
MemoryLeak
257 posts
MemoryLeak
@ICSCRF
Co-CIO of a quant fund based in Beijing. Master of Computer Vision
Beijing انضم Nisan 2017
184 يتبع15 المتابعون



重新跑了<模型编程性能测试>,添加了 Minimax 2.7、Mimo V2 Pro、GPT 5.4 Mini 模型
结果在预料之中:coding-model-comparison.versun.me
⚠️ 防杠补丁:本次测试纯属娱乐,仅针对当前提示词和模型版本有效,博主无任何厂商立场

中文
@DAYJY8 @ChinaMacroFacts 其实严格说sonnet 4.5和opus4.6是两条线,现在开源模型接近或跨过了第一条(取决于你的任务和标准),所以其实已经开始一阶段爆发了。第二条相信也只是时间问题。
中文


我买了kimi、glm、minimax的年套餐,除了在openclaw里面让他们做做最routine的简报,查查简单数据、找找论文和研究报告外,几乎就一直放着,原因是相比claude和chatgpt越来越落后。
小米的模型我没兴趣试用,似乎在社区里反应非常好,小米的发展是否可以这么说,开源sota模型几乎没有任何护城河?
中文
@outofboundcats @scaling01 reasoning behavior very similar to glm5, but the tokenizer seems to be different🤔
English

@scaling01 "Hunter Alpha responds much slower, like half the tks/s" -> Hunter alpha is probably GLM Then may be GLM5-code ?
English

Hunter Alpha and Healer Alpha on OpenRouter:
- Hunter Alpha has Claude psychosis
- Healer Alpha says it's built by Xiaomi
- they are definitely chinese models
- Hunter Alpha responds much slower, like half the tks/s
- both models are completely SVG benchmaxxed
- both fail simple multiplication tasks and can't decode twice base64 encoded strings
probably a nothingburger
English

国内社媒已经在猜,Hunter Alpha 是 DeepSeek V4 。
大家觉得可能吗?
Peter Steinberger 🦞@steipete
New @openclaw beta bits are up! With Hunter🏹 Alpha (1M context!) and Healer🩹 Alpha FREE stealth models from @OpenRouter Also, GPT 5.4 and @Kimi_Moonshot Coding now are more reliable, and lots of fixes around ACP and message handling. github.com/openclaw/openc…
中文

Some personal thoughts about GLM and Z.ai. Thanks to @jrdothoughts for hosting this.
thesequence.substack.com/p/the-sequence…
The interview was conducted before the release of GLM-5, meaning some answers are already outdated. Keep learning and adapting to this crazy AI world.
English

中国外交部竟然连对哈梅内伊表示一点哀悼的意愿都没有,回想起10年前唯一一次会面的照片被伊朗官媒发出来引发国内议论,还找了不少官媒和自媒体做宣传找面子。
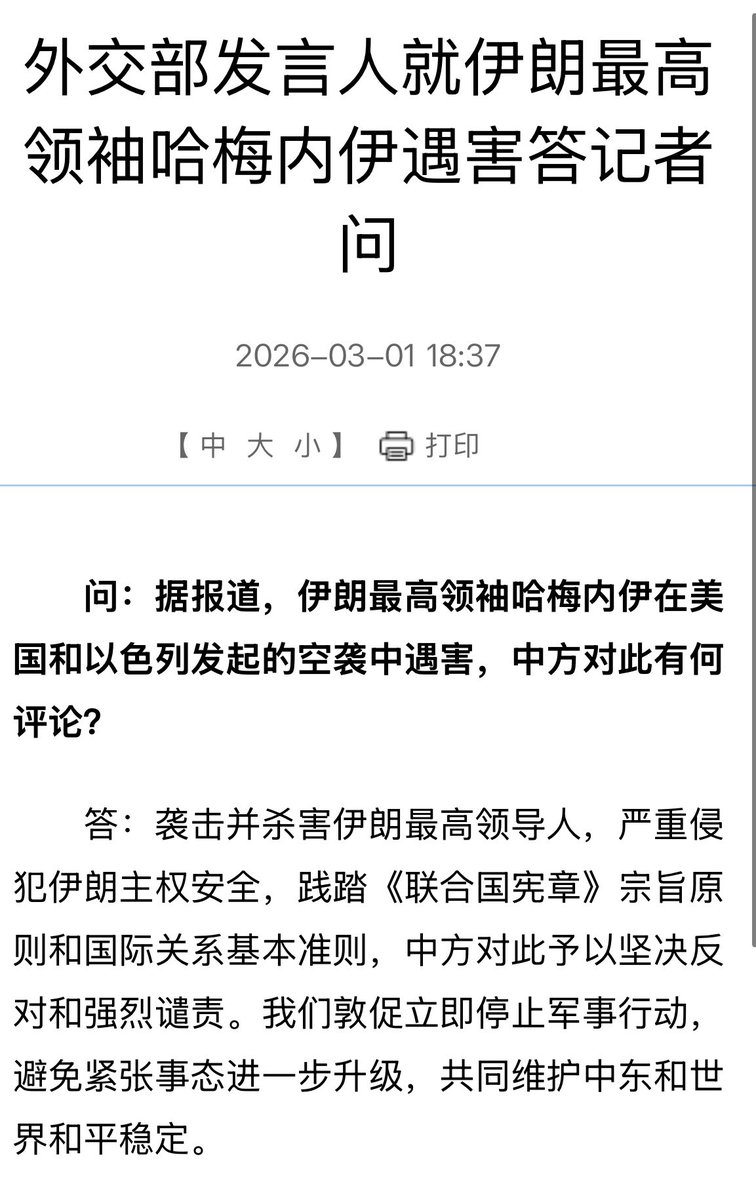

中文
Anthropic顶住Trump政府压力做了一个对全人类都很重要的决定,带动openai和gemini做出类似表态。
不知道未来会走向何方,但在现在,他们就是良心。
Anthropic@AnthropicAI
A statement from Anthropic CEO, Dario Amodei, on our discussions with the Department of War. anthropic.com/news/statement…
中文


中华人民共和国政府是中国的唯一合法代表,这句话是中共说的,不是我说的。
我说的是,中华民国有权利谋求统一大陆,中华人民共和国也有权利谋求统一台湾。
当前局面,是内战没打完的历史遗留问题。
台湾政权在老蒋时代,还念兹在兹要反攻大陆。你不能说你力量大的时候,就可以想要统一我,你力量小的时候,就说:我不统一你了,但你也别统一我。
难不成“统一对方”的权利只有你拥有,你想统一就统一,你不想统一就不统一?
你知不知道什么是内战?内战就是我打你,你打我。不存在你想打就打,你不想打就不打。你得问问对方答不答应。
两岸至今没有签署停战协议,现在只是中场休息时间。
不想打,那只有两种可能,要么台湾接受被大陆和平统一;要么台湾说服大陆被中华民国和平统一。台湾政权如果有本事实现第二种可能,我给他点赞。
Xi n xin@dx23th
@jxzdmzw 你不是說,你現在是唯一代表嗎?😂
中文


@leonlyzhou @pangyusio 拉倒吧,我严重怀疑那破模型就是GLM-4.x 后训练出来的,犯傻的方式都如出一辙,还贵的要死,不知道哪来的自信
中文

@pangyusio cusor自家的模型composer 1.5又稳又便宜。 现在它家也支持sub-agent,CLI,cloud agent。我是用了一圈又回到了cursor。
中文


@karminski3 差的H200也是国产的很多倍,99分比一百是差,但比20分都没有的还是高一大截,本质上还是deepseek被国内显卡厂商骗了,同时自己也有股莫名的爱国情怀,以为支持国产显卡就是爱国
中文

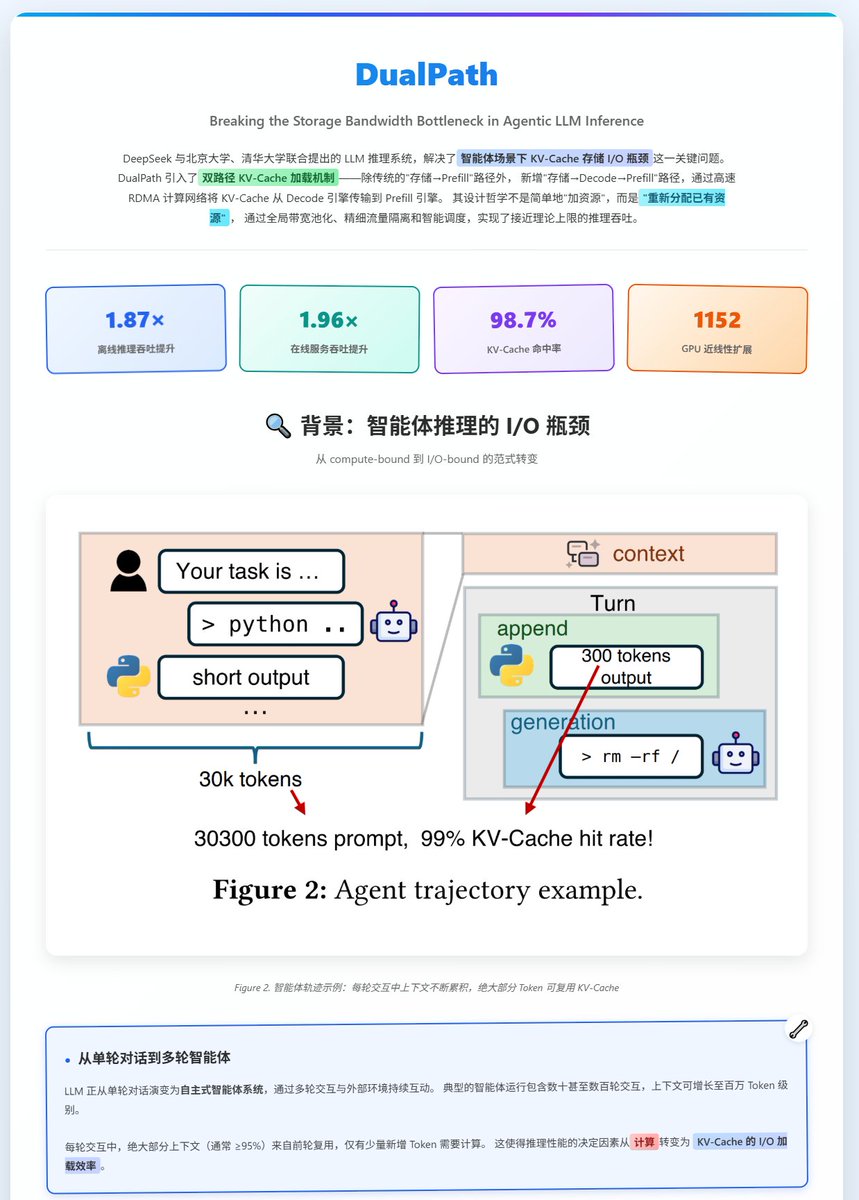
DeepSeek 又发新论文啦!给大家带来解读。说实话这次的论文我看完了心里挺不是滋味
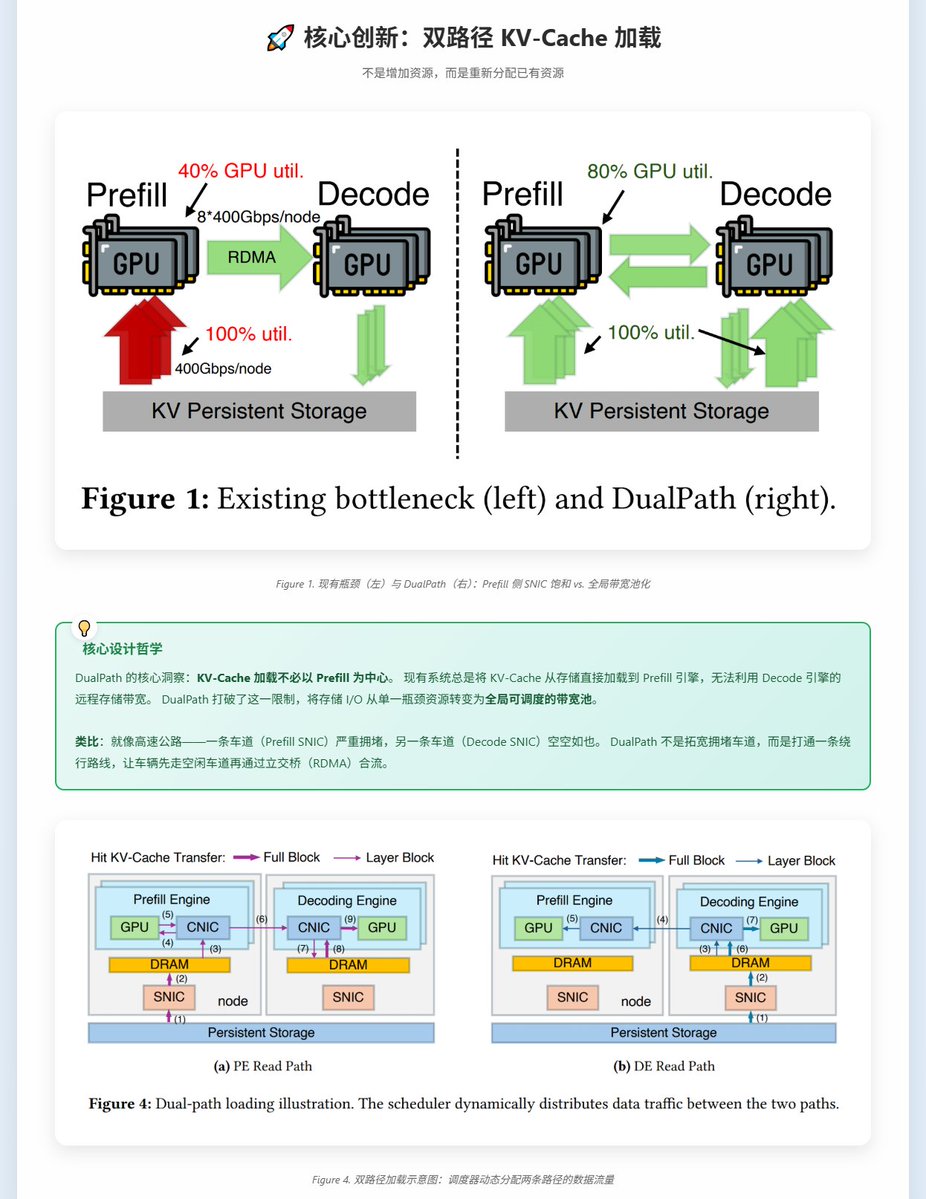
DeepSeek 联合北大、清华发了一篇新论文 DualPath, 解决了一个很多人可能没意识到的问题: 在 Agent 场景下, GPU 大部分时间不是在算, 而是在等数据从硬盘搬过来.
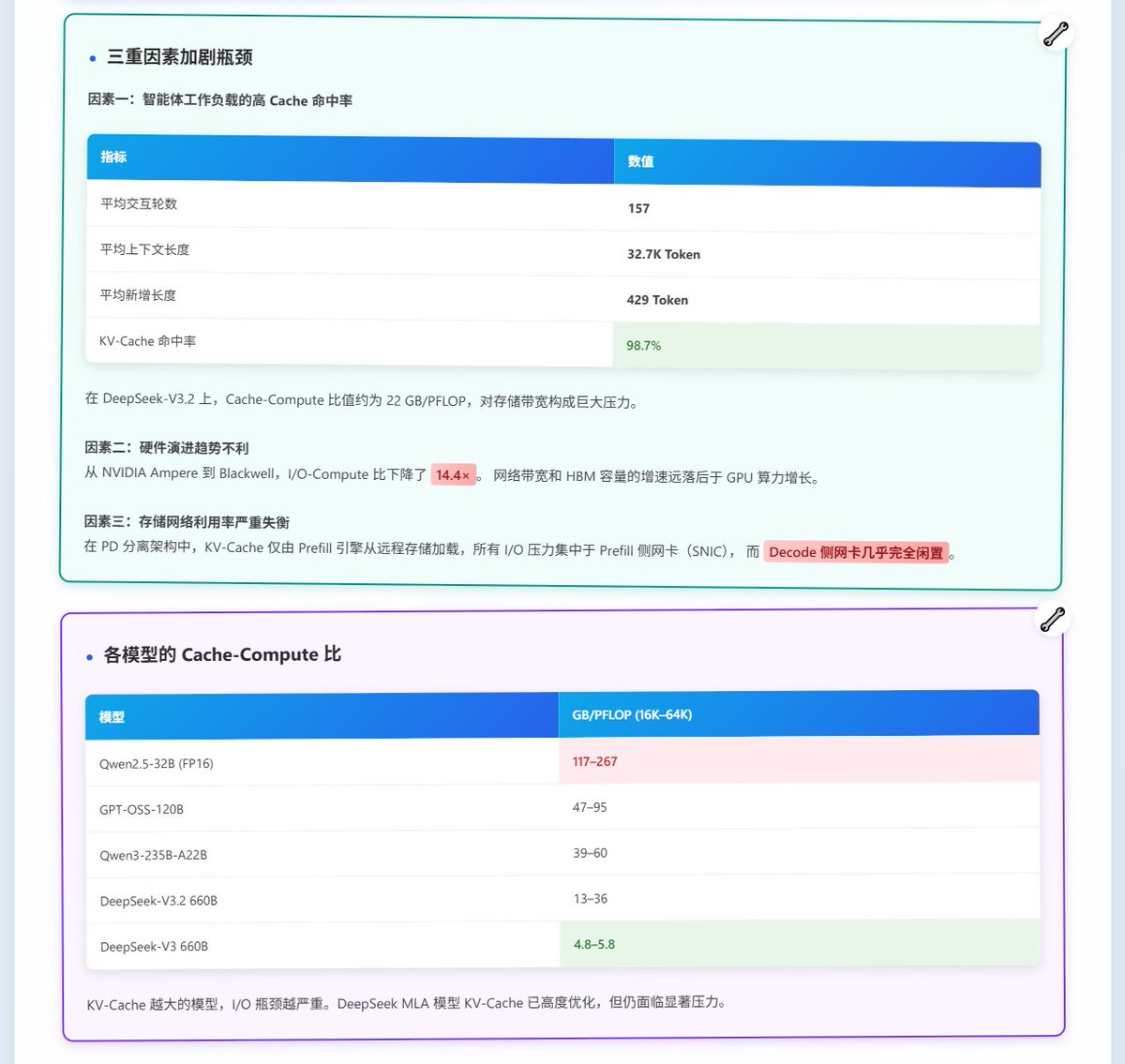
先说背景. 大家都知道现在 AI Agent 任务火爆. 问题是: 每一轮上下文的 95%以上都是之前轮次的"旧数据" (KV-Cache), 只有一丁点是新的. GPU 其实没多少活要干, 但它得等着把之前的 KV-Cache 从存储里读出来才能开工.
现在主流的推理架构是 Prefill-Decode 分离 (PD分离), Prefill 引擎负责理解输入, Decode 引擎负责生成输出. 在这种架构下, 所有的 KV-Cache 都只能从存储加载到 Prefill 引擎, Prefill 侧的存储网卡(只有400G带宽)被挤爆了. 那咋办? 加网卡吗? 且慢, Decode 侧也有存储网卡, 这个卡在Prefill阶段是在摸鱼的! 所以得想办法利用起来!
DualPath 的核心思路是: 既然 Prefill 侧堵死了, 而 Decode 侧空着, 那为什么不让数据也走 Decode 侧, 再通过 GPU 间的高速计算网络(这个IB网络带宽足足有3.2T) 传输回 Prefill 机器.
说实话在我来看这是个脏优化, 不符合架构直觉, 有点类似家里要炖汤, 结果汤锅装不下, 只能用炒勺也炖, 等汤锅闲下来了再把炒勺的转移到汤锅里. 也算是无奈之举了.
所以带来的问题是: 显卡间的IB计算网络上还跑着模型推理的集合通信呢! 这些对延迟极其敏感. 你要是 KV-Cache 搬运把计算网络堵了, 那推理性能反而会更差.
DualPath 的解决方案是: 所有进出 GPU 的流量全部走计算网卡, 利用 InfiniBand 的虚拟通道做流量隔离, 推理通信走高优先级通道, 独占 99% 带宽保障; KV-Cache 搬运走低优先级通道, 只捡空闲带宽用. 搞过网络 QoS 的同学应该能 get 到这个设计.
收益是:
离线推理吞吐最高提升 1.87x, 在线服务吞吐平均提升 1.96x
所以真的, 我觉得多给DeepSeek点显卡吧, 搞这种优化真的是无奈之举, 大家都在期待你们搞模型上的创新.
在线阅读地址:swim.kcores.com/DualPath%20Bre…
往期合集:github.com/karminski/teac…

中文
@simpletrouble6 @wangwatchworld 看了一眼这几个人里你思维最正常。劝你一句少看这种财经老登的垃圾分析,我从深度学习转做量化这些年见多了金融业里这种老登了,这老登这辈子赚的钱也没我一年赚得多,看他的你算是完了。
中文

@ChinaMacroFacts 很明显OpenAI是这次人类有史以来最大的工业革命中最重要的开创者之一,但是具体作为一家公司它将来商业上能不能为投资者赚取符合预期的回报其实是另一件事,这并不好说🤔
中文
我始终认为,在一家一年内连续创造人类历史第一大和第二大的单笔权益融资的未上市公司面前,展现一些“浅薄的连ai水平都不及的独立思考后的对泡沫的质疑”,是一种非常愚蠢的表现。
Sam Altman@sama
We have raised a $110 billion round of funding from Amazon, NVIDIA, and SoftBank. We are grateful for the support from our partners, and have a lot of work to do to bring you the tools you deserve.
中文
@simpletrouble6 @wangwatchworld 另外噢,人类有史以来最大的工业革命开始了,只有中美两国有上桌的能力,我真是难以理解为什么要吹捧日本的国民性🤣 有这功夫不如研究研究自己怎么不被AI淘汰吧
中文

@keanu35841687 @111_114390 训练还离不开nvidia,但是推理已经可以大规模国产化了。实际上随着应用的铺开,推理算力可能才是大头。这对nvidia总体来说还是很不利的。
中文

