@hamen The half-and-half phase is expensive.
You keep translating every decision instead of learning the new constraints. Finishing forces the paradigm switch faster.
English
Boaz Hwang
338 posts

@BoazWith
Shipped 4 apps to App Store in a month. Self-taught, no CS degree. Built AI App Factory — native mobile apps with AI agents. Building in public.








Everyone is building AI agents. Almost no one is building the infrastructure to run them in production. That's where this comes in ↓ → AgentField (Agent-Field/agentfield) This is not another agent framework. It's Kubernetes for AI agents. A full control plane that turns your agents into real backend services: • Every agent = API endpoint • Callable from frontend, backend, cron, or other agents • Works with Python, Go, TypeScript • Supports 100+ models (OpenAI, Claude, Llama, etc.) But the real unlock is infra 👇 Instead of duct-taping tools, AgentField gives you: • Routing + coordination across agents • Async execution for long-running workflows • Built-in memory + workflows • Cryptographic identity for every agent • Full audit trail of every decision This solves the biggest problem in AI today: 👉 Agents work in demos 👉 They break in production AgentField treats agents like microservices: • Autoscaling • Observability (logs, metrics, tracing) • Secure inter-agent communication • Rolling deployments & versioning Translation: You stop writing glue code and start building autonomous systems. If you are serious about AI agents in production, this is the layer you have been missing. Try it: github.com/Agent-Field/ag… Follow for more breakdowns on AI infra, agents, and real-world systems. #AI #AIAgents #OpenSource #Kubernetes #Backend #Automation #LLM #DevTools #BuildInPublic


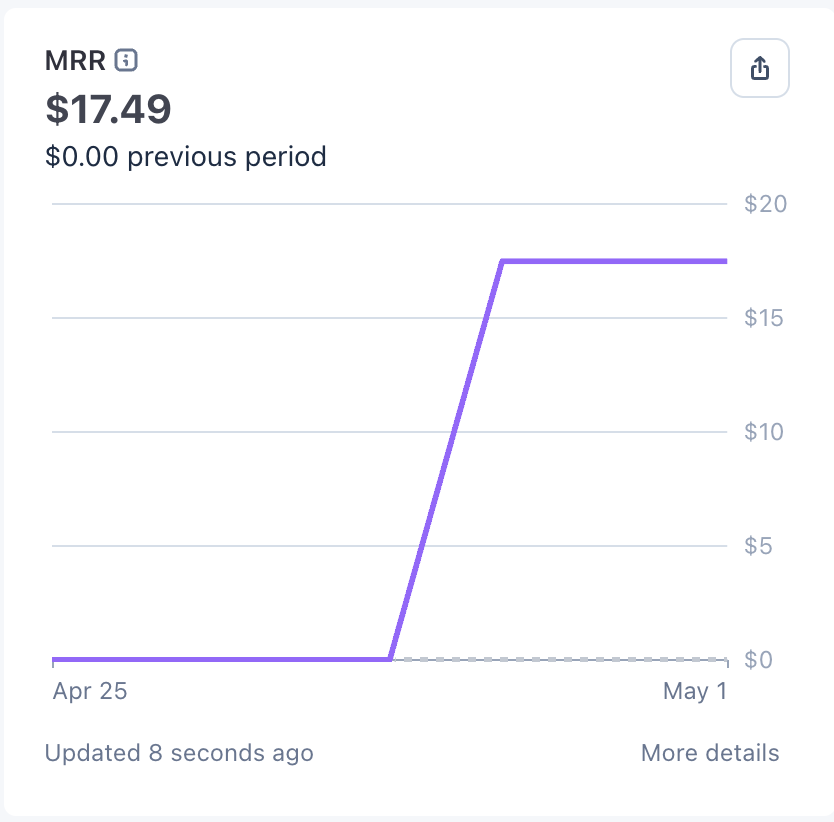
Day 8 of building in public. The goal is to get first paying users in May. Current progress: Users: 20(+0) Revenue: $0 MRR: $0 Getting new users and customers gets harder when you’re facing deadlines in life. Still waiting for update approval on CWS.