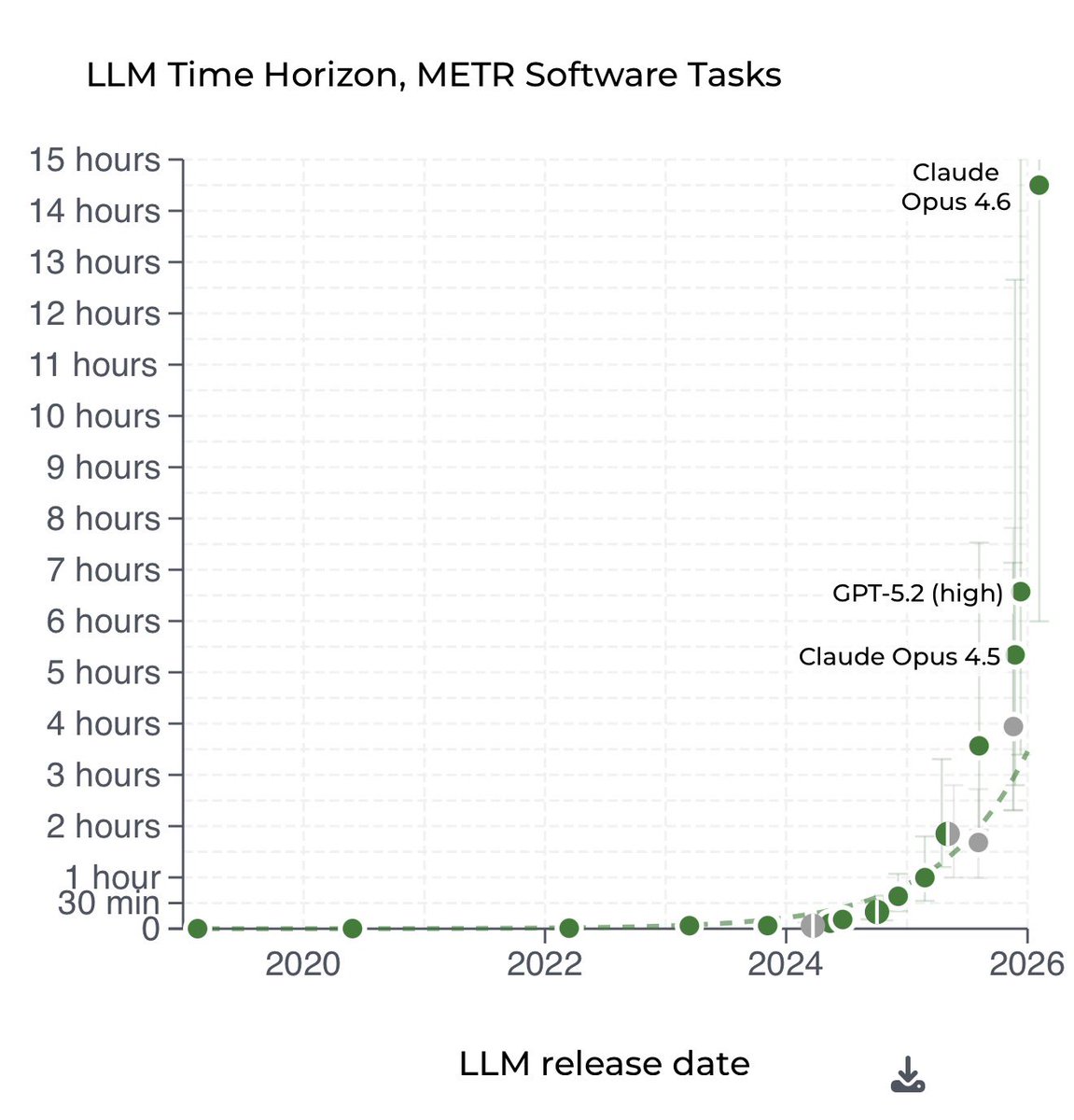
2026 ai bubble is peaking itself right now: someone just dropped a new benchmark on claude skills and the result of their paper is actually insane
the paper explicitly states smaller models with skills beat larger models without them
a smaller model like claude 4.5 haiku equipped with high quality skills smokes a raw state of the art opus 4.5 model by about 6 percent (27.7 vs 22.0)
imagine getting sota level performance from a free model, its basically cheating, you just have to manually spoonfeed it a basic markdown file explaining how to do its job
all of you opus guys are dumb, you can literally spam haiku with skills and get things shipped in 5x lesser time and 0 cost
even wilder thing is that codex gpt 5.2 fails on the pareto frontier. codex burned massive compute and costs, just to get completely mogged by gemini 3 flash hitting maximum performance at a fraction of cash
i can believe skill engineering is now a valid, mathematically proven substitute for compute
over that, it says self generated skills provide zero benefit on average and show negative deltas on 16/84 tasks. if you give an agent more than 3 skills at once, it bloats its context and completely fails